The idea that bats could be responsible for the transmission of newly emerging and potentially deadly infectious diseases to humans began to take hold in 2002 with the discovery of a new coronavirus that caused severe respiratory infections called SARS. Coronaviruses are widespread in animals, from birds to whales, and are the cause of common colds, but SARS was different, with the 2002 outbreak killing 800 people and generating frightening headlines worldwide.
Three years later, an article in Science titled “Bats Are Natural Reservoirs of SARS-like Coronaviruses” announced the emerging scientific wisdom that bats were a global public health menace. Since that time, so-called virus hunters have pursued an intense international search for dangerous viruses in bats, and sensationalist media attention continues to accompany this search. “Hordes of deadly diseases are lurking in bats and sometimes jumping to people,” New Scientist reported in February 2014, asking, “Can we prevent a major pandemic?” Several months later Wired piled on with an article titled “Why Bats Are Such Good Hosts for Ebola and Other Deadly Diseases,” which asserted that “scientists are discovering new bat-borne viruses all the time.” Such stories continue to this day; a February 2017 National Public Radio report called “Why Killer Viruses Are On The Rise” portrays bats as “arguably one of the most dangerous animals in the world,” and warns that “when there are bats up in the sky, there could be Ebola in that poop that lands on your shoulder.”
Yet once one delves into the world of bats and infectious diseases, these stories begin to fall apart. A closer look at what science knows about bats strongly suggests that the scientific and media furor is at best overstated, and is likely a distraction from more serious research and health problems. Above all, it turns out that while we certainly should be concerned about bats, we probably don’t need to worry very much about what they might do to us. Rather, we should be worrying about what we are doing to bats in the name of science and public health.
Assume a bat
To start with, SARS and many other “emerging infectious diseases,” such as Hendra, Nipa, Marburg, Ebola, and MERS, are not new diseases. They’ve been around for millions of years, but due to their rarity and geographic isolation have only recently been noticed by scientists, the media, and the public. Moreover, despite the intensity of scientific and media attention over the past 20 years, these diseases have together, worldwide, accounted for fewer than 1,000 human deaths annually, a miniscule proportion of the toll from diseases such as malaria, tuberculosis, and AIDS.
The Ebola story is typical. A viral disease that is often fatal to humans and other primates in tropical regions of sub-Saharan Africa, Ebola is very old, probably present in Africa for millions of years. First detected in 1976, Ebola was responsible for just 1,090 reported human deaths prior to a virulent outbreak in West Africa that started in late 2013. Unlike previous Ebola outbreaks, this one was spread by infected people into an impoverished, densely populated area of unusual susceptibility and minimal health care, where it caused 11,325 deaths.
The idea that bats could cause Ebola in humans was widespread even prior to this outbreak. As early as 2005, Nature published a news article titled “Fruit bats as reservoirs of Ebola virus,” followed by another in 2011 titled “West Africans at risk from bat epidemics.” By 2014, Science joined in, asking, “Are Bats Spreading Ebola Across Sub-Saharan Africa?” Meanwhile, an August 2014 National Institutes of Health news release reported that the West African outbreak had been traced back to a two-year-old boy who probably had been infected by contact with a straw-colored fruit bat (Eidolon helvum). This leap of faith was made despite no finding of Ebola virus in any local bats, no deaths among villagers who had hunted and eaten bats, and no explanation of how a toddler could have been infected by a bat that has a three-foot wingspan and never enters buildings. Nevertheless, news headlines worldwide reported that the Ebola outbreak originated with fruit bats.
Four months later, a 30-author EMBO Molecular Medicine article titled “Investigating the zoonotic origin of the West African Ebola epidemic” reported that the culprit wasn’t a fruit bat after all. Rather, “the index case [the toddler, that is] may have been infected by playing in a hollow tree housing a colony of insectivorous free-tailed bats (Mops condylurus).” BBC News, CNN, and numerous other media outlets around the world dutifully reported on this latest version of the deadly bat story.
The fruit bat had been exonerated because researchers concluded that the boy had no known contact with fruit bats or with anyone else who might have had such contact. But the evidence against the free-tailed bats was also slim. No Ebola virus was found in these or any of a dozen other bat species examined in the area. In fact, free-tailed bats from the hollow tree where the toddler was purportedly exposed had been routinely captured, roasted, and eaten by village boys, none of whom had become sick. And although the EMBO paper warned against killing bats because of “crucial ecosystem services with direct and invaluable benefits to humans,” the hollow tree where the bats lived was burned by villagers with the bats inside.
Guilty until proven innocent
If bats were even remotely as dangerous as postulated, why has it not been possible to explain the following facts? Why is it that I and hundreds of other bat researchers remain in good health, despite countless hours of close contact, often surrounded by thousands, even millions of bats in caves? Like veterinarians, we are vaccinated against rabies because we are sometimes bitten in self-defense by the animals we handle. However, throughout most of our careers, we have not been protected against any of the other deadly diseases for which bats are now speculated to serve as reservoirs.
Furthermore, why hasn’t it been possible to document bat-caused disease outbreaks among the millions of people who regularly eat bats throughout the African and Asian tropics or among the many Africans, Asians, and Australians living in cities cohabited by hundreds of thousands of bats? Why are guano harvesters who spend most of their lives in major bat caves no less healthy than their neighbors? How is it that millions of tourists have safely viewed from close range the emergence during summer nights of the million-plus bats that have lived for the past 35 years under a road bridge in the middle of Austin, Texas?
For much of human history we shared caves, then thatched huts and log cabins, with bats. For the past hundred years, the trend has been reversed. Bat populations have declined and modern humans have begun living in buildings that exclude bats. Given our long history of close association, it stands to reason that we would have evolved extraordinary resistance to each other’s diseases. Perhaps that explains why it has been so difficult to credibly document bats as sources of deadly diseases in humans.
In focusing on bats as the cause of SARS and Ebola, scientists started out by ignoring these commonsense observations, as well as historic facts demonstrating bats to be far safer than even our beloved dogs. Unfortunately, negative results are rarely published in leading journals, and they are unlikely to attract either major grants or sensationalist media attention. Instead, small samples have been mined for spurious correlations in support of powerful pre-existing biases, while researchers ignored evidence that pointed in the opposite direction. And as hundreds of millions of dollars became available for research on emerging viruses, the widely shared belief that bats were the culprit continued to fuel scientific attention.
But despite a decade of headlined speculation and an intensive search for an Ebola reservoir, focused primarily on tracing it to bats, the evidence against bats remains scant. The Ebolavirus genus includes five species (Sudan, Zaire, Bundibugyo, Tai Forest, and Reston virus), and the geographical distribution of these species along separate river basins is inconsistent with a highly mobile source. Bats would not be restricted to single river basins.
Repeated attempts to isolate infectious Ebola viruses from a wide variety of fruit- and insect-eating bats caught at outbreak locations have failed. Some serologic surveys have found evidence of exposure, but complete viral genomes—the gold standard—have not been obtained. Though bats have been artificially infected in lab experiments and remained unharmed, they have showed no evidence of viral shedding, nor has anyone successfully infected another animal with Ebola via a bat. In fact, the initially blamed straw-colored fruit bat has been found so resistant as to be an unlikely host.
Some scientists have begun calling for a much broader research focus. In a 2016 editorial in the journal Viruses, epidemiologist Fabian Leendertz argued that although terrestrial animals are normally presumed to be the virus hosts, rivers have their own flora and fauna, and aquatic or semiaquatic animals could provide important links to Ebola that scientists have thus far ignored. Even nonbiting insects such as mayflies could be involved, perhaps being accidentally ingested by susceptible herbivores feeding during periodic hatches. And a January 2016 Nature article reported that Jens Kuhn, a virologist at the National Institutes of Health’s Institute of Allergy and Infectious Diseases, “thinks that bats are far too abundant and too closely associated with humans to explain an infection that has emerged just two dozen times over the past four decades.” He speculated that an unsuspected host, possibly even arthropods or fungi, could be the culprit. The same report further notes that the US Agency for International Development now plans a two-year survey of the Ebola virus-transmitting potential of a widening range of animals, including rodents, livestock, dogs, and cats. Indeed, dogs have been suspected carriers of emerging viruses since 2005, but appear to have been largely ignored by researchers. Until recently, so had camels.
What hump?
First detected in Saudi Arabia in 2012, Middle East respiratory syndrome (MERS) is an illness caused by a SARS-like coronavirus. By the end of 2015, MERS had caused more than 587 deaths, 75% of them in the Middle East. It has spread to Asia, Europe, and North America, but, like Ebola, has been quickly controlled.
Due to prior speculation linking bats to the SARS outbreak, bats were initially assumed to be the source of MERS as well. When a single small fragment of a coronavirus, speculated to be closely related to the one causing MERS, was found in a bat fecal pellet, the online news site of the journal Science (August 22, 2013) and the news section of the journal Nature (August 23, 2013) rushed to blame the disease on bats. Their headlines seemed more appropriate for supermarket tabloids: “Bat Out of Hell? Egyptian Tomb Bat May Harbor MERS Virus” and “Deadly coronavirus found in bats.”
But how significant was the discovery of a single small viral fragment in a bat fecal pellet? As it turned out, the tiny (182-nucleotide-long) viral snippet was not only short, but it also came from one of the least variable parts of the viral genome. Thus, the full genomes of the viruses that infect bats and humans could still vary significantly. Also, since the fragment came from a fecal pellet, it might have indicated only that the bat had eaten an insect that had fed on an infected animal. A second investigation in 2013 did not yield further corroboration, nor did subsequent intensive, multicountry searches. Instead, as covered in multiple 2016 reviews, most notably a paper by Mohd and colleagues in Virology Journal, a new story began to emerge.
First, nasal swabs from a patient who died of MERS provided a full genome sequence of the virus that was identical to a virus found in swabs taken from his pet camels, and serologic data indicated that the virus was circulating in his camels prior to the patient’s infection. Even though there was now seemingly irrefutable evidence linking MERS transmission from camels to humans, the source for humans was hotly debated. Skeptics pointed out that most primary cases of human infection appeared to have no contact with camels or other animals.
However, a series of studies began to show that the MERS-causing coronavirus was endemic and widespread in dromedary camels of East Africa and the Middle East. The Agriculture Ministry of Saudi Arabia reported that 85% of dromedary camels carried it, and 100% of retired racing camels from Spain had MERS antibodies. It was even found in long-isolated camels living on the Canary Islands. Additional studies showed significantly higher prevalence of antibodies in individuals exposed to camels. For example, four of five dedicated camel slaughterers were seropositive at a location where 59% of the camels were positive. On the flip side of the coin, no study found live MERS virus in any other animals.
The large proportion of people who contracted MERS without known exposure to camels finally was traced to likely consumption of raw milk or organ meat from camels, considered by some to be delicacies. Milk easily could be contaminated through unsanitary conditions.
Studies of stored sera suggest that the MERS-causing coronavirus has been present in camels for at least several decades, and a nationwide study in Saudi Arabia found widespread circulation of different genetic variants in camels that were closely associated with the virus found in humans. Overwhelming evidence now points to dromedary camels as the primary reservoir of the MERS virus and the only source of MERS infection for humans. Camels shed live virus with no clinical signs of infection, and there is clear documentation of direct transmission to humans. Yet speculation about bats in the distant past continues. RNA fragments from coronaviruses, reported to be closely related to the one causing MERS, have been recovered from fecal pellets of several species of bats in Ghana and in four European countries, but no MERS infections are known in either humans or domestic animals in those areas.
Overall, documentation of bat origins for emerging infectious diseases is mostly weak to nonexistent. Nonetheless, the scientific search for these diseases in bats continues. I have examined some 4,000 research papers on Ebola and MERS alone and found that studies of disease reservoirs focus disproportionately on bats, even when evidence of a connection to human disease is lacking. For example, by 2014 the link between dromedaries and MERS was well established, but two years later publications mentioning bats as reservoirs for MERS still considerably outnumbered papers on camel reservoirs (by about 340 to 240).
Viruses, viruses everywhere
New viruses are being found wherever scientists look for them. In one recent study, hundreds of previously undescribed viruses were found in a single human. Yet when a new one is discovered in bats, scientists and the science media often speculate about its potential as a dangerous source of future pandemic disease outbreaks, not to mention the possibility of being related to common diseases such as flu, hepatitis, or herpes.
A 2016 paper in PLOS ONE by Young and Olival says that “the life history traits of bats compared to other mammals may make them unique and exceptional hosts for viruses.” But in reality, we know very little about viral relationships overall. A February 2015 review by Moratelli and Calisher acknowledges that “the supposed connections between bats, bat viruses and human diseases have been raised more on speculation than on evidence supporting their direct or indirect roles in the epidemiology of diseases.” Key animal experiments to test how primates can be infected by bats have yet to be conducted.
In my view, the knowledge base about emerging infectious diseases is extraordinarily biased by scientists’ obsession with bats. This bias is encouraged by an additional, highly practical factor: there is no group of mammals easier to sample quickly or in large numbers than bats. Bats may love the dark, but they are all too easy to put under the spotlight of scientific scrutiny. I know from experience, having invented the trap now used by virologists to sample bats and having collected thousands of mammals, from jaguars and tapirs to rodents and bats, for the Smithsonian. Imagine the difference in time required to obtain significant samples of carnivores, primates, or ungulates versus bats that can be trapped, hundreds at a time, as they emerge from colonial roosts. Even rodents are typically far more difficult to capture. In the hyper-competitive world of academic science, it’s easier and cheaper to do research on viruses in bats than in most other species, and so that’s the research that gets done. It’s also more in tune with a culture that has long portrayed bats as objects of mystery and fear.
Certainly bats may serve as reservoirs for some “emerging” viruses. Live Nipah virus has been found in clinically healthy flying foxes in Bangladesh, Malaysia, and adjacent areas, and Hendra virus has similarly been isolated in Australia. Also, in equatorial Africa, close genomic matches have been demonstrated in Marburg viruses from infected bats and humans.
But Nipah appears to have been virtually eliminated as a significant public health threat by simply warning people not to raise pigs (which serve as intermediate hosts) beneath fruit trees that attract flying foxes, and by warning them not to drink raw date palm juice potentially contaminated by bats. Hendra is not directly transmitted from bats to humans, but periodically does infect horses, which have fatally infected four humans since the virus’s discovery in 1994. Marburg has caused 373 human deaths since its discovery in African green monkeys in 1967, and there may be multiple animal reservoirs. Transmission from bats is rare and can be avoided entirely by not entering caves or handling bats where the disease occurs. As reported by the World Health Organization and the US Centers for Disease Control and Prevention, these three viruses combined have caused fewer than 600 human deaths in the past 20 years. They are less than trivial public health threats.
In most of the world, including in the United States and Canada, rabies is the only threat from bats. This normally fatal disease has been recognized for over 2,000 years. Transmission from bats is exceedingly rare—just one or two human fatalities per year in the United States and Canada, and even fewer in most of the rest of the world except for Latin America, where vampire bats occasionally bite humans who sleep in the open without mosquito nets. Worldwide, more than 50,000 people die annually from rabies, 99% of them having received the virus from dogs, our best friend.
Stop the bias against bats
In total, the evidence that bats are the source of emerging viral diseases is weak. The human toll of those diseases is minor relative to other infectious diseases, and public health measures to protect against any limited health threat from bats are simple, cheap, and proven.
At the same time, there is rapidly growing documentation that bats are worth billions of dollars annually to human economies and that their loss can threaten the health of whole ecosystems upon which we depend. And as demonstrated in my home town of Austin, where 1.5 million Brazilian free-tailed bats (Tadarida brasiliensis) have been protected for decades, they can make safe and invaluable neighbors once we simply learn to leave them alone. Our local bats consume tons of crop and yard pests nightly and attract millions of tourist dollars each summer.
Continued scientific and media bias focused on potential diseases from bats is unlikely to protect human health. But it is contributing to misallocation of scientific resources, to the acquisition of knowledge of dubious value for society, and to inappropriate public health priorities. Perhaps most damaging of all, the ongoing demonization of bats is contributing to their destruction. I have personally visited caves where thousands to millions of bats were killed because of fear that was exacerbated by scientific fad and media hype involving disease. One of my primary research caves in Tennessee was burned when public health researchers warned the owner that his bats might be rabid.
People who believe bats to be spreaders of a seemingly endless list of the world’s most frightening diseases are unlikely to tolerate them in their neighborhoods. Due to premature speculation by scientists competing for grants, decades of conservation progress on bats is now in jeopardy. At a time when our future is threatened by loss of biodiversity, and budgets for health care are stretched to the limit, how can we justify continued disproportionate investment in a hunt for rare viruses in bats?
I don’t believe virologists intend to harm bats. In fact, even when publishing their most frightening hypotheses linking bats to diseases, scientists typically mention the ecological value of bats and urge that they not be killed. They blame the possibility of new pandemics on human expansion into bat habitats, implying the problems are human-caused. As one who has devoted more than 50 years to studying and conserving bats, I do appreciate such sentiments. Nevertheless, available evidence suggests that bat-human contact is decreasing rather than increasing. And for anyone who doesn’t directly handle bats, risk of disease is incalculably remote.
Long after it should have ended, the biased search for deadly viruses in bats appears to have become self-perpetuating, fueled by new viral discoveries, many of which would likely be made in any species that scientists choose to study. Bats are indeed unique. They play an extremely important role in ecosystems worldwide, and contribute to human well-being. But because they form large, conspicuous aggregations, yet typically rear just one young per year, bats are especially vulnerable to mass killing and extinction. It’s time for researchers to better document what bats do for us instead of stoking fears about the remote possibility that bats might cause future pandemics. Our real fear should be the further decline of bats.
Toward a Responsible Solar Geoengineering Research Program
A combination of greenhouse-gas emission cuts and solar geoengineering could keep temperatures under the 1.5-degree aspirational target of the recent Paris Agreement. It could make the world cooler at the century’s end than it is today. Emissions cuts alone cannot achieve either objective with high confidence. The climate’s inertia along with uncertain feedbacks such as loss of permafrost carbon mean there is a small but significant chance that the world will continue to warm for more than a century after emissions stop.
Solar geoengineering is the process by which humans might deliberately reduce the effect of heat-trapping greenhouses gases, particularly carbon dioxide, by reflecting a small fraction of sunlight back to space. The most plausible solar geoengineering technology appears to be the addition of aerosols (fine droplets or powder) to the stratosphere, where they would scatter some sunlight back to space, thus cooling the planet by reducing the amount of heat that enters the atmosphere.
Solar geoengineering could also limit global warming’s predicted side effects such as sea level rise and changes in precipitation and other weather patterns. Because these changes would have their most powerful impact on the world’s most vulnerable people, who lack the resources to move or adapt, one can make a strong ethical case for research to explore the technology.
Climate risks such as warming, extreme storms, and rising seas increase with cumulative emissions of carbon dioxide. Solar geoengineering may temporarily reduce such climate risks, but no matter how well it works it cannot eliminate all the risk arising from the growing burden of long-lived greenhouse gases. We can draw three important conclusions from these two facts. First, net emissions must eventually be reduced to zero to limit climate risk. Second, eliminating emissions does not eliminate climate risks, because it does nothing to address emissions already in the atmosphere. Third, the combination of solar geoengineering and emissions cuts may limit risks in ways that cannot be achieved by emissions cuts alone.
Solar geoengineering is not a substitute for cutting emissions. It is—at best—a supplement. We can’t keep using the atmosphere as a free waste dump for carbon and expect to have a safe climate no matter what we do to reflect away some sunlight.
The potential benefits of solar geoengineering warrant a large-scale international research effort. Economists have estimated that global climate change could result in worldwide economic damage of more than a trillion dollars per year later this century. A geoengineering project large enough to cut the economic damage in half could be implemented at a cost of a few billion dollars per year, several hundred times less than the economic damage it would prevent. Furthermore, a modest research effort can yield rapid progress because the technological development of solar geoengineering would be largely an exercise in the application of existing tools from aerosol science, atmospheric science, climate research, and applied aerospace engineering. Of course, any exploration of geoengineering would also have to consider how its deployment would be governed, and governance research can build on decades of climate policy work across fields as diverse as economics, international law, environmental ethics, and risk perception.
Yet despite this promise, there is very little organized research on the topic, and there is no US government research program.
For much of the past few decades the topic has been taboo in climate research and policy. This is surprising when one considers its history. What is now called solar geoengineering was—remarkably—in the very first report on climate change to a US president, which reached President Lyndon Johnson’s desk in 1965. Over the next few decades the topic was covered in major reports on climate change, including the US National Research Council (NRC) reports of 1977, 1983, and 1992. But as climate change reached the top of the environmental agenda with the 1992 Rio Framework Convention and the formation of the Intergovernmental Panel on Climate Change, discussion of solar geoengineering went quiet.
However, there are now signs of rapid change in the politics of solar geoengineering. Perhaps most important, Janos Pasztor, who served as senior climate adviser to UN Secretary General Ban Ki-Moon, is now leading the Carnegie Climate Geoengineering Governance Initiative, a major effort to develop international governance for climate engineering. There are also modest research programs in Europe and China. Over the past few years, environmental advocacy groups such as the Environmental Defense Fund and the Natural Resources Defense Council have released formal statements supporting research. In 2015, the NRC released a report on geoengineering, recommending a broad research effort. Most recently, in January 2017, President Obama’s US Global Change Research Program (USGCRP), a coordinating body administered by the White House’s Office of Science and Technology Policy, explicitly recommended research.
With these changes in the political environment, the time is right for launching a substantial international research program on solar geoengineering, one that has strong norms of transparency and open access and that embeds solar geoengineering inside global debates about climate governance. How might a responsible US government research program be constructed as part of this effort? Does the arrival of the Trump administration change the picture?
Reasons for reluctance
Before examining how a research program might be established, much can be learned from reviewing the deep concerns that have held back previous efforts: uncertainty, slippery slope, messing with nature, governability, and moral hazard.
Uncertainty. The central purpose of research is to reduce uncertainty; so although there is much that we don’t know about solar geoengineering, that cannot stand alone as an argument against research. A related argument is that because of the uncertainty inherent in predictions about the climate’s response to solar geoengineering, it cannot be meaningfully tested short of full-scale deployment. But this argument fails to address the uncertainty on both sides of a hypothetical decision to (gradually) deploy solar geoengineering.
The term of art for the human force driving climate change is radiative forcing (RF), the heat energy added to the atmosphere measured in watts per square meter (W/m2). Accumulated greenhouse gases produce a positive radiative forcing, whereas solar geoengineering produces a negative forcing. These RFs can be known with some confidence. The deep uncertainties lie in predicting the climate’s response to the forcing; the higher it is, the more uncertain and dangerous things become, but we don’t know exactly how the climate dice will roll.
As a concrete example, assume that emissions can be cut to near zero soon after mid-century, yielding a peak RF of 4 W/m2 in 2075. Suppose deployment of solar geoengineering starts in 2030 and is gradually increased to produce an RF of -1 W/m2 in 2075 and then slowly reduced thereafter as greenhouse gas concentrations decline. The central question is, which version of 2075 is more dangerous? A world with 4 W/m2 of RF from greenhouse gases or a world with a net RF of 3 W/m2 but with additional risks from solar geoengineering. No one knows. Uncertainty is baked into either path. But a reasonable first guess is that because RF is the central driver of climate change, there is less climate risk in the world with less RF. Uncertainty is real, but it speaks louder as an argument for rather than against research.
Slippery slope. If the slope from research to deployment is slippery because research reveals that solar geoengineering works better and with less risk than we now expect, that slipperiness is not itself an argument against research. The basis for concern about slippery slopes is the socio-technical lock-in that arises when technologies coevolve interdependencies with other technologies and when they develop political constituencies that encourage continued use even against the public interest. This is a legitimate concern for many technologies, from cars to Facebook. All else equal, socio-technical lock-in is a particular concern for technologies that drive profitable businesses or that require structural changes that are difficult to abandon.
Solar geoengineering seems unlikely to generate strong lock-in because it appears to have very low direct cost, a fact that poses deep challenges for governance but likely reduces the chance of a substantial concentration of economic power. If it’s true, as some estimates suggest, that the direct cost of large-scale implementation would be a few billion dollars per year, then it will be hard to develop concentrated economic power. Moreover, there is no obvious way to collect a fee for the reduction in climate risk because the benefits to solar geoengineering are, in a useful piece of economic jargon, “non-excludable.” It therefore seems likely that the deployment would be structured as some form of fee-for-service contract to governments. Moreover, because the technology is primarily an application of existing aerosol science and aerospace engineering with little apparent basis for strong intellectual property claims, governments could likely procure deployment services from many vendors. This combination of factors suggests that concerns about socio-technical lock-in seem relatively small.
Messing with nature. In The End of Nature, Bill McKibben argues that carbon dioxide-driven climate change makes climate itself a human artifact rather than a natural process and thereby eliminates the capital “N” of Nature. Use of solar geoengineering would indeed cement the climate’s status as a deliberate product of political decisions. Yet the move by humanity to take deliberate responsibility for managing the climate should, I think, be seen a progressive step, a step beyond the sharp dichotomy between “Civilization” and “Nature” (itself a particularly North American nineteenth-century view) and toward a stance of deliberate responsibility. Disagreement about the environmental ethics of solar geoengineering arise, in part, from two alternate views of the same action. If solar geoengineering reduces the climate and ecological effects of accumulated carbon dioxide, is its implementation a step toward cleaning up our mess in a process of ecological management at planetary scale? Or is it yet another step toward the subjugation of nature for human ends? Which analogy fits best: reintroducing wolves to Yellowstone? Restoration of the Florida Everglades in arguably the world’s largest and most costly environmental engineering effort? Reviving wooly mammoths? Or is geoengineering more akin to indoor ski slopes in Dubai, the creation of artificial environments to suit human whims?
The combination of emissions cuts, solar geoengineering, and negative emissions gives humanity the ability to (roughly) restore preindustrial climate. Such deliberate restorative planetary management would take centuries, but I see it as a worthy organizing goal for environmental advocacy—a goal that cannot be achieved by emissions cuts alone, even an immediate elimination of emissions.
Governability. How is it possible to govern a technology for which unilateral action is easy? One for which costs and benefits are uncertain and globally distributed? One for which it’s hard to confidently attribute a specific impact such as a hurricane or drought to the intervention? How can governance of geoengineering accord with the ideal that decision makers consult with people whose lives will be affected? Some theorists have concluded that no governance system can meet all the criteria. A fair argument, but a claim that perfect governance is impossible does not amount to a proof that no system of governance is practical. The empirical challenge for these claims is that the arguments apply with equal or greater force to technologies for which there is, in practice, some level of functioning, though imperfect, global governance.
Suppose a technology were invented that allowed significant control over the economy to be exercised rapidly by a single small committee in each major country. Suppose further that the impacts of these committee decisions were unpredictable and that there were strong nonlinearities that interconnected the effects of committee decisions in different countries, so that a single decision by the US committee could throw people out of work in Bolivia. This technology exists in the monetary policy of central banks. Yet despite the challenges, there is some governance of global central banking, and perhaps evidence that bankers are better at managing business cycles than they were in the first half of the twentieth century. Similar arguments could be made about the Internet, infectious diseases, or global air traffic control. All of these involve high-consequence systems with significant uncertainty. In no case is management perfect, but it is by no means obvious that these examples are inherently more difficult than governing solar geoengineering. Indeed, if it is true, as current research suggests, that the benefits and risks of solar geoengineering would be distributed relatively evenly around the globe, then governance of solar geoengineering may be easier than for other high-consequence global technologies. Moreover, if solar geoengineering is a form of public good, albeit one with a higher level of uncertainty and risk than many, it’s a public good for which the political challenge of agreeing about who pays is relatively small because the costs are relatively small.
Moral hazard. Perhaps the most salient concern is that by making geoengineering seem more plausible, an active research program in this area will weaken efforts to control emissions. The fear is that opponents of climate action will make exaggerated claims about the effectiveness of solar geoengineering, using them as a rhetorical tool to oppose emissions cuts. Although there is little evidence of this today, I share this fear. Indeed, writing in 2000, I may have been the first to highlight this dynamic as the moral hazard of geoengineering.
Political conflict over climate policy is long-standing. It’s reasonable to expect that all available arguments will be deployed in political battle. In evaluating concern about geoengineering’s moral hazard the question is not whether the technology will be over-hyped to argue against climate action? But rather, how much might this argument alter the political balance of power? There are reasons to suspect the impact may be small. The power of the environmental advocacy forces that fight for climate action will not evaporate if research makes solar geoengineering more visible any more than the power of the fossil-fuel lobby evaporated in the face of record temperatures.
The ideal structure would be a red-team/blue-team approach in which some groups work to develop systems engineering approaches and best-case deployment scenarios while most of the effort is spent in independent research clusters searching for risks and failure modes.
The impact of geoengineering as a rhetorical tool against climate action may be smaller than feared because it can serve both sides of the climate policy battle. The very existence of solar geoengineering, along with its uncertainties and risks, can serve as a powerful argument in favor of accelerated action on emissions. The effectiveness of these arguments will depend on how knowledge of solar geoengineering alters people’s perception of climate risks. The common assumption is that concern for climate risk as measured by an individual’s willingness to pay for emissions cuts will be reduced. But learning about solar geoengineering may increase the salience of climate risks and thereby increase one’s commitment to reduce emissions. One might imagine two extreme reactions to solar geoengineering: Great! A technofix! Now I can buy a big truck and ignore the environmental extremists. Or, conversely: Damn! If scientists want to spray sulfuric acid in the stratosphere as a last-ditch protection from heat waves, then climate change is scarier than I thought. I should pony up and pay more for an electric car. We cannot know yet which response would prevail, but experimental social scientists have begun to explore public reaction to solar geoengineering, and results from all experiments to date suggest that the latter reaction dominates: information about solar geoengineering increases willingness to pay for emission mitigation.
Each of the concerns described above has merit. One must weight them, however, against the evidence that solar geoengineering could avert harm to some of the world’s most vulnerable people. These concerns do suggest some specific ways in which research programs might be managed to minimize risks; they do not, individually or collectively, amount to a strong argument against research.
Program design
Guidance for establishing a US research program on solar geoengineering is available from the 2017 US Global Change Research Program report, the 2015 National Research Council report Climate Intervention: Reflecting Sunlight to Cool Earth, and a 2011 report from the Bipartisan Policy Center’s Task Force on Climate Remediation Research, to cite a few prominent examples. I do not attempt to describe a research program here, but rather suggest a few crosscutting principles that might be useful in developing such a program in the United States or elsewhere.
Separate solar geoengineering from carbon removal. The term geoengineering is often used to describe both solar geoengineering and a group of conceptual or emerging technologies that remove carbon dioxide from the atmosphere. Solar geoengineering and carbon removal both provide a means to manage climate risks; both deserve a much greater research effort; and both are inadequately considered in climate policy analysis and debates. They are, however, wholly distinct with respect to the science and technology required to develop, test, and deploy them; their costs and environmental risks; and the challenges they pose for public policy and governance.
The sharp distinction between the two is evident in the distribution of risks and benefits. The most plausible means of solar geoengineering appear to have global risks and benefits while having minimal risk and low direct cost at the point at which they are deployed (for example, the airfield from which aircraft distributing aerosols might fly). In sharp contrast, carbon removal offers the globally distributed benefit of reduced atmospheric carbon burden but with comparatively high localized costs, and some methods pose significant environmental and social risks at the point of deployment. Ocean iron fertilization is the one form of carbon removal that shares many of the characteristics of solar geoengineering, and it’s prominence in early analysis explains much of the desire to lump solar geoengineering and carbon removal, but hopes for that technology have faded so that it is no longer prominent in discussions.
Of course, decisions about the use of solar geoengineering or carbon removal make sense only in the context of a larger analysis and debate about climate policy that includes mitigation and adaptation. Yet because these technologies have little in common, decision makers have a better chance to craft sensible policy for each if research into their effectiveness and risks is managed separately. If there is a case for unifying research and development programs, it makes more sense to combine carbon removal with emissions mitigation than to combine carbon removal with solar geoengineering.
Focus on risks. Research should be concentrated on finding ways that solar geoengineering could fail. Unknowns are perhaps the largest concern, so we need a diverse exploratory research effort to examine a wide range of low-probability, high-consequence risks or failure modes. This research effort needs to be coupled to the emerging results of the systems engineering effort (discussed next) so that effort is directed at identifying problems with methods that seem most likely to be deployed. Otherwise, effort may be wasted finding problems with solar geoengineering technologies or deployment scenarios that are so ineffective or ill-considered that they are unlikely to be deployed.
As well as searching for physical risks or limitations of good-faith deployment scenarios, research should examine plausible scenarios for normal accidents and for malicious use. These sharply divergent assumptions are all relevant, but they need to be clearly distinguished. Too much current analysis focuses on mushy middle-ground scenarios that are too suboptimal to be credible as good-faith scenarios yet do not illuminate the potential for malicious use.
Include engineering. Solar geoengineering cannot be seriously evaluated if it exists only as a grab bag of academic papers. Research examining technical and social risks requires coherent scenarios for deployment that are specified in sufficient detail to enable critical analysis. Developing such scenarios requires work that straddles the engineering science boundary and is guided by a systems engineering approach. Such an approach should start with a clear set of goals, such as reducing specific climate risks, while minimizing risks of deployment and minimizing the regional variation of climate response. Scenarios for deployment need to specify the material to be deployed, the means of deployment, and the means of monitoring the climate and ecosystem response, as well as the means of adjusting the deployment to achieve some specified goal, such as limiting the increase in precipitation or keeping global average temperatures under some threshold. Such physical and operational scenarios can serve as a basis for critical examination of physical risk and efficacy as well as for analysis of governance, including mechanisms for managing liability and for enabling collective decisions about deployment.
The 2015 NRC report recommended that geoengineering research be limited to “dual use” research that has a clear relevance to both general climate geosciences and to geoengineering. Although research on solar geoengineering must be embedded in a vigorous portfolio of atmospheric and climate-related geoscience, an overarching dual-use standard would be a poor guide for a geoengineering research program, for two reasons.
First, this criterion would rule out the kind of systems engineering analysis required to define deployment scenarios. Yet without such scenarios, analysis of geoengineering may focus on implausible scenarios, such as the all too common assumption that stratospheric sulfate aerosols would be used to offset all anthropogenic warming.
Second, there is a strong anti-correlation between research most likely to yield interesting climate science and that mostly likely to be relevant to solar geoengineering. One of the interesting new ideas for solar geoengineering is the possibility of thinning high cirrus clouds by seeding to reduce their tendency to trap the Earth’s infrared heat. Cirrus thinning works directly to counter the heat-trapping effects of greenhouse gases, so it might work better than the older idea of reflecting sunlight with stratospheric aerosols. But the technique is highly uncertain. There are many meteorological conditions under which cirrus seeding will be ineffective or even counterproductive. Field experiments with cirrus seeding could improve understanding of its potential as a geoengineering measure while also improving understanding of these clouds in ways that might be used to improve the accuracy of climate and weather models. In contrast, there is no reasonable scientific doubt that if aerosols such as sulfuric acid or calcium carbonate could be successfully introduced to the stratosphere, they would scatter sunlight back to space with a cooling tendency. Because the scattering from stratospheric aerosols is relatively well understood, there is less chance that research would yield interesting spin-offs for climate science than there would be for research on cirrus thinning.
If the dual-use recommendation of the 2015 NRC study were adopted, research might be directed away from methods with low technical risk that would be the natural focus of a systems-engineering driven program, and instead directed to methods with deeper scientific uncertainty. Some consideration of dual use makes sense, and study of cirrus thinning is certainly justified, but a science-first dual-use criterion should not drive the whole research program. Geoengineering research requires an engineering core.
Avoid centralization by encouraging research diversity. The biggest risk of solar geoengineering research is overconfidence. Research programs with strong central management tend to produce a single answer while downplaying facts that don’t fit the core narrative. This tendency can be combatted by distributing research across distinct clusters with substantial independence. It is simply not possible to work creatively to develop a technology while at the same time thinking critically about all the ways it could fail. The ideal structure would be a red-team/blue-team approach in which some groups work to develop systems engineering approaches and best-case deployment scenarios while most of the effort is spent in independent research clusters searching for risks and failure modes.
Political realities
Development of a successful and sustainable research effort on solar geoengineering is a political challenge. If solar geoengineering research is part of a coherent climate policy agenda that includes vigorous support for climate science, increases efforts to cut emissions, helps the most vulnerable to adapt, develops negative emission technologies, and renews a commitment to growing international governance, then based on the political evolution of this topic over the past half-decade there is a good chance that such a research program could have sustained support from major environmental organizations, lawmakers concerned with climate, and the public. These are big “ifs” under any circumstances, and doubly so now.
The Trump administration may make deep cuts to climate science or gut policies for climate action, or both. If so, these actions will be challenged in court, but at the very least they will introduce major uncertainty.
Consider two scenarios. Under a pessimistic scenario, a Trump administration might gut climate and related geoscience research, eliminate the USGCRP, make deep cuts to Department of Energy renewable energy programs, kill the Clean Power Plan, eliminate the federal renewable production tax credit, and withdraw from the Paris Agreement. It would be counterproductive to establish a formal federal solar geoengineering research program under this scenario because the likely result would be that forces lobbying for climate action would single out and attack research on solar geoengineering, labeling it as an excuse for inaction. This could fracture the delicate political coalition that now supports research, making it harder to sustain an effective research program even after the Trump administration is replaced by some future administration committed to climate action.
Some US-based research could continue under this pessimistic scenario, but it would be best to avoid strong links to the administration. Individual program managers in agencies such as the National Science Foundation could fund individual projects, in accord with the USGCRP recommendations. Research could also be funded by private philanthropies, particularly those with a strong track record of funding climate research and advocacy. Last, under this scenario, it would be appropriate to redouble a focus on international engagement.
The worst case would be if, under this pessimistic scenario, the Trump administration vigorously funded research on solar geoengineering, promoting it as a substitute for emissions cuts. In that case, the solar geoengineering research community’s best option might be to refuse funds and adopt a stance of active resistance.
Under an optimistic scenario, the Trump administration might appease its political base with pro-coal, anti-climate messages but would maintain the federal climate science research portfolio, even if under a different name. It would also pursue some actions on emissions mitigation. It might still gut the Clean Power Plan while increasing support for low-carbon power under the guise of a stimulus-driven push for manufacturing of renewables and electric vehicles. Under this scenario, rhetoric would be more nationalistic. There would be much less talk about climate, yet the overall effect on emissions might differ little from the current path. Under this scenario, it would be appropriate to begin development of a modest solar geoengineering research program along the lines suggested by the USGCRP report, though it would be best if the effort was decentralized and decoupled from direct high-level connections to the administration.
Two guiding principles apply in either case: First, solar geoengineering research should be embedded in a broader climate research portfolio on mitigation and adaptation action. Second, physical science and engineering research should be linked to governance and policy work. Only an integrated research program can hope to achieve the multiple objectives instrumental to making the science, policy, and politics of solar geoengineering work.
Algorithm of the Enlightenment
In 2010, two researchers at Cornell University hooked up a double pendulum system to a machine learning algorithm, instructing it to seek patterns in the seemingly random data emerging from the movements of the machine. Within minutes, the algorithm constructed its own version of Newton’s second law of motion. After hearing of their work, a biologist asked the researchers to use their software to analyze his data of a complex system of single-cell organisms. Again the system spit out a law that not only matched the data but effectively predicted what cells would do next. Except this time, while everyone agreed the equation worked, nobody understood what it meant. As early as 1976, mathematicians turned computers loose on the famous four-color map theorem, using brute force to check a huge number of possible scenarios and prove the theorem correct. Increasingly, we are using computational systems to assist us not just in the retention or management of information but in identifying patterns, comparing disparate information sources, and integrating diverse observations to create a new holistic understanding of the problem in question.
The ambition reflected in these scientific projects pales in comparison with the dreams of Silicon Valley, which hopes to render just about everything tractable by algorithm, from investing in stocks to driving a car, from eliminating genetic disorders to finding the perfect date. Thanks in large part to these enterprises, the world is now covered with a thickening layer of computation built on our smartphones, ubiquitous wireless networking, constellations of satellites, and the proliferation of cloud-based computing and storage solutions that allow anyone to tap sophisticated high-end processing power anywhere, for any problem. When we combine this technical platform for computation with the growing popularity of machine learning, it is possible to spin up a cutting-edge neural network based on open source tools from field leaders such as Google, link it to large repositories of public and private data stored on the cloud, and develop scarily effective pattern-seeking systems in a matter of hours. For example, over the course of 24 hours at a hackathon in 2016 a programmer coded a web camera, Amazon’s cloud computing, and Google’s TensorFlow machine learning tool kit to learn how to recognize San Francisco’s traffic enforcement vehicles and send him an instant message in time to move his car before getting a ticket.
In short, we are entering a new age of computational insight, one that extends beyond the self-driving Uber vehicles that are currently circling my office in Tempe, Arizona. Tools such as IBM’s Watson artificial intelligence system are not just good at Jeopardy! but also at medical diagnosis, legal analysis, actuarial work, and a range of other tasks they can be trained on for specific applications. The rising tide of automation is already affecting a tremendous range of jobs that demand intellectual judgment as well as specific physical capacities, and we’re only getting started.
Algorithms are also beginning to surprise us. Consider the trajectory of computational systems playing complex, effectively unbounded games such as chess and Go. Commentators studying the performance of the artificial intelligence system AlphaGo in its historic matches with world champion Lee Sedol often struggled to understand the system’s moves—sometimes describing them as programming failures, other times as opaque but potentially brilliant decisions. When a previous IBM system, Deep Blue, defeated world chess champion Garry Kasparov in 1997 in a six-game series, it did so in part by playing a strange, unpredictable move near the end of the first game. As Nate Silver tells it in The Signal and the Noise, that move was a bug, but Kasparov took it as a sign of unsettling depth and intelligence; it distressed him enough to throw off his play for the second game and opened the door to his ultimate defeat. We assume that the algorithm is perfectly rational and all-knowing, and that gives it an advantage over us.
This uncertainty in interpreting the performance of algorithms extends to far more nebulous cultural problems, such as the project Netflix undertook a few years ago to organize its vast catalog of films and television shows into a set of 76,897 predictable categories. The system, behaving more like something out of Futurama than a computer algorithm, demonstrated an inexplicable fondness for Perry Mason. Its chief (human) architect waxed philosophical about the implications of this output that he could not explain: “In a human world, life is made interesting by serendipity. The more complexity you add to a machine world, you’re adding serendipity that you couldn’t imagine. Perry Mason is going to happen. These ghosts in the machine are always going to be a by-product of the complexity. And sometimes we call it a bug and sometimes we call it a feature.”
Like so many other algorithmic systems, the Netflix algorithm was creating knowledge without understanding. Steven Strogatz, an applied mathematician at Cornell, has provocatively called this the “end of insight”—the era when our machines will deliver answers that we can validate but not fully comprehend. This may not seem so different from the typical doctor’s visit or lawyer’s advice today, where an ordained expert gives you a solution to a problem without giving you new insight or context. But of course you can pester that person to explain his or her thinking, and you can often learn a great deal from the emotional affect with which he or she delivers the judgment. It’s not so easy to do that with a black box machine that’s specifically designed to keep that decision-making apparatus secret. Nevertheless, this kind of intellectual outsourcing is a central function of civilization, a deferral to our tools and technologies (and experts) that happens for each of us on a daily basis. We already trust computational systems to perform a range of tasks using methods most of us do not understand, such as negotiating a secure connection to a wireless network or filtering spam e-mail. But the gap between result and analysis becomes stark, perhaps existentially so, when we are taking about scientific research itself.
The replication crises currently plaguing a number of scientific disciplines stem in part from this lack of insight. Scientists use complex computational tool kits without fully understanding them, and then make inferences based on the results that introduce various kinds of bias or false equivalencies. In 2016, for example, a team of researchers from Sweden and the United Kingdom uncovered bugs and error rates with the statistical sampling of three leading software applications used in functional magnetic resonance imaging, a technique for measuring brain activity, that may cast the findings of 40,000 research papers into doubt. A more pernicious form of this problem emerges from the fact that so much scientific work depends entirely on computational models of the universe, rather than on direct observation. In climate science, for example, we depend on models of incredibly complex air and water systems, but it is sometimes extremely difficult to disentangle the emergent complexity of the models themselves from the emergent complexity of the systems they are intended to represent.
The science fiction author Douglas Adams envisioned a magnificent reduction ad absurdum of this argument, when an advanced civilization constructs a supercomputer called Deep Thought to find the “Answer to the Ultimate Question of Life, The Universe, and Everything.” After 7.5 million years of calculation, Deep Thought returns its answer: 42. Precise but meaningless answers such as 42 or Perry Mason can easily be generated from incoherent questions.
This is an old problem. Philosophers have dreamed for centuries of what Gottfried Wilhelm von Leibniz called the mathesis universalis, a universal language built on mathematics for describing the scientific universe. He and other philosophers of the seventeenth century were laying foundation stones for the Enlightenment, imagining a future of consilient knowledge that was defined not just by a wide-ranging set of rational observations but by a rational structure for reality itself. A grammatically correct statement in the language of Leibniz would also be logically sound, mathematically true, and scientifically accurate. Fluency in that imagined tongue would make the speakers godlike masters of the space-time continuum, capable of revealing truths or perhaps even writing the world into being by formulating new phrases according to its grammatical rules.
Leibniz was among the thousands of scientists and philosophers who contributed to our modern understanding of scientific method. He imagined a set of instructions for building and extending a structure of human knowledge based on systematic observation and experimentation. According to his biographer, Maria Rosa Antognazza, Leibniz sought an “all-encompassing, systematic plan of development of the whole encyclopaedia of the sciences, to be pursued as a collaborative enterprise publicly supported by an enlightened ruler.”
I call Leibniz’s project, this recipe for the gradual accumulation and cross-validation of knowledge, the algorithm of the Enlightenment. Structured scientific inquiry is, after all, a set of high-level instructions for interpreting the universe. The ideal version of this idea is that the progress of civilization depends on a method, a reproducible procedure that delivers reliable results. Leibniz was echoed in the eighteenth century by Denis Diderot and Jean d’Alembert, the French creators of the first modern encyclopedia, who pursued their work not just to codify existing knowledge but to cross-validate it and accelerate future research. As these ambitious projects were realized, they articulated a vision of the world that unseated the prevailing orders of religiosity and hereditary feudalism. There is a reason many people credit Diderot and d’Alembert’s Encyclopédie française with helping to ignite the French Revolution. The Enlightenment has always contained within it a desire, a kind of utopian aspiration, that one day we will understand everything.
Leibniz was one of the chief advocates of that vision, not as a means of overthrowing a deity but of celebrating The Creation through human understanding. He was also a strong advocate of binary numerals and made an early attempt at building a calculating machine. In this effort, he attempted to represent existence and nonexistence, truth and falsehood, through ones and zeros: little wonder that so many of Leibniz’s ideas resurfaced in computation, where mathesis universalis is possible in the controlled universes of operating systems and declarative programming languages. The modern notion of the algorithm as a method for solving a problem or, more technically, a set of instructions for arriving at a result within a finite amount of time emerges from an extension of the Enlightenment quest for universal knowledge on the part of mathematicians and logicians.
The emergence of modern computer science in the 1940s and 1950s began with the proofs of computability advanced by Alan Turing, Alonzo Church, and others. It was, in many ways, a conversation about the language of mathematics, its validity and symbolic limits. This work created the intellectual space for computation as researchers such as Stephen Wolfram articulate it today, arguing not only that we can model any complex system given enough CPU cycles but that all complex systems are themselves computational. They are best understood, as Wolfram, a wildly inventive British-American scientist, mathematician, and entrepreneur, suggests in his book A New Kind of Science, as giant computers made up of neurons or molecules or matter and antimatter—and therefore they are mathematically equivalent. This is the “hard claim” for effective computability implicit in the most promethean work at the forefront of artificial intelligence and computational modeling: the brain, the universe, and everything in between is a computational system, and will ultimately be tractable with enough ingenuity and grant funding.
So the algorithm of the Enlightenment found its most elaborate expression in the language of code, and it has become increasingly commonplace, often necessary, to encode our understanding of the universe into computational systems. But as these systems grow more complex, and our capacity to represent data expands exponentially, we are starting to say things, computationally speaking, that we don’t fully understand—and that may be fundamentally wrong without us knowing it.
Consider the advanced machine learning systems Google has used to master Go, natural language translation, and other challenges: these algorithms depend on large quantities of data and training sets that reveal a correct answer or desired output. Rather than figuring out how to directly analyze input and deliver the required output, we are now starting with the input and a sampling of the desired output and black-boxing the middle. Simulated neural nets iterate millions of times to create a set of connections that will reliably match the training data, but offer little insight to researchers attempting to understand how it works. Just as with the algorithm analyzing the single-cell complex system, we can see that a law has been derived, but we don’t know how—we are on the outside of the laboratory, looking in.
Like computational algorithms, critical scientific inquiry depends on some important assumptions: that the universe is inherently causal, and relatively uniform in the application of that causality. But as we encode the method into the space of computation, our assumptions must change. The causality of computational systems is more specific and delimited than the causality of the universe at large: rather than a system of quantum mechanical forces, we have a grammatical system of symbolic representations. It is the difference between an equation that describes the curve of a line through infinite space, and a model that calculates the line’s position for a discrete number of points. (Want more points? Buy a better graphics card.) Or to take another example, it is the difference between a model of the weather that divides the sky into one-kilometer cubes and the actual weather, in all of its weird, still unpredictable mutability. When we encode our scientific work into computational representations, we introduce a new layer of abstraction that may warp our future understanding of the results.
The stakes are high because we are growing increasingly dependent on computational spectacles to see the world. The basic acts of reading, writing, and critical thinking all flow through algorithms that shape the horizons of our knowledge, from the Google search bar to the models assessing our creditworthiness and job prospects. For scientists, the exponentially increasing flood of information means that computational filters and abstractions are vital infrastructure for the mind, surfacing the right ideas at the right time. Experiments have shown how trivial it is to manipulate someone’s emotional state, or political position, using targeted computational messages, and the stakes only grow when we confront the desire inherent in computational thinking to build a black box around every problem. Right now we are accepting these intellectual bargains like so many “click-wrap” agreements, acting with very little understanding of what kind of potential knowledge or insights we might trade away for the sake of convenience or a tantalizingly simple automated solution.
In fact, we are far more to blame than our computational systems are, because we are so enamored of the ideal, the romance of perfect computation. I have seen many parents repeat sentences to their smartphones with more patience than they have for their children. We delight in the magic show of algorithmic omniscience even when we are bending over backwards to hide the flaws from view.
But of course there is no un-ringing the bell of computation, just as there is no reversing the Enlightenment. So what can we do to become more insightful users and architects of algorithms? The first thing is to develop a more nuanced sense of context about computation. The question of how the stakes of causality and observation change in computational models is fundamental to every branch of research that depends on these systems. More than once during the Cold War, US and Soviet officers had to see through a computer model showing enemy nukes on the wing and perceive what was really behind them: a flock of birds, perhaps, or a software glitch. As humans, we consistently depend on metaphor to interpret computational results, and we need to understand the stakes and boundary conditions of the metaphors we rely on to interpret models and algorithmic systems. That’s doubly true when the metaphors we are being sold are alluring, flattering, and simplifying. In short, we need a kind of algorithmic literacy, one that builds from a basic understanding of computational systems, their potential and their limitations, to offer us intellectual tools for interpreting the algorithms shaping and producing knowledge.
The second thing we need is to create better mechanisms for insight into computational systems. In a recent conversation on the topic someone half-jokingly proposed the example of the fistulated cow from veterinary science: a living animal with a surgically created hole in its flank that allows students to directly examine the workings of its stomach. There is a blunt analogy here to the “black box” metaphor so beloved of technologists and intellectual property lawyers—society needs new rules and procedures for prying open these black boxes when their operation threatens to perpetuate injustice or falsehoods. Elements of this are common sense: having a right to see what data a company has collected about us and how that data is used, and having easy access to a robust set of privacy and “opt-out” features that delineate what kinds of bargains we are making with these services. Perhaps more ambitiously, we need more open data standards so that models with real human significance—models of health care used to determine insurance benefits, for example—use definitions and calculations that are open to public review.
But on a deeper level, we need to think about fistulated algorithms as a means of regaining our capacity for insight and understanding. The collective computational platforms we have created, and are rapidly linking together, represent the most complicated and powerful achievement of our species. As such, it is a worthy object of study in its own right, and one we must attend to if we want to enjoy the thrill of discovery as well as the comfort of knowledge. These systems are not really black boxes floating in computerland—they are culture machines deeply caught up in the messy business of human life. We need to understand that causality works differently with algorithms, and that what you’re getting with a Google search is not just a representation of human knowledge about your query but a set of results tailored specifically for you. Our tools are now continuously reading us and adapting to us, and that has consequences for every step on the quest for knowledge.
This book was very difficult to review. In Ordinarily Well: The Case for Antidepressants, Peter Kramer, a psychiatrist and best-selling author, makes two arguments with which I agree. One is that clinical observation—the interaction by which a medical professional learns about a patient—counts for something. The other is that clinical trials, or evidence-based medicine more generally, are not a replacement for clinical wisdom. He values antidepressants, in particular the selective serotonin reuptake inhibitor (SSRI) class of drugs, and so do I, based on my own medical experience.
Applying support for clinical observation and skepticism about controlled trials to the question of whether antidepressants work, Kramer concludes that these treatments work very well. En route, he focuses on the claims of psychologist Irving Kirsch, among others, that based on clinical trial data, the benefits of antidepressants are all in the mind—a placebo effect. Kramer makes a straw man of Kirsch, but I agree with Kramer that antidepressants do things that are not all in the mind. I, too, reject Kirsch’s arguments that most of what antidepressants do stems from a placebo effect.
So where did my difficulties in reviewing the book come from? The trouble for me is that Kramer’s clinical vision seems strangely rose-tinted. He is an advocate of using antidepressants to treat depression, but he doesn’t seem to see any of the problems antidepressants cause. The fact that over half of the patients put on them don’t take them beyond a month should be telling. For those who do stay on treatment, he claims, no one has difficulties going off antidepressants with a gradual reduction in dosage. I, however, have patients suffering badly months or even a year later. In the case of any enduring problems, Kramer puts these down to the effects of the illness being treated rather than the medication
There is no discussion in this book of significant problems that the use of antidepressants can cause. These include SSRI-induced alcoholism; SSRI-induced birth defects, such as autism spectrum disorder; or permanent post-SSRI sexual dysfunction. In a 336-page book, the topic of SSRI-induced suicidality gets dealt with in one page. I think many surviving relatives would be astonished to hear that once the psychiatrist Martin Teicher had identified the problem of treatment-induced suicide, it became manageable. Kramer claims that “no case [he has had], not one, has looked like those Teicher has described, drug driven.”
Kramer asks us to believe in clinical observations—his observations. Not yours or mine or anyone’s that might cause the antidepressant bandwagon to wobble. He cites me at multiple points, so he is well aware of my work. But he doesn’t engage with the evidence that I and others have put forth, based on both clinical observations and other material, that SSRIs can unquestionably cause suicides and homicides, and do so to a greater extent than they prevent any of these events.
On the issue of children, suicide, and the black box warnings that antidepressants now carry, Kramer notes that “some of the data have trended the other way, although authoritative studies correlate increased prescribing with reduced adolescent suicide.” This fails to acknowledge that the drugs haven’t been shown to work in this age group. There is no mention that suicidal acts show a statistically significant increase in clinical trials in this age group. Kramer also does not indicate that among all ages, when all trials of antidepressants are analyzed together, they show increased rates of death (mainly from suicide) compared with non-treatment. He seems to have no feel for how compromised the “authorities” are that he uses to downplay the risks.
There are good grounds to be skeptical of the evidence-based medicine that Kramer uses to make his case. Quite aside from the fact that almost all the research literature produced by clinical trials is ghost written by pharmaceutical companies, and the data from them entirely inaccessible, controlled trials aren’t designed to show that drugs work. They work best when they debunk claims for efficacy, rather than the reverse. What’s more, the structure of clinical trials and their statistical analyses are the best method to hide a drug’s adverse effects. Ordinarily Well does not address these significant problems.
If a drug really works, then clinical observation should pick it up. We can tell antihypertensives lower blood pressure, hypoglycemics lower blood sugar, and antipsychotics tranquilize within the hour—all without trials. We can see right in front of us that antipsychotics badly agitate many people within the hour and that SSRIs can do so, too. But we cannot see anyone get better on an antidepressant in a way that lets us as convincingly ascribe the effect to the drug. There is much to be said for clinical observation, but also a lot to wonder about when clinical trials suggest that drugs work but we can’t actually see it. For anyone keen to defend clinical observation, Kramer’s book poses real problems and would leave many figuring we need controlled trials instead.
I live and work in the United Kingdom and am acutely aware of some differences between the United States and Europe that also made it difficult to review this book. There is much more “bio-babble” in the United States than in Europe, from talk of lowered serotonin to chemical imbalances to neuroplasticity and early treatment preventing brain damage—all of which Kramer reproduces. I felt a John McEnroe “you cannot be serious” coming on at many points. The tone in which some of these points are made suggests that everyone reading them will find what is being said self-evident, when in fact it’s gobbledegook.
All medicines are poisons, and the clinical art is bringing good out of the use of a poison. It strikes me as un-American to even suggest that a drug might be a poison, and Kramer’s book gives no hint of this; the book is, in this sense, deeply nonclinical. He is giving an account of a mythical treatment, as far removed from real medicine as an inflatable sexual partner is from the real thing. It seems to me that he would not see or hear many of the patients I see, or at least would not credit their view of what is happening to them on treatment. This book will misinform anyone likely to take an antidepressant.
It will also cause problems for physicians. This book does not balance the risks and benefits that are intrinsic to medical wisdom. If antidepressants are as effective as Kramer claims, and are as free of problems as he suggests, there is no reason why nurses and pharmacists couldn’t prescribe them. Given that they are much less expensive prescribers, the surprise is that health insurers haven’t moved in this direction.
There is a way to bridge the gulf between Kramer and myself, which involves clinical observation. Most of the beneficial effects Kramer describes can be reframed in terms of an emotional blunting, or the numbing of all emotions, not simply the bad ones. Just as people on an SSRI will nearly universally report genital numbing within 30 minutes of taking their first SSRI—if they’re asked—people will also report some degree of emotional numbing—if asked. They don’t necessarily feel better; they simply feel less.
Unlike the somewhat mystical brain re-engineering Kramer invokes, this emotional blunting can be verified by clinical questioning. If clinical trials were designed to assess whether patients are numbed by these drugs, there would be little need for the fancy statistics that pharmaceutical companies use to claim the targeted benefits of their drugs, since emotional blunting would be evident through clinical questioning. And Irving Kirsch’s arguments about placebo would be irrelevant.
If SSRIs numb emotional experience, this would explain why they help some and not others, and explain the results we see in clinical trials, which are similar to the results that might be expected from a trial of alcohol versus placebo in the milder nervous states in which antidepressant trials have been run. This, then, would present us with a question: what do we think about emotional blunting as a therapeutic tool? Emotional blunting is not a romantic option. It’s a much more ordinary one. If that is the process by which antidepressants work, it does patients an enormous disservice to avoid discussing it entirely, which this book does.
Change’s Challengers
On the one hand, the world is obviously a much better place than it used to be.
Don’t take my word for it: the past few years have seen a surge of evidence. Data visualization wizards, such as Sweden’s Hans Rosling and Oxford economist Max Roser, have used their two projects (Gapminder and Our World in Data, respectively) to graph human progress over the past several centuries, using axes measuring prosperity, health, education, female empowerment, and other metrics. Best-selling books, such as Harvard professor Steven Pinker’s The Better Angels of Our Nature, detail an increasingly peaceful world. Columbia University’s Ruth DeFries’s The Big Ratchet shows how humanity is growing more food more efficiently, making food cheaper, and leaving more room for wild nature. Nearly everywhere we look we are, as Charles Kenny succinctly but memorably titled his acclaimed 2011 book, Getting Better.
On the other hand, the world is full of risks, dangers, and insecurities that humans have not previously encountered.
The challenges facing humanity today have accumulated in both magnitude and complexity. They include climate change, the loss of ecosystems and animal populations, social and economic inequality, and a historically familiar resistance to multiculturalism in many countries. Making matters worse, the public and social institutions we count on to rebuff these risks are under attack.
Those of us pleased by the general outcomes of modernity (myself included) should take a moment to consider this tension, for it represents a real challenge to continued modernization for both the rich and the poor today. Although progress has become more robust and sophisticated over the course of modern history, so too have the powers that stall, obstruct, and reject progress.
In his new book, Calestous Juma pits these two forces viscerally against each other. Fittingly titled Innovation and Its Enemies, the book charts a fascinating new history of emerging technologies and the social opposition they ignite.
Juma would be high up on the list of experts to consult about such things. He is a professor of international development at Harvard University’s Belfer Center, directing the center’s work on science, technology, and globalization. An expert in agricultural systems and technologies, Juma has long been steeped in controversies over agricultural trade policy, genetic modification, and other agriculture and biotech debates.
He begins his book with a schema for why societies might resist innovations—a representation so lengthy and complex one wonders how any new technology could overcome it. Among other obstacles, Juma highlights intuitive factors, such as disgust and defense of what’s considered “natural,” vested economic interests, socio-technical inertia, and responses, such as risk aversion, that can stem from both intellectual and psychosocial motivations. With this structure, Juma makes it easy to draw parallels between his case studies—coffee, the printing press, margarine, farm mechanization, electricity, mechanical refrigeration, recorded sound, transgenic crops, and the genetically modified AquAdvantage salmon—and the social resistance to them on display today.
Searching for a precursor to the currently ascendant backlash against outsider faces, perspectives, and cultures? Look no further than authoritarian sixteenth and seventeenth century objections to coffee, a then-novel drink that was consumed in public spaces that “served as secular forum for conversation that drew people from all social strata.”
The seemingly endless battle of words and policies between renewable energy and nuclear power advocates? Let’s flip back to the dissemination of electricity itself, which saw Thomas Edison and George Westinghouse amp up their largely technical dispute with claims over morals, identity, and public health.
Concerns over human neuro-cognitive therapies and pharmaceuticals? These clearly echo anxieties over genetically modified crops, in that both innovations violate some (or many) definitions of what’s “natural.”
These are the CliffsNotes, of course. None of these innovations faced simple or singular opposition. Indeed, one of Juma’s conclusions from his case studies is that challenges to new technologies are “ not always direct but often clothed in other concerns depending on contemporary social and political factors.” Many emotional, rational, and faux-rational forces can be marshaled to quell the rise of a strange or distasteful new technology. Sometimes these forces might even be necessary, as when an innovation stands to profit the few at the expense of the many.
How, then, might we responsibly guide and accelerate innovation against its enemies? Technological superiority appears to be a powerful, if insufficient, condition: coffee proved a better stimulant than khat in Yemen or chicory in England and Denmark; electricity ultimately proved safer, more useful, and cheaper than its predecessors kerosene and town gas; transgenic seeds really do allow more food to be grown on less land, sparing large impacts on ecosystems and biodiversity.
But social organization and social license can be decisive as well. The printing press clearly serves the purpose of spreading literature and ideas better than oral history and copying by hand, but the cultural traditions of Muslims delayed acceptance of the printed word in the Ottoman Empire for four centuries. A previously fractured and unorganized dairy lobby in the United States fortified itself to fight the arrival of margarine. Juma quotes the medievalist Lynn White, writing that “the acceptance or rejection of an invention … depends quite as much upon the conditions of society, and upon the imagination of its leaders, as upon the nature of the technological item itself.”
Advocates of a particular technology commonly condescend toward “Luddites” who resist technological change. Pro-nuclear figures recite turgid technical and safety statistics to argue for its dominance. Biotechnology advocates refer to their interlocutors as “flat-Earthers” for resisting genetic modification. Climate campaigners demand a “wartime mobilization” of renewable energy technologies, casting aside concerns about energy system transitions, fuel prices, and local preferences for energy infrastructure. This is an understandable impulse; the promise of new technology is appealing to many, and societies have never had greater capacity to safely integrate innovation than they do today.
But it would be foolish to conclude that the best stance is to laugh off social resistance and blindly cheer the forceful arrival of new technologies.
Hallmarks of modernization include the centralization of production and the democratization of consumption. In other words, we have never had access to more and better technologies, but we (or at least most of us) are also far removed from the modes of production that make modernity possible. This distance from the source of ever-changing technology makes it inevitable, and appropriate, for the public to exercise its democratic skepticism toward a variety of innovations. The skeptics’ case is even stronger when innovation arrives without their consultation, which, as Juma puts it, “may confer more benefits to the producers, but [also] exposes them to collective action by consumer groups.”
So innovation’s enemies are not simply the enemies of modernity. They are modernity itself, with all its contradictory desires, forces, and discourses. Integrating this diversity of values and perspectives will take, Juma writes, “a worldview of the future that visualizes exponential technological advancement, appreciates the perception of loss in complex socio-economic systems, and develops more appropriate approaches for supporting informed decision making.” That means bold and bright political leadership. It means movements to fire up the public’s imagination. It means negotiating and channeling multiple social perspectives toward solving common problems.
It also means that the innovations and technologies we hope for might arrive a little more slowly than some of us would like. But we shouldn’t forget, in our impatience, that we have never been better equipped to pursue a bright technological future.
Anchor Management
Climate policy makers and political leaders love global targets. By adopting climate stabilization goals to limit temperature increases to a specified amount—usually two degrees Celsius (2°C)—above preindustrial levels, they demonstrate their commitment to solving a pressing global problem. Unfortunately, governments worldwide have delivered mainly promises so far, and their climate policies have been much more about intentions than about results. The policy relevance of climate science has been restricted mainly to policy formulation. It has not been translated into appropriate action.
That climate target-setting at the United Nations (UN) level has not been followed by radical cuts in global emissions is reason enough to criticize and reject the dominant “targets and timetables” approach, as shown by the work of scholars such as David Victor, Roger Pielke Jr., Steve Rayner, and Mike Hulme. In his insightful book The Two Degrees Dangerous Limit for Climate Change: Public Understanding and Decision Making, Christopher Shaw takes a somewhat different perspective. Even though it clearly identifies the many shortcomings of the two degrees climate target, Shaw’s critique is primarily concerned with the democratic quality of the decision-making process and the particular level set for dangerous climate change. “If climate change is the greatest challenge facing humanity,” he asks, “what sort of democracy is it that does not give people a say in the trade-offs that responding to climate change requires?”
The two degrees target is the result of a cooperative and mutually beneficial relationship between climate science and policy. The target’s development began as early as the mid-1990s, in an attempt to operationalize Article 2 of the UN Framework Convention on Climate Change (UNFCCC), with an objective to “prevent dangerous anthropogenic interference with the climate system.” The two degrees target was formulated through a dialogue between climate scientists and scientific policy advisors and was formally adopted by policy makers at the 2010 UN climate change conference in Cancún (COP16).
For almost 20 years now, the two degrees target has worked as an “anchoring device.” It allows networks of diverse actors to communicate and interact, albeit with varying motivations and objectives. For climate policy makers, the target has served as a prominent symbol of an ambitious global mitigation effort. For climate scientists, it has provided the basis for complex calculations to determine carbon budgets and emissions reduction paths, which in turn are used to demonstrate the usefulness of scientific tools in the design and evaluation of climate policies. Through their interactions, scientists and policy makers provide each other with mutual reinforcement and recognition: the scientific community lends support and legitimacy to political efforts to advance the climate policy agenda, while policy makers support climate research, which in turn is reflected in heightened public awareness and significantly increased funding.
Shaw does not see this as evidence of success. From his perspective, which focuses on the interests of vulnerable countries and marginalized communities, the broad consensus on two degrees is problematic in several respects. First, the assumption that avoiding dangerous climate change means the same thing for the whole of humanity effectively masks conflicts between the interests of different countries and social groups. Second, the logic of risk management and safety limits not only frames climate change as a technical issue that can be managed by experts, but also establishes the idea of an “acceptable” amount of climate change or greenhouse gas emissions. Third, by setting the limit at a temperature level that might not be crossed for decades to come (since there is a time lag between emissions and temperature response), the two degrees storyline depicts climate change primarily as a problem that will become palpable only in the future. Fourth, since the two degrees limit is usually not presented to the public as co-produced by scientists, advisers, and policy makers, but rather as a hard scientific fact, it discourages public scrutiny of both the idea of a single global limit and of the particular level set. Last but not least, the two degrees limit represents an elite consensus from which marginalized and dissenting voices have been excluded.
The unique feature of the book, which is based on Shaw’s doctoral dissertation, is that it examines public representations of the two degrees limit in the United Kingdom. Analyzing news media and interviews conducted with climate scientists, policy makers, and activists, Shaw is able to reconstruct how the concept of a single, global measure of dangerous climate change became established within the climate debate in the United Kingdom, and how it has been legitimated and sustained within the British public sphere.
Although Shaw’s critical analysis of British media and policy discourses does not offer especially fresh insights, it is fascinating to read how scientists, policy makers, and activists deal with the underlying complexities of the two degrees limit. Shaw sees a “not in front of the children” approach at work here. Policy wonks usually know quite well that there cannot be a single threshold to dangerous climate change. Some even know that two degrees is based on a set of uncertain assumptions, a rather contingent choice not very well founded in climate science. Yet in public, they all defend the established concept, since it is such a powerful instrument for climate policy formulation, or, as a campaigner puts it: “Uncertainty is really not a big help in the political domain and public communication.”
Shaw’s critical examination of the now-established concept of setting a limit for dangerous climate change comes at the right time—or maybe a bit too early. Unfortunately, the book does not reflect on the outcome of the Paris climate summit (COP21) in December 2015, which brought about a new target formula: the intention of “holding the increase in the global average temperature to well below 2°C above pre-industrial levels and to pursue efforts to limit the temperature increase to 1.5°C above pre-industrial levels, recognizing that this would significantly reduce the risks and impacts of climate change.” The UNFCCC even demanded that the Intergovernmental Panel on Climate Change (IPCC) write a special report on 1.5°C by 2018, although the new “pledge and review” approach that is at the heart of the Paris Agreement commits signatories to an aggregate emissions level in 2030 that would probably lead to a 3° to 3.5°C temperature increase by 2100.
So what might Shaw make of 1.5°C? Although not the consensus-anchoring device of two degrees, this lower target has been part of UN negotiations since the Copenhagen summit (COP15) in 2009. Shaw’s book mentions it occasionally, mainly to show that there have been alternatives to 2°C under discussion that aimed to lower the acceptable level of climate risk, particularly for the most vulnerable countries. But since a 1.5°C limit for dangerous climate change shares many features with the two degrees limit, Shaw’s approach contains a healthy wariness toward a mere change of the target’s level if the process of arriving at that result remains unchanged. Or, as he puts it: “The question is not just what, if anything, should replace the idea of a two degrees limit, but who should decide what, if anything, replaces it.”
The Two Degrees Dangerous Limit for Climate Change is a valuable contribution to the critical debate about global climate targets, which has entered a new phase after the Paris Agreement. We can hope that the 1.5°C decision, the commissioning of a new IPCC special report on 1.5°C, and the obvious inconsistency between talk, decisions, and action in UN climate policy making will motivate a more fundamental debate on the use and abuse of targets in climate policy. So far, the setting of long-term global climate stabilization targets has not been a prerequisite but rather a substitute for appropriate action.
A Technology-Based Growth Policy
Monetary and fiscal policies to stimulate the economy are no substitute for the national research and development investment needed to spur productivity growth and create high-paying, high-skill jobs.
Talk to people in industry, academia, or government who are connected in some way with the advancement of science and technology and they will be able to connect specific advances in science to the emergence of new technologies and subsequent product or service innovations. And, among most economists who study the technology-based economy, no doubt exists as to the critical importance of this phenomenon.
However, making the extension from general anecdotes and descriptions to a broader and policy-specific economic growth strategy that would extend such benefits to the entire economy and, hence, have substantial impact on the standard of living has been a struggle. That is, the case for sufficient investment to meet the challenges of an expanding global technology-based economy has not been effectively articulated. As a result, the potential economic benefits for workers and the population as a whole are not being realized.
Similar policy failures have appeared in other industrialized nations. However, the problem of skewed economic growth and the resulting increase in income inequality have been particularly severe in the United States.
Goals of economic growth policy
Economic analysis demonstrates that the only path to long-term growth in incomes is to steadily increase productivity growth. This is because greater efficiency enables higher salaries and wages. In contrast, without adequate productivity growth, the resulting inefficient economy will suffer inflation, trade deficits (i.e., offshoring of jobs) and, as a consequence, little or no real (inflation-adjusted) income growth.
Responding to this mandate requires enlightened investment policies focused on the development and use of technology. The reason is straightforward—technology is the long-term driver of productivity growth.
Unfortunately, neither economists nor the broader economic growth policy arena has focused sufficiently on this investment mandate. The main reason is that, on the one hand, most economists do not understand and, hence, do not appreciate the nature of the central role of technology in economic growth, while, on the other hand, the science and technology policy community, while understanding technology’s central role, is not equipped to translate its understanding into the growth policy prescriptions needed to leverage productivity growth.
Achieving sustained growth in productivity requires an investment-driven economic growth strategy, centered on investment in four major categories of economic assets:
Technology: The core driver of long-term productivity growth.
“Fixed” capital: Hardware and software that embody most new technology and, thereby, enable its productive use.
Human capital: Skilled labor capable of using the new hardware and software and associated techniques.
Technical and institutional infrastructure: Public-private infrastructure to leverage the development and use modern complex technology systems.
Success then and now
In the most summary way, US economic growth history has consisted of a series of “revolutions,” which were worldwide in scope, but manifested themselves to a greater degree within the American economy. The first of these occurred from the late 1700s through the middle 1800s and was characterized by a transition from hand to mechanized manufacturing using water and steam power. The second revolution began in the late 1800s and extended into the first part of the twentieth century. It was dominated by mass production, powered by electricity. The specification and control of the multiple steps in production led to reduced costs (economies of scale). The third revolution began in the late 1900s has been characterized by automation, based on the widespread use of computers, which has led to more diversified and higher quality products and services (economies of scope).
The critical point for economic growth policy is the fact that in all three revolutions, the driver of the resulting massive change in the character of economic activity was technology. So, logically, as a society, we should be increasing research and development (R&D) spending to extend leadership in the current technology epoch and to prepare for the next one.
But, what complicates such transitions is the fact that technology by itself is not enough to generate and sustain high rates of output and income growth. In each revolution, new technology was implemented through almost a total replacement of the existing stock of physical capital (and, more recently, software, as well).
Further, during most of this period, the US educational system produced superior skilled workers and government invested in world-class infrastructure. The result of these four categories of investment was that the US economy had the fastest sustained growth in per capita income over most of this period.
In contrast to a productivity-driven economic growth strategy, the more recent US policy response to slow growth has been to rely on the Federal Reserve Board (the Fed) to provide more and cheaper credit through monetary policy initiatives. However, while flooding an economy with money can increase aggregate demand for a time, it does not rehabilitate an economy’s long-term competitiveness. Hence, the best it can do is pump up employment for a while before inflation sets in, which then forces the Fed to raise interest rates and throttle back economic activity. This cycle of ups and downs does little to increase incomes over time.
In contrast to business cycle fluctuations, which are largely the only appropriate target of monetary policy, underinvestment in productivity-enhancing assets is typically the cause of slow economic growth over time and therefore an alternative policy response is required. However, even though significant evidence exists that structural problems are the cause of prolonged poor rates of economic growth, there continues to be a lack of adequate investment in the four categories of economic assets cited previously.
One indicator is the growing difficulty of the American economy to snap back from recessions, as shown in Figure 1. Very important is the fact that eight years after the last recession ended, we are only now beginning to see some modest increases in incomes, while income inequality has greatly expanded. These trends are occurring in spite of historic increases in credit by the Fed.
Particularly damning is the fact that real (inflation-adjusted) incomes for many workers have declined for decades. Real incomes determine ability to consume goods and services and the potential for increases in the standard of living. A Brookings Institution analysis of Census data shows that the median earnings for all workers was significantly lower in 2015 than in 2007 in a little more than half the major metro areas (52 of 94). Many more metro areas—71 of the 94—posted significant earnings declines among workers who possessed only some college or an associate’s degree. Going back even further, across several business cycles, Census data show that the real median household income in 2015 was 2.4% lower than in 2000. Real wages for manufacturing workers peaked in 1978 and have declined almost 9% since then.
The decline in the standard of living for less-educated American workers has become a major source of political dissent. This dissent is accentuated by growing income inequality. While structural decline has led to stagnant and even declining real incomes for many Americans, the most wealthy have been able to benefit from globalization by investing across the world’s economy.
The extent of income inequality is staggering. University of California-Berkeley professors Emmanuel Saez and Gabriel Zucman calculate that the wealth of the top 0.1% of US households equals the aggregate wealth of the bottom 90%. A critical point is that across the world’s economies, income inequality is inversely correlated with per capita income. More advanced economies—that is, those with a higher per capita gross domestic product (GDP)—tend to have less income inequality for the simple reason that their above average performance requires more skilled workers whose skills are not easily replicated elsewhere in the world and who are, therefore, paid more.
However, the US economy is an outlier in that it has a much higher Gini coefficient (the generally accepted metric for income inequality) relative to its per capita GDP when compared with the pattern for the rest of the world (the United States has the same Gini coefficient as Russia and China but a much higher per capita GDP). Income inequality implies the presence of relatively strong additional factors affecting income distribution within the US economy.
While many maintain exaggerated views of the capabilities of monetary policy, liberal political factions and a number of economists have looked instead to fiscal policy for “fixes,” mainly in various forms of more progressive tax structures or other forms of income redistribution. Thus, we see proposals for tax increases on the rich and tax breaks for everyone else, increases in the minimum wage, and more targeted initiatives such as free college tuition. Although any or all such proposals may have social merit, they are largely just additional mechanisms for demand stimulation and thus offer little in terms of enhancing long-term productivity growth.
US corporate income tax rates are among the highest in the industrial world and we only now appear to be getting serious about removing the differential tax on repatriated corporate earnings from other economies that have lower corporate tax rates (corporations bringing external profits back home are taxed on these profits at a rate equal to the difference between the two countries’ corporate income tax rates). Currently, $2.1 trillion in overseas profits are estimated to be sitting in foreign banks instead of being repatriated back to the US economy where they could be invested.
Finally, the drastically reduced ability of labor to bargain is indicated by Bureau of Labor Statistics (BLS) data showing that “work stoppages,” once a regular occurrence, have virtually disappeared due to the weakened position of lower-skilled workers from growing competition elsewhere in the world.
Faced with such competition, the weakest and most destructive response from an economic welfare perspective is to erect trade barriers to protect inefficient domestic industries and their inadequately trained workers. Such a step locks in inefficiency and, hence, guarantees no growth in the standard of living in two ways. First, protectionism by removing incentives to increase productivity virtually eliminates any possibility of sustained increases in workers’ incomes while imposing higher prices on domestic consumers. Second, protectionism usually results in retaliation by other economies. Yet, populist segments of both political parties have viciously attacked the North American Free Trade Agreement and more recent trade agreements as “destroying jobs.”
The seriousness of these policy failures is reflected in manufacturing trade deficits every year since 1975, with the size of the deficits growing steadily to $831 billion in 2015. This trend is demonstrated in Figure 2. Particularly important for future income growth is the “advanced technology products” trade balance, which turned negative in 2002 and continued to deteriorate to a record deficit of $100 billion in 2011 with little improvement since then.
In summary, it is traumatic for societies to accept the need to develop and implement new economic growth paradigms. Doing so presents societal risk of failure to successfully execute the new paradigm and individual risk of being left behind as others adapt more successfully. Part of this risk is the considerable time and resources needed to learn new skills, acquire new technology, and make associated investments in capabilities to use it, and, in many cases, different ways of doing business. Thus, defenders of the status quo look for excuses to avoid change by asserting that the economic problems are due to too much taxation and regulation, unfair trade practices by the rest of the world, and forcing higher costs on business from social objectives such as a higher minimum wage. Although these are real issues and need to be debated, they are often used as excuses for not dealing with the need for major change in economic structure and associated investment strategies.
In the end, failure to adapt leads to long-term decline in incomes. The resulting frustration eventually is manifested in populist movements that demand change with little idea as to the underlying nature of the problem. This leads to support for any politician offering change, whether or not the proposed change offers an effective long-term solution.
Thus, the only way forward is to determine the correct economic growth model and then build a consensus around it. Clearly, the excessive reliance on macrostimulation—monetary and fiscal measures—is not succeeding. Even the Fed’s economists have questioned the extent of the burden placed on monetary policy. And, fiscal policy, when used as a demand stimulation tool (basically running budget deficits), has not worked. Both provide short-term increases in demand, but that is followed by inflation as inadequate productivity growth forces higher prices for goods and services.
However, as discussed below, fiscal policy also has an investment component, which is an essential policy tool for expanding the technology-based economy. The distinction between the business cycle stabilization role and the investment role for fiscal policy has not been sufficiently made, but it is an essential step to a workable economic growth policy.
A structural problem
We are on the cusp of a fourth industrial revolution in which virtually all economic activity will be connected through the Internet. This so-called “Industrial Internet of Things” will create enormous increases in industrial productivity, but will also require substantial investment to effect the transition. Be assured that this time there will be considerable competition across the global economy.
The current sluggish trend in productivity growth does not predict the needed response to growing global competition. BLS data show that for the first 30 years after World War II (1948-1978), labor productivity in the US economy (nonfarm business sector) grew at a robust average annual rate of 4.1%. But then, as globalization set in, the average annual growth rate dropped precipitously to 2.6% over the next 30 years (1978-2008). At that point, the 2008 recession set in, and post-recession labor productivity growth (2008-2015) has dropped even more to an average annual rate of 1.3%.
However, it is important to note that in the 14-year period between 1993 and 2007, US labor productivity temporarily revived to grow at an average annual rate of 3.1%—faster than any other industrialized nation for this period. This relatively short, but strong, period of growth was the payoff for the previous decades of R&D spending on information and computer technology (ICT).
Most important from a policy perspective is the fact that labor productivity reflects workers’ contributions to the value of output. Hence, it is the basis for real wages that are paid to workers. Real wages are the important metric because they reflect purchasing power and, hence, workers’ standard of living.
However, for labor productivity to grow, workers must be increasingly skilled and have access to hardware and software that embody productivity-enhancing technologies. Thus, the ultimate measure of maintaining competitiveness over time is the rate of growth of multifactor productivity (MFP)—the effect on output of the combined productivities of both labor and capital. Again, in the first three decades after World War II (1948-1978), US economic superiority was reflected in a strong average annual rate of growth in MFP of 2.2%. But, in the following 15 years, 1978-1993, when globalization began to have significant impact, MFP growth fell to an average annual rate of only 0.4%.
As was the case for labor productivity, several decades of research on information technology began to pay off in the 1990s for overall productivity. For the 14-year period between 1993 and 2007, the annual rate of MFP growth tripled to 1.3%. But, since the Great Recession, 2007-2014, annual MFP growth has dropped to just 0.4% per year. This drastic decline is reflective of a poor rate of “private fixed investment” (hardware and software) through which most technology is used in economic activity.
These dramatically different trends over successive time segments have an explanation, which needs to be understood by our policy makers. The beginning of trade deficits in 1975 and the 1978 peak in real wages for manufacturing workers are coincident with the onset of serious globalization. In economic terms, “globalization” is a label for a “convergence” in which the number of economies that can absorb technology into their domestic economy and have trained their labor force to use it grows steadily, siphoning off global market shares and, hence, jobs from the leaders.
The impact on US manufacturing workers has been a labor arbitrage in which either jobs move offshore or American workers have to accept lower pay to bring their productivity-wage relationship closer to that of competing workers elsewhere in the world. Yet, survey after survey shows that corporations cannot find enough qualified workers for newer, more technical jobs, which, importantly, are also higher paying. Until American workers’ skills are upgraded to attract significant investment into the domestic economy, wages will be constrained and income inequality will remain unacceptably high.
The economic profession as a whole has not been much help here. Only a very few economists specialize in the role of technology in economic growth. And even some of this work ends up misleading policy makers. Robert J. Gordon, a noted economist focusing on productivity and economic growth, has correctly emphasized the enormous impact of the computer or “digital” revolution on productivity growth. However, he argues that we will never see another technology epoch this powerful again.
At least a few economists correctly see the relentless march of technology and the imperative to support it. The Economist, in a June 2016 special report on artificial intelligence (AI), stated that “AI is already useful, and will rapidly become more so.” Its imminent explosive impact is arriving after decades of false starts and promises. The National Science and Technology Council in the White House issued several reports in 2016 touting the emerging impact of AI.
Such patterns are typical of major new technologies and repeatedly fool contemporary observers with long gestation periods. Thus, as a society, it is not surprising that we have not grasped the core role of technology in long-term economic growth, and the fundamental fact that new technologies will always appear, at least somewhere in the world. If we want a higher rate of economic growth and the social benefits it produces, the following four categories of investment must be maintained at high levels.
The four investment imperatives
In place of the obsessive overemphasis on monetary policy, which is not even a growth policy tool, the US economy needs the following four-point investment strategy to grow productivity at rates sufficient to broadly elevate GDP growth and incomes.
Technology. R&D intensity (R&D relative to GDP) is a critical indicator of future economic growth potential because it reflects the amount of an economy’s output of goods and services that is being invested in technology to drive future productivity growth.
Figure 3 shows that the dominant position of the United States as a funder and performer of R&D has been steadily eroding. The United States now ranks 10th in the world in R&D intensity. We still account for one-third of the world’s R&D, but that means two-thirds of global R&D is now performed elsewhere.
A similar negative pattern is occurring for the federally funded portion of national R&D. The most important reason for more and the right kind of federal R&D spending is that investments in (1) technology, especially in its early phases of development, and (2) supporting technical infrastructure (“infratechnologies” and associated standards) have significant degrees of public good character. The concept of public good content in technology (as opposed to scientific) research is not new, but in the United States, the dominant target of such funding is to support social missions (defense, space, clean and domestic-sourced energy, etc.). Conservative factions have not bought into the concept that technology development for economic growth purposes has any substantive role for federal funding.
A particularly important target of federal spending is early-phase technology research that is designed to test proofs of concepts, or “technology platforms,” upon which industry bases the applied R&D leading to innovations. Although critical for the efficiency of subsequent applied R&D, such concepts, or platforms, are a long way from achieving commercially viable products and services. Companies, therefore, apply a large time-discounting factor to this research, making it less likely that they will invest in it. Moreover, the early phases of a new technology’s development entail considerable risk, which causes industry to further adjust downward the expected rate of return.
Further, such proof-of-concept technology research exhibits significant spillovers, meaning companies don’t get anywhere near all the intellectual property benefits from these early-phase R&D investments. Finally, the resulting technology platforms exhibit significant economies of scope with respect to potential markets, the set of which is usually broader than the strategic scope of even large firms. The combined impact of these “market failures” is inadequate expected rates of return for investors and, hence, substantial underinvestment by the private sector.
You would think that several decades of competitive erosion would have finally woken up politicians to the need for substantial R&D policy adjustments. However, federal government R&D spending, which funds much of the new technology platform research that starts new industries and leads to private-sector innovation, has declined 14% in real terms since the Great Recession.
Competing economies also provide greater incentives for corporate R&D. The Information Technology and Innovation Foundation (ITIF) estimates that the United States ranks just 27th out of 42 countries studied in terms of R&D tax incentive generosity. The bottom line is that R&D investment strategies in the United States are inadequate with respect to both amount and composition.
Fixed investment. Fixed investments (hardware and software) embody most new technology and, thereby, enable commercialization that leads to productivity growth. Figure 4 shows the dramatic changes in the rate of “fixed private investment” (hardware and software) on multifactor productivity growth.
Specifically, when decades of R&D in information technologies by both government and industry finally reached commercial viability in the 1990s, industry dramatically increased its investment in this area to take advantage of this productivity-enhancing technology, as shown in Figure 4 by the steeper slope AA’. As pointed out previously, the accelerated investment resulted in a significant increase in the rate of multifactor productivity growth. However, without subsequent major new technologies and sufficient domestic investment incentives, the rate of corporate investment declined notably in the 2000s and multifactor productivity growth declined as well, indicated by BB’.
In its place, companies yielded to pressures from Wall Street to deliver short-term benefits to investors. For example, in the period 2009 to 2014, US domestic corporate R&D spending totaled roughly $1.5 trillion. However, during this same period, companies in the Standard and Poor’s 500 Index were estimated to have spent $2.1 trillion on stock buybacks. While such buybacks provided short-term benefits to corporate managers and shareholders in terms of higher per-share earnings, they soaked up corporate funds and thereby contributed significantly to a decline in the growth rate of corporate investment.
Skilled labor. BLS data show that in all but one of 71 technology-oriented occupations, the median income exceeds the median for all occupations. In 57 of these occupations, the median income is 50% or more above the overall industry median. So, a policy imperative is to increase domestic worker skills to levels that are not easily accessible elsewhere in the global economy, thereby forcing companies all over the world to choose the US economy as the preferred investment location. Further, a stronger US advanced technology sector will increase exports and thereby enable the US dollar to be stronger, which, in turn, will enable all US wages, not just in export-oriented sectors, to be higher in real terms, as the price of imports will decline.
Unfortunately, virtually every survey and testimonial by corporate executives confirms that community colleges and universities are not turning out the right mix of skilled workers. In a 2014 survey by the Business Roundtable, 97% of the responding CEOs said the skills gap threatens their businesses. A significant number of CEOs said they are having difficulty finding workers with computer and IT skills, advanced quantitative knowledge, and even basic science, technology, engineering, and mathematics (STEM) literacy. A 2015 study by Deloitte and the Manufacturing Institute estimates that over the next 10 years, 3.5 million new manufacturing jobs will be created, but the skills gap will prevent 2 million of them from being filled.
One would logically expect that the supply of skilled labor would eventually adjust to meet shifts in demand. In fact, some community colleges, with help from grants from the Labor Department, have revamped curricula in consultation with local industries to adjust the skills mix of the local labor pool. However, this is not being done at close to the level needed, and other economies are continually upgrading their education and training programs, thereby creating a moving target.
Further, The Economist points out that the United States spends about one-sixth the average amount of other industrialized economies on retraining labor in trade-impacted industries. Thus, retraining of existing workers whose skills are inadequate for competing in global technology-based markets is well below levels in competing economies. STEM curricula are being developed and implemented in some public school systems, but the average penetration rate is low and the variance across states is high.
The imperative for drastically updating the US educational system is underscored by major efforts in other economies to upgrade both production and research skills. For example, northern European economies have had comprehensive vocational training programs for decades. China’s World Class 2.0 project has the objective of increasing the research performance of China’s nine top-ranked universities, with a goal of having six of those institutions ranked within the world’s top 15 universities by 2030.
Industry structure and supporting infrastructure. The complexity of modern technologies means that supply chains have become a more important policy target than individual industries. Vertical integration of suppliers and their customers (adjacent tiers in the supply chain) is required to make sure performance specifications are adequately developed and the interfaces between components of a technology system are fully and efficiently functional.
Passage of the Revitalize American Manufacturing and Innovation Act of 2014, which authorized a National Network for Manufacturing Innovation (now called Manufacturing USA), is a beginning. However, the size and scope of the resulting Manufacturing Innovation Institutes (MII’s) is way too small. Instead of the current nine MII’s, there should probably be around 50. Congress authorized this program but refused to fund it, forcing the Obama administration to fund the current MII’s using existing R&D agency funds.
Funding these few MII’s through the Department of Defense and the Department of Energy means that the portfolios of research projects will reflect those agencies’ needs to a significant extent. This current US R&D strategy of relying on mission-oriented agencies is fine for them, but it is not optimal for economic growth more broadly.
As a comparison, Germany, with a GDP less than a fifth of the United States, has 67 Fraunhoffer Institutes. Although not equivalent in research mission to MII’s (their focus is on more applied R&D than the MII’s), the size and scope of this German program reflects far greater emphasis on productivity growth and is tied into a comprehensive German economic growth strategy for advanced manufacturing. Further, funding these few MII’s through the Department of Defense and the Department of Energy means that the portfolios of research projects will significantly reflect those agencies’ needs.
In terms of industry structure, horizontal integration (cooperation by firms in the same industry) has, until recently, been frowned upon by policy makers steeped in neoclassical economics due to the purported negative implications for competition. However, the market failures identified previously make a strong case for cooperation in the development of technology platforms and infratechnologies due to their public good content. Thus, competing companies (in the same industry), while conducting their own proprietary R&D as in the past, increasingly participate in joint (precompetitive) research, using regional industry consortia (“innovation clusters”) to conduct early phase proof-of-concept technology research.
Another reason for promoting regional and sectoral clusters of firms in high-tech supply chains is the reality that modern technologies are complex systems. For example, automobiles used to be a modest set of hardware components: engine, drive train, suspension, and the like. However, for at least a decade, cars have contained numerous subsystems for which electronics is a central element. These subsystems are controlled and connected to each other by as many as 100 microprocessors in some models.
Efficiently developing such technological systems requires coordination and efficient interfaces among a large number of companies making up the automotive supply chain, who are necessarily undertaking progressively larger shares of automotive R&D. The inherent complexity means that co-location synergies among component suppliers and system integrators are significant.
This and many other evolving patterns of industrial development mean that multiple component technologies must be developed based on somewhat different areas of science and engineering. Thus, single companies, even the largest ones, cannot develop all components. Further, all components must advance at some minimum rate for system productivity to be realized in a time frame driven by global competition.
Finally, overall economic efficiency is increased by the fact that regional “innovation clusters” offer a large and diversified pool of skilled labor to draw upon. Workers can move among companies much more efficiently as labor needs shift. Toyota recently announced that it would invest $1 billion over the next five years in the development of AI and robotics. The company chose the mother of innovation clusters, Silicon Valley, as the location for this research because of the unparalleled availability of the needed research talent.
More typical are communities such as Greenville, SC, which is a fast-growing site for advanced manufacturing, largely supporting the automobile and aerospace industries. Greenville Community College has been upgraded and restructured to train workers for high-tech jobs. Workers who once made $14 per hour in low-skilled service jobs now make $28 per hour in high-tech manufacturing plants. Yet, the national economic growth problem is that Greenville gets a lot of attention because too few others like it exist.
The growth strategy
The solutions for economic recovery and growth being pushed in this country—general tax and regulatory reductions—are simplistic and naïve. They ignore the complexity of the assets underlying the successful modern economy. In fact, it is differences in economic asset accumulation strategies that distinguish successful economies from the rest.
Economists have touted the “law of comparative advantage” for 200 years. The basic premise underlying its conceptualization has been that global economic welfare is maximized if each economy produces the products and services in which it is relatively more efficient. Note that this means economy A may have an absolute efficiency advantage in two products compared with economy B, but both economies are better off if economy A specializes in the product for which it has the greatest productivity advantage over economy B and let economy B produce the other product.
For most of the past century and a half, such comparative advantages were relatively stable over time, being based on endowed resources within each economy such as land, minerals, and labor skills—all of which changed slowly. Even technology evolved at a snail’s pace, making technological change largely a nonfactor.
Today, the intrinsic character of the law of comparative advantage has changed dramatically. The growing dominance and pace of new technology development means that comparative advantage can and is being created by competing economies on a regular basis, as opposed to being taken as a static condition. Further, the public-private nature of technology assets means that governments now compete against each other as much as do their domestic industries.
Yet, populist movements that have arisen in the United States and other industrialized nations are the antithesis of adaptation to the broadening and deepening global technology-based economy. The major change since the first Industrial Revolution is the increasing dynamic through which old jobs are lost, but through productivity growth resulting from the emergence of new technologies, new jobs will be created. Most important, these new jobs are higher skilled and will, therefore, pay more.
Yes, the labor content per unit of output will be lower, at least in manufacturing, which gives rise to the fear of lower employment. However, greater comparative advantage in trade will expand market shares, which means more of the high-skilled, high-paid workers will be needed. The United States accounts for less than 5% of the world’s population. This means over 95% of consumers live outside this country. So, we want to restrict trade?
What opponents of trade agreements such as NAFTA are really saying is that they are afraid that the economy cannot compete or cannot muster the national discipline to adapt to foreign competition. They, therefore, fight to protect increasingly noncompetitive industries and their low-paying jobs.
Any gain from protectionism would be short lived. Because domestic substitutes for imports would be more expensive due to lower productivity, average wages would have to fall to compensate, and our standard of living would fall. There is not a single example in the history of the world’s economy where protectionism resulted in a higher standard of living. Inefficiency pays less, not more.
With respect to the fear of job losses from automation, major technological epics have occurred for centuries, and each time some economies adapt and some do not. One point is unassailable: technological change will never cease, but its pattern is “lumpy,” which means economic and social upheavals will occur. We are getting a double dose, as the global technology-based economy is rapidly expanding to include a growing number of nations, while new digital technologies are radically changing both industry and society.
The United States has responded to a degree. The Manufacturing USA program implements new institutional research mechanisms (the precursors to innovation clusters) that address the transition phase of R&D from science to proof of technology concept and then provide efficient technology transfer to the embedded supply chain. State and urban initiatives using incubators and accelerators are very helpful in both increasing technology commercialization efforts and attracting venture capital funding to small high-tech firms.
However, these responses to date have been limited and uneven across the US economy. So, the question is can we adapt with the necessary scope and depth? When the Russians put a man into Earth orbit for the first time, we didn’t withdraw from the space race and pass a law forbidding other countries from flying spacecraft in low-Earth orbits over our country—the equivalent of the current support for protectionism. Instead, America responded to President Kennedy’s challenge to put a man on the moon in less than a decade, which the nation did with the greatest systems engineering achievement in history.
The forthcoming Industrial Internet of Things, or “Industry 4.0” as it is called in some other countries, is a major revolution that will require huge investments in information and communications technologies. The combination of automation and digitalization will require that these investments be integrated and managed by an advanced infrastructure that spans product systems and post-sale updating of system components. Such a dynamic extension of current product-service supply chains will give new meaning to the concept of technology life cycles and will require a huge upgrade in supporting infrastructure.
The major policy problem is that investment in new technologies has too long a time horizon and too much technical and market risk to be spurred by lower interest rates on loans, as much of the economic policy community seems to think is the case. The required investment stretches out over many years and exhibits risk and capture profiles that are beyond the capacity of the limited risk and high discount rate tolerances of corporate investment criteria.
The World Economic Forum correctly characterizes the nature of future competitiveness as the set of institutions, policies, and factors that determine the level of productivity of an economy, which, in turn, determines the level of prosperity. We can achieve higher rates of economic growth and raise middle-class incomes, thereby reestablishing growth in our standard of living, by challenging ourselves to make the required investments in the four categories that I’ve described here.
The United States has a history of success in technology development and deployment by providing support for new technology platforms, which over an extended period have yielded new high-growth industries. And grass-roots efforts in a variety of industries through initiatives by state and local governments further demonstrate the essence of the needed resolve and resourcefulness to compete in the evolving global economy. What is missing is the national coordination and provision of resources to make the needed transition of sufficient scope and efficiency to grow national productivity at the required pace.
Gregory Tassey is a research fellow at the Economic Policy Research Center at the University of Washington.
Recommended reading
Martin Neil Baily, “Productivity should be on the next president’s agenda,” Brookings Report: 11 Ways the Next President Can Boost the Economy, The Brookings Institution; available online: https://www.brookings.edu/research/how-to-rev-up-productivity.
Alan Berube, “Middle-skilled workers still making up for lost earnings,” The Brookings Institution (19 October 2016); available online: https://www.brookings.edu/blog/the-avenue/2016/10/19/middle-skilled-workers-still-making-up-for-lost-ground-on-earnings
Nanette Byrnes, “Learning to Prosper in a Factory Town” MIT Technology Review (18 October 2016).
Daniel E. Hecker, “High-technology employment: a NAICS-based update,” Monthly Labor Review (July 2005): 57–72.
Emmanual Saez and Gabriel Zucman, “Wealth Inequality in the United States Since 1913: Evidence from Capitalized Income Tax Data,” Quarterly Journal of Economics 131, no. 2 (2016): 519-598.
Shawn Sprague, “What Can Labor Productivity Tell Us About the U.S. Economy?” Beyond the Numbers 3, no. 12 (May 2014).
Gregory Tassey, “Rationales and Mechanisms for Revitalizing U.S. Manufacturing R&D Strategies,” Journal of Technology Transfer 35, no. 3 (2010).
Science’s Role in Reducing US Racial Tensions
The United States of America is embroiled in fights, debates, riots, and sit-ins over racial injustice. In 2012, the death of Trayvon Martin, a black teenager, sparked protests about stand-your-ground laws in Florida. In 2014, the deaths of Michael Brown in Ferguson, Missouri, and Eric Garner in New York City fueled anger over tough police action. Most recently the police deaths in Dallas have degenerated the relationship between police and public to an unprecedented low. To make matters worse, the presidential campaign and election of Donald J. Trump has uncovered a racist undercurrent in the United States that has caused many people from minority groups to fear for their safety. Every few months there is another report about police brutality or racially motivated hate crimes aimed at the minority populations that sets off a round of protests, civil unrest, and arrests.
In academia, a variety of race-related issues at Georgetown University, Princeton University, the University of Oklahoma, and the University of Missouri, have caused administrators to resign, buildings to be renamed, and training on racial sensitivity to be mandated. College campuses are struggling to find solutions to make themselves more inclusive and promote diversity of thought. Often these goals collide, and university administrators will inevitably offend a party regardless of the decision they make. For example, how do universities foster safe learning environments, yet allow freedom of expression? How do they honor the generosity of certain benefactors, yet denounce their immoral stance on slavery and segregation? For the most part, scientists have sat on the sidelines of these debates. Scientists and scientific organizations have not been directly charged with racial insensitivity and it would be easy for us to say that this is a social problem that has very little to do with our disciplines. But science cannot be isolated from its social and cultural context and it is obvious that African Americans and Latinos are underrepresented in science. All scientists, ranging from social scientists to natural scientists, can contribute their expertise to this discussion.
Science informs and shapes much of the debate in the public square. Bureaucrats rely on scientific knowledge to guide policy decisions and the media often report on the latest discoveries to inform the public on pressing issues. In the current racially charged environment, scientific expertise can quell tensions and elucidate underlying forces that cause many of the apparent social problems. First, scientists need to disseminate research on stereotypes, prejudice, and implicit bias. For example, they can show that some of the traditional views about consciousness and volition are incorrect. A simplified view of human will is that we have conscious intentions and a person is able to rationally act upon them. The science on stereotypes, implicit bias, and rationality challenges these beliefs and shows that implicit biases can contradict conscious intentions and that humans display preferences at subconscious levels. The thought that our unconscious biases exert such strong influences on our behavior seems to grate against a commonly held belief that people have freedom and choice to act. As a result, scientists should continually remind the public and other scientists that we are subject to implicit biases.
In the current racially charged environment, scientific expertise can quell tensions and elucidate underlying forces that cause many of the apparent social problems.
Implicit biases are exposed in a variety of ways, but often they are revealed in nondeliberate and spontaneous actions, such as giving someone less eye contact or avoiding sitting next to a person at a meeting or social event. These are subtle actions, but they signal fear and discomfort. If someone has an implicit bias against a certain race or gender, then that person is less likely to show warm, unplanned actions towards the biased group.
Though the scientific literature since the 1980s has shown the prevalence of implicit bias, there are still many myths about it. Some say implicit bias does not exist or that only racist, sexist, or homophobic individuals have implicit bias. Another myth is that implicit bias is impossible to change so there is no reason to address the issue. However, research has shown that implicit biases can slowly change through interventions such as intergroup conflict training and counter-stereotype examples. Scientists need to discuss this research with the public and debunk the myths about implicit bias so that society can have more productive conversations about race. Scientists can explain that possessing implicit biases does not make an individual a “bad” person, but rather it is a cognitive shortcut that allows people to make quick decisions. Implicit biases help humans survive in a world with constant streams of information. Without biases, we would not be able to function in a complex world. The downside to this dependence on cognitive shortcuts is that they are prone to error, misjudgments, and false stereotypes. Fortunately, over the past few months, there is an ever-growing discourse by scientists in public forums such as National Public Radio and the New York Times that explain the nature of implicit bias and the effects it has on society.
In addition to participating in the public discourse of implicit bias, scientists must be on the lookout for racism within the profession. Science professionals are not immune from holding racist views and conducting racially insensitive research, yet many scientists believe that science is bias-free because the researcher makes judgments based on facts. There are classic examples, like the Tuskegee Syphilis Experiment, in which scientists allowed untreated syphilis to persist in African American males to study the effects of the disease. The participants were not told the full extent of the study and they were not given penicillin after it became available. The “well-meaning” scientists committed a grave injustice in the pursuit of knowledge. The researchers’ inaction potentially led to the death of over 100 black men and the further spread of syphilis. The scientific community has learned from some of these mistakes and set up mechanisms, like the Institutional Review Board, to protect research participants, but science professionals should not believe that they have solved all of the problems of racial injustice in science. Mistakes like the Tuskegee Experiment may not happen again, but other issues will arise. For example, minority populations may have fewer chances to participate in scientific experiments because it is more costly and difficult to recruit this population. As a result, the benefits of research in areas such as personalized medicine may not accrue to minority populations, which can lead to further marginalization of disadvantaged populations. The lack of minority participation in scientific experiments is well documented in biomedical sciences and unless scientists make concerted efforts to develop inclusive scientific studies, research studies could perpetuate racial inequality.
Parallel to the problem of the lack of diversity in research topics and subjects, scientists must confront racism that affects the nature of scientific inquiry. One of the Mertonian norms of science, universalism, says that the merits of a scientific discovery should be based only on the discovery itself and not on socially defined characteristics, such as the race, culture, and gender of the discovering scientist. Yet, philosophers of science have shown that science is not as neutral and independent as the profession portrays. Rather, society’s unequal power dynamics easily invade scientific reasoning to further marginalize minorities, despite individual scientists fighting against racist ideals. Scientists carry biases with them when they judge the merit of discoveries, review proposals, and hire faculty, and, therefore, it is hard for them to uphold the standards of universalism. To make matters worse, the systems to mitigate biases, like peer review, have flaws that allow favoritism and discrimination to creep back into the scientific process. For example, a reviewer may have an unconscious bias against foreign scholars or individuals in certain academic circles. Many of the biases unfairly affect minority scholars and prevent them from disseminating their research, building scientific careers, and conducting fruitful research. Recently the former editor of Science, Marcia McNutt, wrote an editorial piece about implicit bias in the peer review process and how it hinders diversity in scientific publishing. She suggests using blind peer review mechanisms and diversifying the reviewers and editors of journals.
The current racial tensions in the United States are not solely the problem of police or university administrations and scientists cannot complacently allow other parts of society to wrestle with these difficult questions.
We also see failures of universalist principles in science when we consider the lack of diversity of the science, technology, engineering, and mathematics (STEM) workforce, despite decades of research and programs to combat inequality. Students who are poor and from an underrepresented minority group have almost no chance of attaining a higher education degree in a STEM field. In addition, scientists and faculty from underrepresented groups face unique hurdles developing scientific networks, earning promotions, and obtaining grants. Studies show that underrepresented minorities (URM) feel disenchanted with the promotion and tenure process and have higher exit rates from academia than non-URM. In 2013, fewer than 4% of science, engineering, and health doctorate holders at universities and four-year colleges in the US were black. In comparison, black Americans are about 13% of the US population. The lack of a diverse scientific workforce hurts scientific competitiveness and decreases the range of ideas. Improving URM participation in academia is one of the demands of the recent university protestors across the United States. Scientific institutions need to find more ways to increase diversity and reverse many of the negative trends in the scientific workforce.
The current racial tensions in the United States are not solely the problem of police or university administrations and scientists cannot complacently allow other parts of society to wrestle with these difficult questions. Scientists can add to the discussion by helping people understand the nature of bias and that scientific institutions are culpable of their own racial injustices that impact education, research, and the quality of life for people. Scientists should work toward building and reforming institutions so they promote diversity and fairness. They can encourage their professional societies to make statements repudiating racism and promoting double-blind review processes to minimize implicit bias in the scientific process. They should improve the hiring, firing, and tenure process to make it more inclusive. Providing scientific expertise and implementing reforms will not erase racial inequality, but it does allow scientists to work toward a more just and equal society.
Electric Vehicles: Climate Saviors, or Not?
There are several reasons to support the growth of electric vehicles (EVs) worldwide, but one of the most compelling is its potential to reduce greenhouse gas emissions that emanate from petroleum-driven vehicles. Projections of the growth of EV use over the next 25 years vary widely, due largely to uncertainties about the development of batteries to propel the electrical systems. If new batteries can be produced that have significantly more energy density and at lower costs, the future of electric vehicles is bright. New EVs, such as the Chevy Bolt and Tesla Model 3, which are scheduled for market introduction over the next couple of years, provide some cause for optimism, but the road ahead is still uncertain.
Uncertain developments, however, need not prevent us from examining our current understanding of how EVs will affect climate change. Some EV makers (for example, Nissan, with its “zero emission vehicle” slogan for its Leaf model) want us to believe that since no emissions emanate from the car itself, there is no negative impact on the environment whatsoever. That notion has been widely debunked, and the only remaining question is how much of a climate impact the vehicles do have. Numerous studies have sought to carefully answer the question, but there is no simple answer.
My analysis here can be divided into three levels. The first is the international level, based on country-specific data. The major factor determining the scale of the impact from electric vehicles is the carbon intensity of a country’s electrical grid. The more carbon intensive the grid (primarily due to the burning of coal), the less effective EVs will be at reducing carbon emissions. The second level focuses on intra-country electricity-generation patterns. Few countries get their electricity from a single grid, so it is important to look at the variation across geographical scales. Studies done in Canada and the United States reveal considerable regional variation in electric-generation sources. The third level of analysis is the temporal dimension, which is the time of year and time of day that owners charge their vehicles.
If new batteries can be produced that have significantly more energy density and at lower costs, the future of electric vehicles is bright.
These analyses make it clear that the widespread introduction of EVs, by itself, is insufficient to lead to reduced carbon emissions from the transport sector. Electricity grids need to incorporate greater levels of clean, renewable energy. Equally important, and less understood, electricity providers must incentivize public recharging of EVs when renewable energy generation is at its peak. As will be seen, this is not currently the case, at least in the United States.
It is important to clarify which vehicles are considered EVs. In these analyses, EV is a generic term to describe both pure electric vehicles (often labeled Battery Electric Vehicles or BEVs) and plug-in hybrid electric vehicles (sometimes referred to as PHEVs). BEVs use batteries as the only source of power to the electric motor driving the vehicle. The Tesla is the best known example. PHEVs have both an electric motor and an internal combustion engine. PHEVs can be distinguished from hybrid electric vehicles (HEVs) by their ability to travel a significant distance on battery-generated power alone. HEVs, such as the well-known Toyota Prius, are not included in the definition of EVs because their battery systems are relatively small, require no owner plug-in to the electrical grid, and serve solely to assist the internal combustion system in obtaining better gasoline mileage rather than supplanting it.
The international picture
The global inventory of operating EVs, as of the end of 2015, totaled just over 1.25 million. The optimists point out that this represents a huge increase from the beginning of the decade, when there were virtually no EVs on the road and prospects for future growth were uncertain. The pessimists counter that although the number seems large in isolation, it still represents a miniscule portion of the personal vehicle inventory, no more than 0.1% of all such vehicles. Advocates of either perspective can agree that there is no hard evidence to support either outlook because we are still at the earliest stages of the technology adoption life cycle.
According to data published by the International Energy Agency (IEA), the growth of EVs globally has been quite uneven. Five countries (China, Japan, the Netherlands, Norway, and the United States) are home to about 1 million EVs, roughly 80% of the total. The United States is the largest home, with something more than 400,000 EVs. President Obama, at the beginning of the decade, had projected that the United States would have 1 million EVs on the road by the end of 2015, but he was clearly in the optimistic camp. Although the United States was the pioneer in EV development, ownership growth rates are higher in other countries. China, currently number two on the list of EV owners with more than 300,000 vehicles, will likely soon overtake the United States. The Chinese government is making a major push to increase EV ownership, offering multiple incentives for individuals and organizations to purchase such vehicles. The pace of EV ownership is also picking up in other countries, and the global total will likely exceed 2 million vehicles in 2017.
Knowing where these cars are helps calculate their impact on climate emissions. The IEA reports the carbon intensity of national grids in grams (g) of carbon dioxide (CO2) per kilowatt hour (kWh), which can then be used to gauge emission rates for that country’s EVs. The IEA has also calculated that when EVs receive electricity with emission levels exceeding 559 gCO2/kWh, they, unfortunately, are net contributors to climate change when compared with conventional vehicles. Other studies claim that the IEA’s calculation is too conservative, and that the threshold for climate improvement might be as high as 640 gCO2/kWh. For the purposes of simplicity, however, I will use the IEA number for comparative purposes.
The latest global data on the carbon intensity of electricity grids is from 2013. In general, carbon intensity has been declining, but the difference from 2013 will not be dramatic in most countries. The carbon intensity for the countries with the most EVs is a very mixed picture.
From Figure 1, we see that the use of EVs in the United States should, on average, have a slightly positive effect on reducing carbon emissions. And the 2013 level is an improvement from the 2009 level of 529 gCO2/kWh. With the significant post-2013 reduction in coal use, we can expect that the 2015 level will be even lower. On the other hand, Japan is moving in the opposite direction. With the closure of approximately 50 nuclear power plants in the wake of the Fukushima accident, EV use now marginally contributes to climate change.
The situation in China is worse. With coal comprising approximately 70% of China’s electricity generation, the carbon intensity of the grid is high. China has made bold climate pledges, but evidence on the ground today is mixed. It has the most ambitious renewable energy program of any country, but, at the same time, continues to build new coal-fired plants. The fact that China is likely to have more EVs than any other country by the end of 2016 provides little cause for cheer among those concerned about climate change.
Norway demonstrates the opposite extreme. The carbon intensity of its grid is extraordinarily low due to the overwhelming presence of hydroelectric power. Because of the government’s generous incentives for purchase, EV ownership per capita is higher than anywhere in the world. Approximately 30% of all new vehicles sold in Norway during the last quarter of 2016 were EVs.
At the international level, therefore, the evidence is mixed. In some cases, EVs reduce CO2 emissions, and in other cases, they actually result in more carbon emissions than would conventional vehicles. But if countries diligently work to decarbonize their electricity grids, the outlook will be much more promising than today’s evidence suggests.
A closer look within countries
Country-level numbers reveal that the carbon intensity of electricity varies widely among regions. Because EV ownership also varies significantly by region, the emissions impact of EVs could also vary by region. This can be seen most starkly in Canada.
In some cases, EVs reduce CO2 emissions, and in other cases, they actually result in more carbon emissions than would conventional vehicles.
According to the IEA, the carbon-intensity of Canada’s national grid is 158.42 gCO2/kWh, which is certainly cleaner than most national grids, due especially to the dominance of hydroelectric power. Four of the 10 Canadian provinces, however, generate their electricity from grids that produce carbon at about the 559 gCO2/kWh threshold for climate improvement; the other six provinces had emissions closer to Norway’s. The question is whether Canadian EVs are being driven in the cleaner or the dirtier provinces, and here there is good news. Approximately 95% of the EVs purchased to date are found in just three provinces—Ontario, Quebec, and British Columbia—all of which are low-emitting provinces.
In the United States, the rise of cheap natural gas is likely to continue to drive down the overall carbon intensity of grid electricity. Between 2013 and 2015, coal use dropped from 40% of all electricity generated to 34%, and plans for the next five years involve even more significant numbers of coal plants being shuttered. So the overall trend is positive.
As of 2013, there is considerable heterogeneity within states and regions with respect to the average carbon intensity of their electricity. Idaho has the cleanest electricity (153 gCO2/kWh) and Montana the dirtiest (1,018 gCO2/kWh). We have excellent data for EV sales and ownership, so it is not difficult to match EV sales to state carbon levels.
The top 11 states for EV sales possess 80% of all EVs. This finding is strongly influenced by the state of California, which contains nearly half (48%) of all EVs. There are multiple reasons for the preponderance of sales in California, including a temperate climate, generous purchase incentives, a liberal political philosophy, and the largest selection of EV models made available for purchase because of the state’s zero energy vehicle mandate, which pressures all automakers to sell clean vehicles. Fortuitously, California’s electric grid is one of the cleanest in the country. Overall, the top 10 cleanest states in the United States possess 60% of all EVs, while the bottom 10 possess only 3%.
In summary, an analysis of intra-country data provides a more positive picture of EV development than what we derive from country data. But we need to drill even deeper to acquire a fuller picture, and we do so by examining temporal issues.
Time matters
The data and findings presented thus far have been based on average CO2 intensity numbers. We know, however, that releases of CO2 to the atmosphere from EVs are dependent on the season of the year and the time of day EV batteries are recharged. Several studies have attempted to account for these factors.
EVs do not perform as efficiently in cold weather as they do in moderate temperatures. This effect is, in part, the direct impact of cold temperatures on battery performance and, in part, the need to provide heating for the vehicle occupants. In conventional automobiles, engine heat is used to warm the inside of the car. In EVs the battery must be used to produce heat, which it usually does through inefficient resistive heating. We would expect, therefore, that EVs in the northern US states would require more electricity than average to operate (though conventional automobiles also suffer efficiency losses in colder climes). As noted previously, since nearly half of all EVs today operate in the primarily moderate climate of California, the overall losses due to seasonal variations are not major.
The more serious temporal issue has to do with the times of day when EV owners recharge the car’s batteries. Utilities use different sources of energy during the day and night to produce the electricity that reaches consumers, and these patterns of generation are not random. To achieve maximum carbon reductions, it is important, therefore, that EV owners charge their cars at times when low-carbon electricity sources are being used. Using average emission factors does not capture this important temporal dimension.
Energy analysts seek to account for this factor using what is termed “marginal emissions intensity,” that is, the likely CO2 emissions produced when electricity demand from EV recharging is added to the grid. In effect, it is the matching of EV recharging with the kind of electricity being produced at that time. Although not random, marginal emissions are not easy to calculate because each utility is unique, having its own basket of resources available to produce electricity. Nonetheless, important generalizations can be made with respect to EV recharging patterns and the marginal emissions that result.
We know, for example, that roughly 85% of all recharging takes place at home and this is usually done overnight. EV owners use as much as four times more electricity during the night than do typical Americans.
Utilities tend to encourage EV owners to charge overnight since it has capital infrastructure that is not being used then. Approximately 30 US utilities now have special nighttime rates for EV owners. For example, EV owners and other customers of Georgia Power can obtain rates as low as 1.4 cents/kWh if they charge during the nighttime; they are billed 20.3 cents/kWh for charging during peak electricity periods. Consequently, it is a win-win proposition for the consumer and the utility. The consumer takes advantage of very inexpensive electricity and the utility gains revenue from otherwise downtime operations while reducing stress on the grid system during times of peak demand.
EV owners use as much as four times more electricity during the night than do typical Americans.
Unfortunately, these patterns adversely affect emissions. A number of studies examining overnight recharging and marginal emission factors have concluded that this practice produces higher than average CO2 emissions and, when combined with colder temperatures, may make EV operation in the upper Midwest a net contributor to CO2 emissions. Even in relatively clean states, such as California, the difference in CO2 emissions from nighttime to daytime can be significant. The nighttime start-up of coal plants in response to the additional electricity load from EVs increases marginal emissions. And, of course, clean solar energy is not available at night. As one study has explicitly stated, there is a “fundamental tension between electricity load management and environmental goals.”
From analysis to practice
We need a merger of new policies and advanced technology to resolve this conundrum. Certainly the growth of renewable power in electricity generation provides an opportunity to synchronize battery recharging with clean power. Regulatory agencies and major power producers need to be cognizant of these new resources coming on line and restructure rates to promote recharging during peak periods. Where solar energy is plentiful, providing incentives for workplace recharging would make sense. In some cases, such as with the prodigious amount of nighttime wind power in Texas, overnight recharging could remain the option of choice.
Greater public resources need to be devoted to large-scale electricity storage and to making new forms of EV recharging possible. With the advent of large-scale electricity storage, it may be possible in the future to completely sever the temporal link between generation and consumption. Storing clean energy and later releasing it at will could make EV use a truly clean enterprise. Even before the advent of large-scale electricity storage, new forms of charging EVs could be encouraged, such as wireless or inductive recharging that would give EV owners more flexibility in when they charge. These forms of recharging hold the potential for entirely new recharging behavior, which would make EVs a feasible option for many more drivers.
Governments and electricity generators can also promote the distribution of innovative recharging stations that can, through the advancement of sophisticated software, source the cleanest electricity production in real time and configure the recharging process on that basis. Start-ups such as WattTime and eMotorWerks are pioneering this technology, which could reward consumers for drawing on the cleanest electricity possible. Sonoma Clean Power, for example, has agreed to distribute 1,000 of these charging stations (called JuiceBox Pro) free of charge to its electricity customers and EV owners.
In summary, currently EVs can be climate positive or climate negative depending on where they are located and when they are recharged. As demonstrated in this analysis, EV ownership is taking place in some regions where there is a concurrent growth in the use of renewable energy. That is the good news. As EVs grow as a percentage of sales, however, they will inevitably spread to regions with grids that are more carbon intensive. This is the story right now in China, where the electric grid is still very carbon intensive.
In a world that needs to quickly reduce its greenhouse gas emissions to avoid the worst consequences of climate change, the transport sector remains, perhaps, the most significant technical challenge. The promise of EVs points to one important avenue of progress, but as I have shown, rising EV sales must be synchronized with renewable energy growth. As well, conscious efforts must be made to synchronize battery recharging with the temporal peculiarities of renewable generation, which themselves will vary from region to region. The advent of electricity storage may be the ultimate answer to this need, but until storage becomes economically viable, the challenge is to find ways to encourage recharging when renewable sources are providing the power.
Unlocking Clean Energy
Confronting climate change will require transforming the world’s energy systems to slash their greenhouse gas emissions. Although temperatures continue to rise at an alarming rate, some observers argue that increasing global investment in clean energy signals progress. But gushing investment flows to deploy existing clean energy technologies obscure a discouraging countercurrent: investment in new, innovative technologies has slowed to a trickle. For example, investors around the world spent nearly $300 billion in 2015 to deploy clean energy technologies that already exist, more than tripling annual investment from a decade ago. But between just 2011 and 2015, venture capital (VC) investment in companies developing new clean energy technologies fell by more than 70% to less than $2 billion. Silicon Valley VCs, having lost over half their money from a flurry of failed investments between 2006 and 2011, remain reluctant to invest in clean energy technologies that do not resemble software apps.
This is alarming. Advanced technologies—including energy-dense batteries, safer nuclear reactors, and dirt-cheap solar materials—will be essential to a low-carbon transition that avoids slowing the world economy while proceeding at the scale and speed required to confront climate change. But the widening investment gap between deployment and innovation endangers prospects for improving the performance and reducing the cost of clean energy. And by overemphasizing deployment, policy makers can tilt the playing field against emerging technologies, which are at a disadvantage to begin with. Because commercially mature clean energy technologies get incrementally better as producers and users gain experience with them, policies that favor technologies available today may erect barriers to market entry for advanced technologies tomorrow.
The result is “technological lock-in,” a syndrome endemic to markets in which the next technology generation cannot replace the existing one. Nuclear power provides a clear example of such lock-in. The prevalence of light-water reactors (LWRs) today, largely a result of United States military and regulatory policy favoring that particular design, poses nearly insurmountable entry barriers to next-generation nuclear designs that could offer safety, cost, and performance advantages. Three other clean energy “platforms,” or technological categories—biofuels, solar photovoltaic power, and batteries—are at risk of succumbing to lock-in. In these platforms, new technologies face economic barriers to competing with incumbent clean energy technologies, an uphill battle that is exacerbated by public policy.
But two other platforms—wind power and efficient lighting—exhibit healthy technological succession rather than lock-in. And these success stories can inform public policies that mitigate, rather than exacerbate, the risk of technological lock-in.
Causes and consequences of lock-in
Economists have long known about technology lock-in. The first step toward lock-in is the emergence in the market of a “dominant design,” a technology that captures a majority market share and becomes the incumbent technology. For example, almost every car made in the past century has run on an internal combustion engine (ICE), the dominant design for vehicle propulsion. Dominant designs can emerge for a variety of reasons unrelated to technological merits. In the engine example, neither the steam engine nor ICE was clearly superior in the early twentieth century. But then hoof-and-mouth disease led New England authorities to eliminate the watering troughs that horses and steam engine vehicles alike used, a chance event that helped put steam engines at a disadvantage. Similarly, even though early ICE-powered vehicles were fouler, noisier, and more dangerous than electric vehicles, ICE firms made the shrewd business decision to sell their vehicles as consumer products rather than offer taxi services, and they benefited from existing distribution systems for petroleum products. After racing to a quick lead, the ICE did not look back for the next century.
Once a dominant design emerges, firms that produce it can entrench their market positions through scale. As they increase production, they can improve the performance and decrease the cost of products—for example, through production economies of scale and “learning-by-doing.” And as firms sell products to a growing market, increased adoption can drive down the costs of using the product and increase its value—for example, through network effects. These economic benefits create barriers to entry to firms marketing new technologies, which do not have the benefit of scale.
As a market matures and firms producing a dominant design grow, those firms may not invest much in research and development (R&D) to create fundamentally new products, because a substantial fraction of the benefits from R&D are “spillover benefits.” R&D investment by one firm may, for example, advance scientific knowledge that other firms can then leverage. Therefore, these benefits are externalities from the perspective of a firm sponsoring R&D. As a result, private industries will often underinvest in R&D, instead investing in incremental process innovation that fortifies the incumbency of mature technologies.
One might conclude that government intervention is the answer, perhaps by filling the R&D investment gap left by the private sector. But often, government intervention can actually distort markets even more, further tilting the playing field toward incumbent technologies.
For example, governments may enact regulations that are tailored to the characteristics of an existing technology, often following the emergence of a dominant design. Intentionally or not, this bespoke regulatory structure can disfavor new technologies around which the regulations were not designed. As a case in point, in 1937, New York City implemented a system of requiring taxi drivers to purchase medallions, which authorized drivers to transport passengers, as a quality control measure. This decision did not forecast the recent rise of car-sharing mobile apps, such as Uber, and, as a result, the regulatory framework disadvantages a new, and arguably superior, technology that achieves quality control through user reviews.
Public policy can also obstruct new technology adoption by providing subsidies and other incentives to mature technologies, raising the entry barrier that natural economic forces already help erect. Policy makers may intend for their policies to be technology-neutral, but even a neutral policy can implicitly support existing technologies at the expense of emerging ones. This is the case for policies around the world that support renewable energy, including “feed-in” tariffs that compensate renewable power generation at a premium rate and standards that require utilities to obtain a certain percentage of their power from renewable energy. Because mature technologies can be rapidly deployed to take advantage of such policies, they can crowd out less mature technologies. This effect is pronounced when mature and emerging technologies compete for a cordoned-off market with limited capacity, in which deployment of one comes at the expense of the other.
Successfully advancing clean energy innovation requires two categories of drivers. First are “demand-pull” drivers—for example, a price on carbon—which create favorable market conditions to sell low-carbon technologies to consumers. But a primed market alone is often insufficient to induce innovators to make risky investments in developing new technologies. So a second category, “technology-push” drivers, is needed to catalyze innovation through direct support for technology development and for demonstrations of new technologies at scale. Policy makers who only adopt a demand-pull strategy will not only fail to stimulate innovation but could actually discourage it if their policies end up deploying mature technology, enabling incumbent learning that raises the market entry barrier to emerging technologies. Moreover, such a policy approach can create powerful political constituencies in support of a particular clean energy technology and opposed to technological succession.
Finally, lock-in is most likely to occur in “legacy sectors,” in which entrenched market structures and risk-averse actors discourage innovation. This is particularly true for energy. Indeed, lock-in is most common regarding fossil fuels, as behemoth incumbents such as major oil companies are well positioned to arrest a clean energy transition. But lock-in within clean energy is also driven by similar dynamics between incumbents and upstarts. For example, electric power utilities in the United States are very risk-averse, and as a major customer of renewable energy, they are likely to prefer mature technologies with extensive field experience. Another feature of legacy sectors is that disruptive products must be immediately competitive with market incumbents. So unlike the computing sector in the 1980s—when Apple sold the Mac Portable for over $13,000 (in 2016 dollars) but could attract customers because it was creating a new market—power from renewable energy must compete with power from fossil-fueled sources for market share. As a result, the playing field in legacy sectors such as energy is even further tilted against new technologies.
Lock-in landscape
Nascent in some cases and entrenched in others, lock-in is already deterring innovation across a range of clean energy technology platforms.
Nuclear energy. Energy from nuclear fission is the clearest example of an energy platform mired in technological lock-in. Since the late 1950s, one type of nuclear reactor—the light-water reactor, which uses water to cool and moderate nuclear fission—has dominated global deployment of nuclear reactors. Although the economic benefits of scale were not central to the popularization of LWRs—the cost of building a reactor has actually increased over time—US public policy ensured that LWRs would dominate the world’s nuclear fleet. But today, as nuclear’s share of global electricity dwindles, the lack of diversity in nuclear technology is hampering efforts to deploy safer, cheaper, and more efficient nuclear reactors.
The nuclear LWR got its big break from the US Navy. In the decade following World War II, then-Captain Hyman Rickover set out to develop a nuclear submarine that would have virtually unlimited range. At the time, the nuclear research community was far from consensus on the best type of nuclear reactor, and over 10 candidate designs were still considered viable. Rickover picked a short list of three reactor types, rapidly tested two of them, and decided to deploy LWRs across the submarine and aircraft carrier fleets. But even though a different reactor design may have been optimal for civilian use, Rickover chose to leverage naval expertise to make the first land-based nuclear reactor an LWR, giving the technology a decisive head start. From there, General Electric and Westinghouse built LWRs at home and abroad—leveraging federal assistance—to demonstrate US superiority in nuclear technology, halt proliferation of nuclear fuel (LWRs do not use weapons-grade fuel), and prevent the Soviet Union from winning over nonaligned countries with cheap nuclear power. Today, LWRs account for around 90% of all nuclear power capacity, and only Canada, Russia, and the United Kingdom have substantial power generation from alternative nuclear reactor designs, having resisted the US-led LWR campaign.
Within the United States, nuclear regulations passed in the 1970s cemented the dominance of LWR technology because regulations tailored to LWR reactors were ill-suited for alternative designs. These regulations allowed a firm to build duplicate plants and reuse major components without restarting the approval process each time. As a result, not only did all new domestic reactors use LWR technology, but each manufacturer’s reactors began to homogeneously resemble a single, standard design, a de facto requirement to build reactors quickly and affordably. Since then, commissioning and constructing an alternative reactor design to the LWR has remained extremely difficult. And LWRs have faced their own steep obstacles, including construction delays, cost overruns, declining revenues in power markets, and political opposition from environmental and other constituencies. As a result, reactors are closing at a faster rate than new ones can be built.
This is unfortunate, because nuclear power is a more reliable power source than other zero-carbon sources, such as wind and solar, and because promising alternative designs have existed for decades. For example, post-LWR designs, called “Generation IV reactors,” incorporate passive cooling systems that are much safer than the active cooling systems in existing LWRs, such as those that failed to prevent reactor meltdowns in Fukushima in Japan and on Three Mile Island in the United States. Moreover, alternative designs can be more efficient and enable modular construction approaches, reducing the cost of nuclear energy. Although these designs originated in the United States, China and Russia are investing heavily in commercializing Generation IV designs, with Canada, France, Korea, Japan, and the United Kingdom on their heels. If they succeed, US competitiveness in the nuclear industry will suffer, though global prospects for clean energy may improve. Still, after a half-century of technological lock-in, the odds are long for successful commercialization of new nuclear reactor technologies.
Biofuels. Similarly to nuclear energy, biofuels face hurdles to technological change because of public policies that have cultivated a dominant design and could tilt the playing field against emerging technologies vying for a share of a limited market. As a potential “drop-in” replacement for petroleum fuels, biofuels hold promise to reduce the carbon intensity of the transportation sector without requiring the major infrastructure changes that electric or hydrogen powered vehicles might require. However, the first generation of biofuels, which offer limited climate benefits and distort other sectors of the economy, continues to dominate the market to the exclusion of a preferable, second generation of biofuels.
The most common first-generation biofuel is ethanol, produced from corn in the United States or sugarcane in Brazil, which can then be blended into gasoline to fuel existing gasoline engines. Sugarcane ethanol has a considerably lower carbon footprint than US corn ethanol. But both corn and sugarcane ethanol displace agricultural activity, raise global food prices, and can deplete the supply of natural resources, such as water, for other uses. By contrast, second-generation ethanol—produced from the waste products or inedible parts of plants—could deliver greater greenhouse gas savings with fewer damaging side effects. Cellulosic ethanol is a promising but elusive class of second-generation biofuels. In 2015, the United States consumed just 2.2 million gallons of cellulosic ethanol, compared with 13.7 billion gallons of first-generation ethanol. However, prospects for cellulosic ethanol remain dim because of low investment in R&D and in the production facilities for advanced biofuel plants.
Over the past decade, US public policy has spurred a more than three-fold increase in domestic consumption of first-generation biofuels, making the United States the largest biofuel consumer in the world. And because US policy preferentially supported domestic production, the nation’s corn ethanol producers reaped $20 billion in tax credits from the federal government from 2004 through 2010. In addition, Congress in 2005 established the Renewable Fuel Standard program mandating that from that year onward, refiners blend rising volumes of biofuels into conventional petroleum fuels each year through 2022. Although the policy set minimum quotas for both first- and second-generation biofuels, it has so far resulted almost exclusively in increasing volumes of corn ethanol in the US fuel supply.
The amount of ethanol in the US gasoline supply has now reached 10%, a threshold known as the “blend wall.” Fuels that blend more than 10% ethanol may not be compatible with the older segment of the existing vehicle fleet. Therefore, the US biofuels market is now a cordoned-off market that pits first-generation against second-generation biofuels in a constrained market. Although the US Environmental Protection Agency has suggested that its future mandates might breach the blend wall, continued uncertainty over whether cellulosic ethanol will have to compete directly with corn ethanol may further chill the struggling cellulosic ethanol industry.
Still, there are some advantages from adoption of the first-generation fuel that could carry over to subsequent fuels. In the United States, widespread use of corn ethanol in the fuel mix has resulted in increased infrastructure for biofuels around the country (for example, storage tanks for ethanol at fueling stations). Moreover, newer cars are being equipped to tolerate more ethanol in the fuel mix than the 10% blend wall, and some vehicles, known as “flex-fuel” vehicles, can use up to 85% ethanol fuel.
Despite progress on the infrastructure front, prospects for decarbonizing the transportation sector with biofuels are dim because of the dominance of corn-based ethanol. The biofuels example demonstrates that even well-intentioned public policy, such as the federal Renewable Fuel Standard, can backfire by implicitly supporting a mature technology over an emerging competitor. And it is a cautionary tale for policy makers seeking to create political constituencies for clean energy through public deployment support. For although the architects of the fuel standard may have intended to foster both first- and second-generation biofuel industries, they unleashed a powerful lobby for first-generation biofuels alone, whose political sway is on display every four years in the Iowa presidential primary.
Solar energy. Although public policy has been the principal driver of entrenching incumbents in nuclear energy and biofuels, both economic and policy causes are needed to explain the technological stagnation of solar energy. Today, the first-generation solar photovoltaic (PV) material, silicon, accounts for over 90% of the solar PV market, even though the technology is more than 60 years old. Although silicon solar panels have recently plummeted in cost, enabling rapid market expansion, it is unclear if silicon solar can improve enough on cost and performance to materially displace fossil fuel-based power from coal and natural gas.
Silicon solar exemplifies the economic advantages of incumbency: as its production has grown, its costs have predictably fallen. Silicon solar quickly became the dominant design in the second half of the twentieth century because the solar industry was able to adapt the equipment and manufacturing processes used in the fast-growing semiconductor industry to instead produce silicon solar panels. Then, from 1978 to 2015, the real cost of a solar panel declined from $80 per watt to below $0.50 per watt, or around a 24% drop in cost for every doubling of cumulative production. Much of this decline was due to public and private R&D. But as silicon technology has plateaued in recent years, the cost improvements have been dominated by “learning-by-doing,” as producers incrementally improved the manufacturing processes and performance of silicon solar panels. In addition, as the adoption of solar in a particular market has increased, all of the “balance-of-system” costs (for example, installation, equipment, labor) that exclude the physical solar panel have also decreased as companies get better at deploying solar. For example, over the past five years alone, the balance-of-system cost for installing solar in the United States has halved and is projected to decrease 85% over the next 15 years.
In addition to the economic advantages conferred by learning, silicon solar has benefited from public policies focused heavily on the deployment of renewable energy. Through 2015, Germany alone had spent over $66 billion to support the deployment of solar power. And whereas Germany is presently scaling back support for solar, other countries, including the United States, China, and India, are aggressively extending policy support for solar. For example, in 2015 the United States extended its 30% solar tax credit through 2021, at a projected cost of nearly $10 billion. None of these policies distinguishes between mature and emerging technologies; as a result, subsidies have indirectly supported the deployment of silicon solar.
More directly, the Chinese government lavished financial support for silicon solar produced by local industry. From 2010 to 2011 alone, the China Development Bank extended $47 billion in lines of credit to major Chinese manufacturers, spurring them to scale up rapidly, even as profit margins collapsed from a supply glut. The flood of cheap Chinese silicon solar panels washed away innovative start-up companies in the United States, many from Silicon Valley. In 2012, the United States began levying tariffs on Chinese panels to countervail below-cost “dumping” of silicon solar panels. But by then the damage to US solar start-ups had been done, and none would go on to achieve significant market share. Recently, the rate of new company formation in solar has plummeted as investor interest in new solar technologies has waned.
Still, given the rapid growth of the solar market and the continued cost reductions of silicon solar, it might appear that no alternative to silicon is really necessary to meet global decarbonization goals. Such optimism is misplaced. Materially displacing fossil-fuel energy from natural gas and coal will require many terawatts of installed solar capacity—over an order of magnitude greater than existing installed capacity. At such a high penetration of solar, the cost target for solar to compete with fossil fuels will likely drop considerably; solar becomes far less valuable to the grid as more of it is installed, owing to the intermittency of sunlight. Energy storage and more responsive electricity demand could shore up some, but not all, of solar’s declining value. Indeed, for solar to provide 30% of global electricity production by 2050, Shayle Kann and I have estimated in Nature Energy that solar will have to cost less than $0.25 per watt, which is over four times lower than current costs. Extrapolating historical learning effects, that figure is simply out of range for silicon solar. And if silicon solar hits a penetration ceiling decades from now and a clear investment case emerges for a superior technology, it may be too late to keep global decarbonization on track.
Given that exciting discoveries continue to emerge from research laboratories, it is premature to conclude that solar PV as a platform is destined for technological lock-in. Devices made from alternative materials to silicon that are abundant, cheap to produce, and highly customizable are close to matching the performance of silicon solar devices. (One particularly promising alternative is called perovskite, a wide-ranging class of materials in which organic molecules made mostly of carbon and hydrogen bind with a metal, such as lead, and a halogen, such as chlorine, in a three-dimensional crystal lattice.) Soon, such alternatives might surpass silicon. However, silicon solar appears to function much more as a barrier than a bridge to the adoption of more advanced technologies. Ever more finely tuned processes to manufacture silicon cells and panels are not transferrable to the radically different (and, theoretically, much simpler) processes to print next-generation solar coatings. Extensive industry experience installing silicon solar panels is mostly irrelevant for future construction projects that may use building-integrated solar materials. And novel financing arrangements—for example, to securitize solar project debt—are emerging because a wealth of operating data from actual silicon panels has allayed investor fears about performance risk, but investors may well be wary of using the same financial instruments with less proven technologies. So even if some industry advances do apply to multiple solar technologies, the rise of silicon solar has mostly reinforced its position as the platform’s dominant technology.
Energy storage. Lithium-ion batteries could follow in silicon solar’s footsteps, amassing the learning benefits of incumbency and posing a barrier to market entry for other energy storage technologies. At present, lithium-ion technology dominates the still-nascent energy storage market, a sector that could be crucial to large-scale decarbonization by enabling electric vehicles and electric grids powered by intermittent renewable energy. But lithium-ion appears to be a suboptimal technology for either application, and superior alternatives may not gain market traction if energy storage succumbs to technological lock-in.
The lithium-ion battery got its start in consumer electronics; Sony commercialized it in 1991 to power camcorders. Since then, laptop and mobile phone applications have driven a dramatic scale-up of lithium-ion production capacity, mostly in Asia. These producers could then build on existing scale to be first-movers into new markets. First, over the past decade they sold batteries to major car companies, such as General Motors and Tesla, which released hybrid and fully electric vehicles powered by lithium-ion batteries. And most recently, utilities and consumers have begun installing lithium-ion batteries to stabilize the power grid and lower electric bills.
In all of these markets, producers of lithium-ion batteries are virtually unchallenged and are amassing the economic benefits of scale. Just as the cost of silicon solar panels dropped, the cost of lithium-ion batteries has fallen by 22% for every doubling of cumulative production since 2010. And in 2016, Tesla opened the first phase of its “Gigafactory” that by 2020 will produce more lithium-ion batteries than the entire world’s production in 2013. Chinese and European car manufacturers are looking to follow suit, suggesting that costs will continue to fall with lithium-ion’s scale-up.
But there are limits to how far a lithium-ion powered car can be driven or how much intermittent renewable energy on the grid lithium-ion batteries can buffer. An affordable car with a 500-kilometer range will require batteries that cost $100 per kilowatt-hour and store 350 watt-hours per kilogram—neither of which is realistic for lithium-ion. In addition, energy storage solutions need to tolerate between three and 10 times more lifetime cycles than lithium-ion batteries to cheaply and reliably stabilize the power grid.
Alternative battery chemistries—such as lithium-air, lithium-sulfur, or magnesium-ion batteries—could theoretically deliver the required performance. But they will need R&D support and private investment dollars to achieve scale. In the meantime, deployment-focused public policy, especially in the United States, might implicitly support mature solutions and further increase their cost advantage over would-be competitors. And with each passing year, the risk of technological lock-in to lithium-ion batteries grows.
Escaping lock-in
Even in energy, the archetypal legacy sector, technology lock-in does not have to be inevitable. In fact, two technology platforms—efficient lighting and wind energy—are on pace for continued technological improvement. These examples offer distinct but related lessons for how to escape technological lock-in.
Efficient lighting. In the early 2000s, US public policy favored compact fluorescent lightbulbs (CFLs) as the preferred alternative to conventional incandescent bulbs. CFLs were five times more energy-efficient and lasted 10 times as long, providing compelling environmental and cost benefits. As utilities and the federal government aggressively promoted them, CFLs reached 20% market share by 2007. But, unexpectedly, CFL market share has since tapered down to 15%, and a rival efficient lighting technology, the light-emitting diode (LED) bulb, has risen to the same market share. LEDs are a superior technology to CFLs. They are more dimmable, more efficient, over three times more long-lasting, and more versatile in their range of colors and sizes. So it is a sign of a functional technology transition that LEDs will continue to gain at the expense of both incandescents and CFLs; General Electric projects 50% LED penetration by 2020 and 80% by 2030.
The ongoing success of this technology transition proves that lock-in to a first generation clean technology is not inevitable, even with the deck stacked against a second-generation successor. As in other platforms, the first-generation technology—CFLs—enjoyed the economic advantages of scale, halving in cost for every doubling of production from 1998 to 2007. And through technology-neutral deployment regulations, government policy implicitly favored CFLs that already had achieved scale. For example, in 2007, Congress passed legislation requiring lightbulbs to be 60% more efficient by 2020—a threshold that both CFLs and LEDs met—rather than rewarding LEDs for being even more efficient than CFLs.
Despite these barriers, LEDs broke into the lighting market through decades of technology development and commercialization in niche, or “stepping-stone,” markets, demonstrating a potential path forward for advanced technologies in locked-in platforms. From 1968 to 1990, LED producers built up experience with the technology by meeting demand for specialized lighting applications, such as electronic displays and indicator lamps. From there, they branched out to larger-scale markets from 1991 onward, taking over traffic signals and vehicle lights. Over a half-century of scaling up, LEDs fell in cost by a factor of 10 every decade, a regularity known as “Haitz’s Law” (a cousin of “Moore’s Law” for integrated circuits). LED performance also improved dramatically as companies such as Philips invested in R&D. And over the 2000s, US government support for LED R&D grew to over $100 million annually, some of which the Department of Energy (DOE) directed toward commercialization, including testing new technologies in real-world conditions through industry partnerships with national laboratories.
Finally, by 2013, producers could manufacture and sell LEDs that emitted warm, white light for $10 a bulb, cost-competitive on a lifetime basis not only with CFLs but with traditional incandescents as well. They will get only cheaper and perform better: by 2020, an LED bulb will cost $5 and produce twice as much light per watt. But it is crucial to remember that LEDs did not appear on the global lighting stage out of nowhere; decades of development and scale-up through stepping-stone markets enabled LEDs to vanquish lock-in.
This lesson may be most applicable to energy storage, a technology platform with an array of applications that rivals the diversity of LED uses. Indeed, lithium-ion technology benefited from a stepping-stone market, gaining scale and experience in consumer electronics before firms applied the technology to electric vehicles and grid-scale storage. If alternatives can also gain scale through a stepping-stone market—for example, by providing back-up power to military bases—then they may be able to compete with lithium-ion on a more level playing field.
Wind energy. As in the efficient lighting platform, wind energy has exhibited consistent technological improvement. But unlike the transition from first-generation CFLs to second-generation LEDs, performance gains in wind have not required paradigm shifts in technology. Instead, they have resulted from consistent and incremental technological progress.
During the 1970s, which saw the first major wind installations, firms tested various designs and quickly settled on the three-blade, horizontal-axis wind turbine, which remains the dominant design today. So in a strict sense, wind energy has experienced technological lock-in; but there are no compelling alternatives being locked out. Compared with the vertical axis wind turbine, the horizontal-axis version is cheaper and more efficient, and three-blade rotors turn out to be more balanced and efficient than two- or one-blade configurations.
As a result of quick industry alignment around the optimal configuration, wind energy was set up for continued incremental progress. For example, from 1999 to 2013, an average wind turbine’s output increased by roughly 260% as firms developed taller towers and longer blades, blade pitch control and variable speed, advanced materials and coatings, sophisticated control systems, and a variety of other electro-mechanical improvements. These upgrades were incremental; having fixed the overall system configuration, firms could then independently develop, test, and commercialize improvements to each subsystem. Looking ahead, the wind sector may yet confront a technology transition as firms invest heavily in offshore wind technology. But this paradigm shift might sidestep lock-in through a series of incremental improvements, including making even larger wind turbines than onshore models and adapting the oil and gas industry’s expertise in floating platform design.
Because incremental innovation works so well for improving the performance and reducing the cost of wind energy, wind may respond differently to technology-push and demand-pull public policies than other technology platforms. For example, a 2013 study from Carnegie Mellon suggests that state-level policies mandating that utilities procure a certain amount of renewable energy actually induced more wind energy patents than public R&D funding did. In other platforms, such as solar power, such deployment-focused policies are insufficient to convince private investors to fund costly R&D and production of alternative materials that are fundamentally different than first-generation solar panels. But in wind energy, firms are willing to make smaller investments in incremental improvements to existing wind turbines that can quickly pay off.
This difference suggests that the wind energy platform is an imperfect guide for other clean energy technology platforms mired in technological lock-in. But the example of wind energy still teaches the important lessons that incremental innovation is much easier to accomplish than an overhaul of the dominant design and that a series of evolutionary steps can ultimately yield a revolutionary product. Some observers have proposed similar paths to enable other technology platforms to escape lock-in. For example, firms miniaturizing nuclear LWRs hope to alter US nuclear regulations to more flexibly assess small modular reactors (SMRs). Although SMRs are evolutionary descendants of the traditional LWRs, a more flexible regulatory regime might reduce the barriers to development of advanced Generation IV reactors. As an incremental intermediary, SMRs could bridge the gap between the locked-in nuclear industry today and improved technologies in the future.
Similarly, the solar industry could transition to more advanced materials through an incremental route. For example, some firms developing solar perovskite coatings plan to layer the coatings on top of existing silicon solar cells to boost the performance of existing solar panels. This way, an upstart technology does not require massive scale to compete with giant industry incumbents; the second-generation technology would piggyback on the success of the first-generation. And once solar perovskites achieve production scale, firms might try to make solar perovskite coatings without the underlying silicon panel, unlocking brand new markets and capabilities for solar.
Marrying innovation and deployment policy
As these diverse examples demonstrate, there is neither a single route to technological lock-in nor any ironclad prescription to avoid it. Nevertheless, public policy should strive to minimize the risk of first-generation technologies stifling competition and maximize prospects for superior successor technologies to enter the market.
Policy makers looking to advance clean energy should begin by following the example of newly minted doctors who swear to “do no harm.” As experience with other energy technologies has shown, well-intentioned public policies that aim to deploy clean energy can backfire by stunting innovation. This can happen when a policy creates a ring-fenced market, effectively pitting current-generation and next-generation clean energy technology against each other in an unfair fight. The Renewable Fuels Standard has created such a situation, now that first-generation corn ethanol accounts for nearly the entire volume of fuel that can be blended into gasoline and still be widely usable by the vehicle fleet. Moving forward, advanced biofuel quotas should increase at the expense of corn ethanol quotas so that the latter does not crowd out next-generation technology with clear public benefits. But this will be politically challenging, because by expanding the corn ethanol industry, the fuel standard has unleashed a political constituency opposed to technological succession.
Moreover, demand-pull policies alone can be insufficient to induce innovation; for example, even with rising advanced biofuel quotas over the past decade, production has remained insignificant. In addition, technology-push policies are a necessary complement. Thus, the Obama administration was right to propose doubling investment in energy R&D to $12.8 billion from $6.4 billion by 2021. Although strong institutions such as the National Science Foundation (NSF) and DOE national laboratories have historically funded and performed energy R&D, these efforts should be modernized as funding expands. Newer institutions such as the DOE’s Advanced Research Projects Agency, which can flexibly set funding priorities for breakthrough technologies, should grow over time.
Still, the federal government is much better at funding R&D than it is at supporting first-of-a-kind demonstration projects or production scale-up, leaving innovative technologies to languish in a “valley of death” without public or private investment. Part of this failure is due to a mismatch in institutions—whereas DOE and NSF reliably underwrite R&D, DOE’s investments in demonstration projects are erratic and politically sensitive. New institutions at the federal or regional levels, or both, are needed to fund demonstration projects and de-risk emerging technologies to embolden private investment in them. In the long term, the United States should redesign its legacy institutional architecture, much as the United Kingdom developed a new set of institutions from scratch to reduce emissions and advance end-to-end clean energy innovation.
Finally, taking inspiration from the example of LEDs crossing the valley of death via stepping-
stone markets, policy makers should use public procurement to provide early markets for emerging technologies that otherwise are unlikely to attract private investment to take on established incumbents. This strategy has been wildly successful in other fields. For example, the military’s semiconductor procurement in the 1960s directly led to the development of the integrated circuit, which revolutionized computing. In the global health sector, governments around the world pooled $1.5 billion in 2007 as an “advance market commitment” for a pneumonia vaccine, succeeding in pulling new drugs onto the market that would otherwise have been unprofitable ventures. Yet another model is the National Aeronautics and Space Administration’s payments to firms such as SpaceX to accomplish milestones toward the ultimate goal of transporting cargo and crew to space and back. Similar approaches could elicit private investment in clean energy technologies that could scale up in publicly guaranteed stepping-stone markets.
In particular, the military could make a compelling case that revolutionizing locked-in technology platforms would advance its objectives. Small modular nuclear reactors could power military bases at home. Lightweight but high-performance solar panels and batteries could offer operational flexibility in the field. And biofuels capable of displacing oil at scale could not only fuel the military’s operations but also reduce the risk of an oil-supply disruption that the military aims to prevent. But for this approach to successfully induce new products, military procurement would have to be carefully coordinated with public funding for earlier stages of technology R&D and demonstration.
In shepherding emerging clean energy technologies from lab discoveries, through the valley of death, and ultimately into commercial markets, policy makers must delicately balance competing goals. On one hand, investors and entrepreneurs need assurances that public policy will support a market for their products down the road. But on the other hand, once a technology achieves commercial maturity, policies to support their deployment need to leave room for the next generation of technology to emerge and compete. Thus, policy makers should enact intelligent deployment policies that dovetail with support for innovation, such as auctions that put a price on greenhouse gas emissions and raise revenue for technology-push policies.
This approach could accelerate financial and business model innovation driven by deployment of existing technology, which, in turn, could make it easier for next-generation technologies to succeed. That must be the guiding logic behind clean energy policy—to transform lock-in barriers into bridges for technological succession.
Take a Deep Breath
Anxiety reigns among the overeducated, the hyper-rational, the super-scrupulous. Academics, think-tankers, and journalists are trying earnestly to understand why so many Americans have lost their respect for intellectual rigor. Hell, there seem to be millions of people gleefully indifferent to facts or truthfulness. What does this mean for those of us who purport to be in the fact and truth business?
It’s not just the election. Donald Trump, even in his most ecstatic paroxysms of narcissism, knows that he does not deserve all the credit for smiting the know-it-alls. But he did recognize before most of us smarty-pants that an enormous slice of the American public has lost faith in the religion preached by the elites: technological progress benefits all, globalization raises all boats, meritocracy is the epitome of fairness, and the world should say Amen for all the benefits that scientists, engineers, physicians, and their partners in progress have delivered.
How can it be that all these people are more willing to believe stories manufactured by twentysomething Russian opportunists than the reporting of the New York Times and the articles in Science and Nature?
As we see the success of bombast and simplification in the debate over a topic such as climate change, it is easy to lose our own faith in rigor and precision. Why not respond in kind? Why quibble about the fine points or reveal our degree of uncertainty? Doesn’t that equivocating just makes us look weak?
The painful reality is that we’re not going to be as influential with government officials for the next few years, but we shouldn’t let that tempt us to take short cuts to win small battles. Instead, we can use this period as a time to get our house in order and reinforce the foundation of reliability and honesty that will serve us well in the long run. People are not stupid, and they will grow tired of promises that aren’t kept and plans that crash because they are built on lies and sloppy thinking. They will wise up to the fact that their credulousness is allowing a few cynical news fabricators to make them look foolish.
But those are the easy victories. There are more insidious challenges to rigor and objectivity that originate closer to home. In his article in this issue, science journalist Keith Kloor reports on the actions of vaccine skeptics, anti-GMO activists, and other educated, articulate, and socially engaged zealots that are so certain of the correctness of their vision that they assume that anyone who contradicts their version of reality, no matter their scientific credentials, must have been bought by some corporate villain. When they escalate their disagreement to ad hominem attacks on responsible science journalists, they make honest reporting a dangerous business.
Daniel Hicks strikes even closer to home in his article on how even university scientists can neglect the evidence when forming their political opinions. In other words, he accuses scientists of behaving like normal human beings. Public policy is a blend of values, ideologies, self-interest, and group affinity as well as factual information. And when scientists engage in public policy debates, they also employ all these perspectives as well as their specialized knowledge and training. The challenge is to be honest and clear ourselves about how we form our opinions. We should learn from the work of Daniel Kahneman, Amos Tversky, and others that a little humility about our own evidence-based rationality is in order.
During what should be a time of self-reflection, we thought it would be useful to present the perspective of those who think deeply about science’s values and its place in society—the philosophers of science. The short article by Robert Frodeman in this issue will be the first of a series of articles that reflect on deep foundations of the scientific mindset and how this is manifested in today’s political debates.
We need to think more about the perspective of those being left behind in an evolving economy. From where they sit, we might look not like the beneficent creators of knowledge but as the clever rationalizers of self-advancement.
The election of Donald Trump will undoubtedly have serious, though still unpredictable, consequences for energy policy, environmental regulation, health care, foreign affairs, trade policy, the Supreme Court, and a variety of other critical issues. But it’s worth thinking about what we would all be thinking if a few tens of thousands of voters in Michigan, Florida, Wisconsin, and Pennsylvania had voted for Hillary Clinton. We would be praising the wisdom of the American voter, celebrating the triumph of the Obama legacy, and recommending our friends for key posts in the administration.
We would overlook the reality that perhaps 45% of voters were so alienated from mainstream sources of information, so distrustful of educated elites, so willing to believe unsubstantiated rumors and fabricated information that they decided to vote for someone who didn’t even pretend to have any knowledge of public affairs or a coherent political philosophy. The extent of the chasm between the intellectual mainstream and a very large segment of the US population would likely have been brushed aside in the flush of victory, just as Trump supporters see no significance in the reality that the majority of Americans voted for his opponent.
But it didn’t turn out that way. It’s a disheartening moment and therefore an invitation to rethink what we do. Stop. Take a deep breath. Think honestly about how expert knowledge invites arrogance, about the self-interest of the meritocratic class, about the conflict that has developed between the old and the new economy, about the limits of our supposedly disinterested rationality. We do have self-interests, and the Trump voters have recognized those interests and come to distrust our pronouncements. The voters know that Trump has interests, but he acknowledges that, even boasts that he’s too smart to pay taxes.
There is no doubt that our universities, our national labs, our health care institutions, and our high-tech businesses have made enormous contributions to the economic strength and overall well-being of the country. But those of us who are part of those worlds have also reaped a significant share of their rewards. We need to acknowledge that and think more about the perspective of those being left behind in an evolving economy. From where they sit, we might look not like the beneficent creators of knowledge but as the clever rationalizers of self-advancement. As we find ourselves on the sidelines of the new administration, we can think hard about how we can do our work more honestly, more selflessly, more usefully. Perhaps a good place to start is to be open to the possibility that we have not always been telling ourselves the truth.
Infrastructure and Democracy
The recent bitterly contested election revealed little common ground between the major parties. Yet President-elect Donald Trump and his opponent Hillary Clinton had at least one shared priority: both agreed that America’s infrastructure was in urgent need of revitalization. Indeed, the nation’s roads, bridges, ports, sewer systems, and more are old, crumbling, and decaying. The American Society of Civil Engineers 2013 “Report Card for America’s Infrastructure” pronounced an average grade of D+ for the nation’s technological backbones with an estimated $3.6 trillion needed by 2020. To make matters worse, Americans are currently devoting less per capita investment to infrastructure than at any time since World War II.
How should the necessary revitalization be pursued? Most analyses of infrastructure consider success to be defined by technological sophistication: bandwidth of broadband Internet connections, gigawatts of electricity produced, or ton-miles of rail traffic. Better infrastructure is simply more infrastructure. Such measures of success are too limited. We argue the most important definition of success for infrastructure is how well it enables all Americans to participate in the nation’s social and economic life. Access is the hallmark of great infrastructure.
Though invisible and taken for granted (at least until they break), infrastructures form the foundation for everyday social and economic life. No individual could start a small business selling products across the country without roads, harbors, or rails. No community that lacks safe drinking water can enable its members to improve their quality of life when their health care costs increase and they are forced to miss work. And with the increasing move of political discussions to online forums, it is becoming increasingly difficult to be an engaged civic participant from the wrong side of the digital divide. To be a full-fledged citizen able to achieve the American Dream requires access to infrastructure.
Yet the history of US infrastructure development shows that broad access for all classes and groups of society was typically achieved through the activities of disenfranchised citizens, not the benevolence of private operators or the foresight of policy makers. Framing their demands in terms of rights and the public good, average Americans pressured corporations through regulatory bodies, broadcast their grievances in the media, organized politically, and even built alternative systems of their own. Infrastructure may be good for democracy, but democracy has usually been necessary to create good infrastructure.
To illustrate these points, we explore three case studies over the past 150 years: railroads, electricity, and the Internet. Each reveals a common pattern of initial deployments of infrastructure favoring the elites followed by citizen activism that demanded fairer treatment for average Americans. Broad access won through democratic struggles, not technological sophistication, made US infrastructure the envy of the world for much of the twentieth century.
If Trump’s infrastructure policies can embrace these lessons, then they can help him deliver on his campaign promises to help average Americans economically left behind. He has yet to offer the specifics of how he intends to stimulate infrastructure development, though his preliminary proposals raise some red flags. He has lauded public-private partnerships (PPPs), which are likely to exacerbate inequality, rather than improve access. Private investors typically target communities that are already well-off and exclude low-income areas. For such a model to be successful, a strong public role must be in place to compel investors to include underserved populations.
Railroads set the stage
As the first big business in the United States, the railroad was also the first industry to be regulated as a public utility. The origins of railroad regulation lay in widespread dissatisfaction with the discriminatory practices of large railroad companies. The vociferous agitation of farmers and small business owners inspired new bodies of law and public policy that created a fairer transportation marketplace.
Pioneered in the late 1820s and developed rapidly in the wake of the Civil War, America’s railroad network came to symbolize for many US citizens both the promise and pitfalls of large-scale infrastructure. Linking the rich hinterlands of the Midwest and South with the industrialized East, interconnected rail lines underpinned the formation of a single national market for US goods. On the passenger side, transcontinental carriers brought settlers westward in droves, creating hundreds of new cities and towns as steel tracks expanded toward the Pacific. Railroad companies, in turn, generated unprecedented fortunes for some investors and employed hundreds of thousands of workers in positions ranging from professional managers to manual laborers laying tracks.
US infrastructure development shows that broad access for all classes and groups of society was typically achieved through the activities of disenfranchised citizens, not the benevolence of private operators or the foresight of policy makers.
With their enormous costs and physical footprints, railroads required prodigious financing and land. From 1850 to 1871, federal authorities granted transcontinental carriers over 130 million acres of public land—an area nearly the size of Texas. Government-backed bonds worth hundreds of millions of dollars provided much-needed start-up capital. In return, politicians promoting railroad interests enjoyed generous campaign donations, railroad stock, and special passes permitting free travel, among other outright bribes. Using other people’s money, railroad speculators swelled America’s rail network from 5,000 miles of track in 1850 to nearly 90,000 miles three decades later.
The often dubious financing of railroads frequently led to mountains of accumulated debt and bankruptcy. In the 1870s alone, almost one-third of all domestic mileage fell into receivership. Pressed to pay off debts and satisfy shareholders, rail companies charged “what the traffic would bear,” using consumer demand and private negotiation to set rates. Large enterprises, such as John D. Rockefeller’s Standard Oil Company, used bulk shipments and financial sophistication to achieve preferential rates far lower than what others paid. In turn, railroads passed these costs onto other classes of consumers, commodities, and localities that lacked the bargaining power to negotiate lower rates: often rural farmers and small business owners.
High rates for small consumers soon drew public outrage. Millions of farmers who settled areas of the Great Plains and American West had no viable alternatives for getting their crops to market, yet ever-increasing transport rates squeezed any potential profit from their farms. As muckraking journalists revealed that large companies received low rates for long-distance shipments of their goods, they pilloried railroads as unwieldy monsters squeezing honest business owners at every turn. Small business owners joined the complaints against discriminatory rate policies, incensed that they were, in effect, subsidizing their more highly capitalized rivals. For these populations, railroad rates were a fundamental determinant of their economic survival.
Frustration with the railroads inspired millions of Americans to band together and push for regulating railroad abuses, with the National Grange—a fraternal organization of farmers—and the Populist Party representing the most organized efforts. Beginning first in Midwestern states such as Illinois, Iowa, Minnesota, and Wisconsin, farmers pushed legislators to introduce regulations that outlawed prevalent forms of rate discrimination and capped rate increases. Recognizing that legislators and courts were poorly suited to wade through the complex accounting and operational details of rail companies, multiple states created new government agencies devoted exclusively to regulating railroads. This state-led system expanded later to the federal level with the Interstate Commerce Act in 1887 (which created the first federal regulatory agency), the Interstate Commerce Commission (ICC), and the Sherman Antitrust Act in 1890, outlawing price fixing schemes used by railroad cartels.
Acting through the ICC, railroad regulators invented whole cloth many of the hallmarks of public utility regulation. In search of “just and reasonable rates,” railroad carriers were forced to submit their rates to public inspection and publication. Any carrier caught shipping goods under secret rates or offering private favors faced heavy penalties. Through public rate cases, the ICC created a new democratic forum to debate the fairness of rates. To aid in their rate-making decisions, the ICC pioneered new forms of data collection and publication, including standardized systems of accounts and routine financial disclosures, that have since become ubiquitous across all industries. Federal antitrust law worked toward different ends, seeking to end private railroad collusion and concentration. Major cases such as the Department of Justice’s action against the proposed merger of the Great Northern and Northern Pacific railroad companies in 1904 and the monopolistic abuses of Standard Oil in 1911 exposed the financial machinations of railroad entrepreneurs.
Though regulation created substantial legal burdens for rail carriers, the end result for passengers and shippers was greater transparency in how railroads operated and increased fairness among different commodities, localities, and users. Perhaps most important, as populist movements challenged the corrupt practices of other infrastructure industries, they could turn usefully to existing railroad precedents to similarly regulate these industries in the public interest. By the mid-twentieth century, a sizable portion of the US economy—banking, electric power, natural gas, rail, telephony, and trucking—was subject to the same price and entry controls pioneered for railroads.
Electricity illuminates opportunities
Electrification offers another compelling case of an infrastructural system that initially benefited the wealthy and spread to broad swaths of the population only after active efforts by citizens to secure fair treatment. Moreover, its history is instructive for seeing the wide array of techniques Americans have used to make infrastructure more democratic. Regulation was one approach, but citizens also invested in municipally owned facilities and in some cases even built their own networks. The slow and uneven spread of electricity clearly reveals the importance of social agitation for increasing access to infrastructure.
Thomas Edison’s pioneering of the incandescent light bulb in 1878 and the opening of the first central station in Manhattan in 1882 marked the onset of electricity as a major industry, and not just an object of curiosity. Millions were immediately captivated, and for good reason. As a source of energy, electricity offered unparalleled flexibility. It could illuminate the night, power urban trolleys, and run factories; it could extend shopping after dark, animate spectacles at fairgrounds, and make possible new forms of entertainment, such as motion pictures.
But these new opportunities were not available to all. Street lighting installations that enhanced neighborhood safety and benefited local retailers were initially concentrated in well-off parts of town. Electrified factories increased production efficiency, which enriched owners without dramatically increasing wages for workers. For homes, the story was little better. As of 1907, a quarter century after Edison opened his first plant, only 8% of US homes were connected to the grid, and virtually every one of those was in a wealthy urban area. Rural residents were almost entirely excluded.
Even when electricity was available, its price revealed comparable problems with the railroads. Homeowners and small businesses paid much higher rates than factories or large commercial establishments—often 10 times or greater—for the same wattage. Part of this resulted from the high capital costs of producing electricity that made supplying small and variable amounts of power more expensive on a per-unit basis than large blocks of continuous power. Yet it was also a product of differential bargaining power and the fact that large enterprises could negotiate more effectively than individual homeowners.
One social response to these inequalities lay in the extension of the public utility model to the electricity sector. Beginning in 1907 as a result of public dissatisfaction with electricity providers, many states formed public utility commissions that offered electrical companies exclusive access to a service area in exchange for accepting limits on the rates they could charge along with requirements to provide fair access to all in the coverage area. For many electrical companies, these rights were well worth the responsibilities. For publics, the utility model provided a promise of access and rates that could be publicly debated. For much of the twentieth century, this approach to electrical provision garnered broad acceptance: for investors, it established stability that justified large investments in the utility sector and healthy returns; for the vast majority of users, it led to cheap and reliable access to electricity. Despite recent complaints about the stultifying effects of regulation on innovation within electric utilities, for much of the twentieth century, the public utility model created a welfare-enhancing compromise with widespread benefits.
Yet it would be a mistake to assume the only form of democratic activity to ensure access to electricity came from government regulation. When private utilities failed to provide acceptable service or extend service to smaller communities, many Americans in those locations banded together to build competing systems. Among the most important of these strategies was the creation of municipal electric works. In the first decades of the twentieth century, these small and locally owned suppliers served communities that were otherwise being ignored by private capital. By 1912, over 1,700 municipal stations were in operation across the nation—about a third of the total number of electrical suppliers. Only by building their own stations could modest-sized communities expect to gain the benefits of electrification.
Municipal stations brought electricity to many small towns, but even into the 1920s, the vast majority of rural locations were entirely unwired. Meanwhile, as many observers at the time recognized, the nation’s farm communities were in trouble. Low prices for crops during the 1920s had led to economic hardship and many rural youth were fleeing to the cities in search of better opportunities. For a nation that had always considered the yeoman independent farmer to be the paragon of civic virtue, this trend was deeply disturbing.
A number of prominent Americans, including Franklin Roosevelt and Gifford Pinchot, argued forcefully that rural electrification offered a potential solution to these problems. Electricity, Pinchot argued in 1925, could bring about “the restoration of country life, and the upbuilding of the small communities and of the family.” They believed electric motors would alleviate much of the drudgery of agriculture and well-lit barns could make tending to animals safer. Moreover, radios could keep rural communities connected to broader events and provide entertainment that would encourage youth to stay local. For advocates such as Pinchot, therefore, electricity was a requirement of modern life, not a luxury.
Both public and private efforts finally began to bridge the gap in the 1930s. The Rural Electrification Administration (REA), launched in 1935, enabled millions of farmers to gather together in small cooperatives to construct transmission wires that connected their homes and farms to generating stations. Only once the rural residents took on the responsibility of building the transmission lines would private companies consent to provide them with power. Similarly, the Tennessee Valley Authority developed large public power installations designed to enhance the quality of life in poor regions of the US South.
Crucially, public utilities did not simply supply power in places that private utilities did not consider worth their time. They also acted as benchmarks and competitors to utility companies—an organizational form of checks and balances. Public power projects often demonstrated that electricity could be generated at lower costs than prevailing rates and empowered utility commissions to demand that private companies match their public competitors.
Electricity has become a taken-for-granted part of modern life. Americans live in homes dotted with outlets and expect coffee shops or airports to have stations to charge laptops and cell phones. Yet it was not always this way. Practically universal access to electricity did not emerge organically from the dictates of a free market; it was the result of an active citizenry demanding a fair shake.
Internet comes of age
Our present-day experience with broadband Internet also exemplifies many of the same tensions central to railroading and electricity. Now 20 years after many Americans got online for the first time, digital divides by race, income, education, geography, and content have stubbornly persisted. As next generation broadband networks replaced older forms of Internet access, familiar concerns over infrastructural availability and equal access have inspired renewed democratic activism.
The Internet began in the late 1960s as a government-sponsored communications network under the watchful eye of the Department of Defense. Conceived at the height of the Cold War, the original vision of the Internet was of a decentralized communication architecture capable of withstanding a nuclear attack. The system’s decentralized nature inspired far-ranging predictions by technologists, such as J. C. R. Licklider and Stewart Brand, of the Internet’s democratic capability to encourage cross-cultural communication and the spread of information, though in reality, the network primarily served research universities and defense contractors. The 1986 transfer of management from military to civilian control did not increase democratization as the National Science Foundation (NSF) limited Internet usage to “non-commercial use in support of research or education.”
By the early 1990s, both legislators and NSF officials began questioning the wisdom of a federal agency funding an increasingly expensive communications network while prohibiting nonacademic vendors and users. These pressures led the NSF to transfer ownership of the Internet to the private sector in 1995, and the agency split up and sold the various components of the Internet to multiple companies. Entirely in private hands, basic Internet access over dial-up exploded in the late 1990s thanks to an already ubiquitous telephone network due to federally mandated universal service policies, new Internet applications, and a plethora of providers that ensured competitive rates. By 1998, 92% of Americans could access seven or more Internet service providers (ISPs). Unlike in railroading or electricity, dial-up Internet availability featured little of the same rural or urban divide in terms of coverage, price, or service options since nearly all homes had a telephone connection that could dial up the Internet.
Despite nearly universal telephony and extensive competition among ISPs, many observers began to note inequality in Internet adoption among different groups of people, a phenomenon referred to as “the digital divide.” In 1998, nearly 60% of US households did not own a personal computer. Three-fourths of households further lacked an Internet subscription. Rather than bridge these inequalities, many policy makers at that time considered the Internet to be more a luxury than a necessity. When asked to comment about the digital divide in 2001, Federal Communications Commission (FCC) Chairman Michael Powell dismissed the idea, claiming that “there’s a Mercedes divide. I’d like to have one. I can’t afford one.”
Despite millions of Americans falling through the net, private-sector investment in the Internet grew enormously during the late 1990s and financial booms in the nearby telecommunications sector led to a massive overbuilding of the Internet’s fiber backbone. After the collapse of the Nasdaq Stock Market in 2000 eliminated many technology companies, large telecommunication carriers and cable television operators stepped in to take over the Internet market. Less entrepreneurial and more conservative than their dot-com rivals, these purveyors of wireline networks offered a new product: always-on, high-speed Internet connectivity capable of delivering new online experiences such as streaming video and real-time voice calling. The substantial infrastructure investment required to deliver these services in a challenging economic time led to mega mergers among broadband providers. Today, Internet access is dominated by a handful of companies (Comcast, Verizon, and AT&T).
This decline in competition among Internet access providers has been linked to higher prices and slow investment and deployment, especially in low-income or low-density areas. Almost 40% of rural areas in the United States still lack access to advanced broadband connections. Broadband adoption continues to be characterized by sharp divides in terms of age, race, income, and education. And while the telephone and electricity saw near universal household adoption by mid-century as a result of concerted government subsidies and citizen activism, broadband adoption in the United States appears to have stalled at 65% to 70% of the total US population.
No longer a luxury, broadband Internet is an essential platform for social and economic opportunity. It has become the preferred means for searching for jobs, conducting a great deal of commerce, submitting homework, researching political issues, and communicating with friends, family, and colleagues. There is no Mercedes gap; there are now fundamental gaps in access to social and economic life for millions of Americans.
As was the case with railroads and electricity, the importance of fair access to Internet services inspired a range of democratic responses to bridge digital divides and hold large data carriers publicly accountable. Like the municipally owned utilities and electricity cooperatives of the past, over 450 cities—especially those located in rural areas or with large lower-income populations—have experimented with operating publicly owned broadband networks. Many of the most successful municipal broadband networks, not surprisingly, are administered by public power authorities. Like the Rural Electrification Administration of the 1930s, consumer advocates have pushed for new federal outlays designed to eliminate the high cost disadvantages associated with rural broadband deployment. Older subsidies intended for rural utilities and telephone carriers have since 2007 been redefined to finance broadband infrastructure.
The emergence of Internet access monopolies has also inspired the rediscovery of the older public utility concept. Growing market concentration has empowered data carriers to extract higher rates from content providers to preferentially access their subscribers, violating what legal scholar Tim Wu has called network neutrality. Many consumer advocacy organizations and content providers have argued that data carriers must treat all Internet traffic equally for reasons of fairness. In 2015, after a decade-long legal battle, the FCC agreed, establishing rules for network neutrality. In justifying the rule making, the FCC acknowledged that broadband Internet was a fundamental, basic infrastructure like telephony or electricity and as such data carriers should acknowledge their public role and responsibilities like utilities of the past.
Despite these promising changes, greater, more equitable Internet access remains uncertain given anticipated structural changes in how Americans get online. Though noted critic and scholar Susan Crawford has called for massive federal investment into a national fiber project akin to the National Highway System, no serious legislative proposals are currently being considered that would dramatically expand federal involvement in broadband infrastructure. Existing federal subsidies for broadband Internet—the E-Rate Program and Universal Service Fund—are generated primarily through fees tied to long-distance phone calls. As landline customers migrate to wireless and Internet protocol-based solutions that lack these universal service fees, already modest federal money is likely to dry up, imperiling access for rural users, among others. Finally, though once considered a complement, wireless data over smartphones has become a substitute to fixed broadband access, especially among low-income users unable to afford both forms of Internet access. Unlike wired service providers, wireless data carriers operate in a lightly regulated environment in which data caps, hidden fees, and paid prioritization are standard operating procedure. As Internet access perhaps migrates away from fixed networks toward wireless carriers, familiar democratic struggles await.
Time to rethink policies
The combined histories of railroading, electricity, and broadband Internet demonstrate that although such infrastructures offer considerable social and economic return on investment, few networks were built with the wider public in mind. Only when citizens pushed for greater accountability and fairer treatment from service providers did infrastructures generate the public benefits we now take for granted. Previous democratic struggles suggest we reframe dominant narratives around US infrastructure and rethink our policy recommendations for addressing our present infrastructural predicaments.
For example, consider President-elect Donald Trump’s proposal to use approximately $136 billion in tax breaks to stimulate a trillion dollars of private infrastructure investment. He intends further for these tax breaks to be revenue neutral, meaning that taxes recouped from contractors and construction workers will ultimately offset their cost. Rather than channel public investment through government agencies, the Trump plan calls instead for a dramatic expansion in public-private partnerships to provide infrastructural services to end-users. Though details are scant, Trump likely intends for developers to build, own, and operate private networks and to further recoup the subsidized costs of construction through tolls or other user fees.
PPPs are a popular approach to policy making today. In many ways, this makes sense. They offer potential cost-savings to government and seek to bring the purported greater efficiency of markets to technological projects. Yet in the case of infrastructure, there is a great risk that too much emphasis is placed on private investment, and too little on the public good. When revenue recuperation is placed at the heart of infrastructure planning, PPPs are likely to replicate the inequalities of early deployments of railroads, electricity, and Internet systems that served the wealthy and ignored the rest of society. In search of revenue, private infrastructure providers tend to overbuild in affluent areas and underserve or altogether ignore poorer, rural locales. It is difficult to imagine how greater private participation will solve the problem of crumbling bridges, roads, and water mains that have never generated sufficient revenue to pay for their adequate upkeep. Smarter public policy would recognize the public benefits of infrastructure and seek to level the playing field for underserved areas through targeted subsidies like those pioneered for rural electrification and broadband Internet, rather than offer blanket tax credits for projects that private investors may fund even in the absence of government incentives.
Privatization itself is certainly not incompatible with publicly accessible infrastructures. Consistent across our three cases, however, is the lesson that democratic access was more often an outcome of organized struggle and protest by citizens than an initial design consideration by providers. Without a strong sense of public good, PPPs are likely to continue this trend. Conceptualized as a timely, cost-efficient way of providing high-quality public services through minimizing public sector financing risks, PPPs are not designed to maximize public accessibility or accountability unless explicitly under contract to do so. Contract terms for pricing, profitability, and service quality, among others, may be proprietary and therefore beyond immediate public inspection. By permitting private-sector entities to assume a greater role in the planning, design, construction, operation, and maintenance of infrastructure, everyday citizens are afforded less input, while state authorities frequently withdraw to an auditing or regulatory role. Policy makers should recognize that there is no one best way to structure PPPs. Instead of proprietary contracts between public authorities and private-sector operators, agreements should be structured to facilitate citizen input, define success in publicly accountable ways beyond cost and schedule, and monitor private providers to ensure they deliver services in an equitable manner.
Making US infrastructure great again is a worthwhile goal; embracing democracy is the way to get there.
Scientific Controversies as Proxy Politics
In science policy circles, it’s a commonplace that scientists need to be better communicators. They need to be able to explain their science to 11-year-olds or policy makers, informed by framing studies, and using techniques from improv theater. Science communication is important for “trust” and “transparency,” and above all “public understanding of science”—meaning public deference to scientific expertise.
In January 2015, the Pew Research Center announced a set of findings comparing the views of “the public” and “scientists”—a random sample of US adults and members of the American Association for the Advancement of Science (AAAS), respectively—on 13 high-profile science controversies. Some of the discrepancies were striking:
88% of scientists said that genetically modified foods are safe to eat, but only 37% of the public agreed.
86% of scientists said that the MMR (measles, mumps, and rubella) vaccine should be required, compared with 68% of the public.
87% of scientists thought that climate change is mostly due to human activity, but only 50% of the public was in agreement.
These gaps between the scientists and the public were seen as a problem, and one that science communication could solve. Stefano Bertuzzi, executive director of the American Society for Cell Biology, called the gaps “scary,” then promoted an initiative that aims to change “the public mindset to accept science in the real world without undue fear or panic.” Alan Leshner, then-CEO of AAAS, called for “respectful bidirectional communication” between scientists and the public—although, even here, the ultimate goal was to increase “acceptance of scientific facts.” Very few commentators questioned the conceptual division of the public and scientists or considered the possibility that high-level percentages might conceal disagreements among different scientific fields.
As a philosopher of science and STS (science and technology studies) researcher, I’ve spent much of the past several years examining public scientific controversies. In my work, I’ve found that simple distinctions between the public and scientists often miss the deeper fault lines that do much more to drive a controversy. Neither group is a uniform, homogeneous mass, and often the most important divisions cut across the public-scientist divide. Similarly, the simple explanation that the public must be ignorant of scientific facts—what STS researchers call the “deficit model”—misses the ways in which members of the public offer deep, substantive criticisms of those “facts.”
Indeed, in many cases, scientific controversies aren’t actually about the science. Instead, science provides an arena in which we attempt to come to terms with much deeper issues—the relationship between capitalism and the environment, the meaning of risk, the role of expertise in a democracy. Science, in other words, serves as a proxy for these political and philosophical debates. But science often makes a very poor proxy. Scientific debates are often restricted to credentialed experts, with the result that nonexperts are ignored. And scientific debates are often construed in very narrow, technical terms that exclude concerns about economics or the cultural significance of the environment. These debates thereby become intractable, as nonscientific concerns struggle for recognition in a narrowly scientific forum.
One can see this drama play out in three high-profile scientific controversies: genetically modified organisms (GMOs), vaccinations, and climate change. In each case, I argue, talking exclusively about the science leads us to ignore—and hence fail to address—the deeper disagreement.
GMOs: Lessons from a co-op
In 2012, shortly after finishing my PhD, I was elected to the board of directors of a local food co-op in northern Indiana. Many members of the co-op held the kind of environmentalist views that you would expect. But, at the same time, we also had many members who were faculty or graduate students in the local university’s biology department. These ecologists and molecular biologists generally shared the views of the nonacademic co-op members. But there was one striking point of divergence: GMOs. Many of the biologists believed that genetic modification was a powerful tool to increase food production while using fewer synthetic chemical inputs. They didn’t think that the co-op needed to go out of its way to promote GMOs, but they did bristle at the idea that the technology was somehow anti-environmentalist. Other members were deeply opposed to GMOs and wanted the co-op to explicitly ban those foods from our shelves.
As I looked into the GMO controversy more carefully, both within my co-op and more broadly, I quickly found that it wasn’t a matter of “progressive” scientists vs. “anti-science” environmentalists. For one thing, often the scientists were themselves environmentalists. In our co-op, they shared many of the views of the other members. They wanted food that was locally grown, using sustainable practices that minimized or avoided the use of chemical pesticides and fertilizers. They generally didn’t like “Big Ag” or industrialized agriculture. At the same time, in the broader controversy, not all scientists were completely uncritical GMO boosters. Some ecologists—whose work emphasizes the complexity of biological systems and the unintended consequences of human actions—are more skeptical of genetic modification.
Because there are scientists on both sides of the GMO controversy—and scattered across the range of positions between “pro” and “con”—it isn’t a matter of undeniable scientific fact vs. ignorance and fear. The standard way to test whether a food or chemical is safe is to feed it to lab rats under highly controlled conditions for 90 days. But lab rats aren’t humans, a controlled laboratory diet doesn’t necessarily correspond to the range of typical human diets, and 90 days may not be long enough to detect the effects of decades of eating genetically modified foods. Consequently, some scientists—people with PhDs in biology or toxicology from highly respected universities—think that the standard methods are too unreliable.
Similarly, when it comes to the benefits of GMOs—in terms of yields, reduced pesticide use, or profits for small farmers—my own research has found that dueling experts cite different kinds of studies. Pro-GMO experts cite surveys of farmers, which describe real-world conditions but often have methodological limitations (especially when the surveys are done in developing countries). Anti-GMO experts cite controlled experiments, which are methodologically rigorous but may not tell us much about what ordinary farmers will experience.
I’ve concluded that it’s deeply counterproductive to think of the GMO controversy in terms of scientists vs. the public or facts vs. emotion. Those two frames focus on who’s involved and how they reason, and make empirical mistakes on both counts. A better framing would focus on what’s at stake. What do people involved in the controversy actually care about? What benefits do they think GMOs will bring, or what harms do they think GMOs will cause? Once we identify these driving disagreements in the controversy, we may be in a better position to design policy compromises that address the concerns of both sides.
For the GMO controversy, I believe that the driving disagreement is over what rural sociologists call “food regimes”: political and economic ways of organizing food production. Today, especially in North America, the dominant food regime treats food as a commodity and food production as a business. Food is produced to be sold into a global market, and, as such, is valued primarily in economic terms—how much do we produce, and how much does it cost to produce it? Organic agriculture might have a place in this system, but as a boutique product, something that farmers can sell at a premium to wealthy customers. GMOs, by contrast, have the potential to increase production while reducing costs: feeding the world while expanding (someone’s) bottom line. As such, GMOs fit easily within the dominant food regime.
In my experience, many proponents of GMOs—from international agribusiness giants to farmers to molecular biologists—simply assume that this market-based system is the only way to produce food. But many critics reject this assumption. They imagine a very different food regime, one in which food is valued primarily in cultural and ecological terms, not economic ones. This perspective is fundamentally opposed to the use of synthetic chemical pesticides, which includes the two major uses of GMOs. In other words, a lot of disagreement about GMOs isn’t about whether they’ll give you cancer. It’s not even really about GMOs. Rather, it’s about deep philosophical disagreements over the way the food system relates to the cultural, economic, and ecological systems that surround it. GMOs act as a proxy—one proxy among many—for this deep philosophical disagreement.
Recognizing that the GMO controversy is about rival food regimes takes us well beyond the science vs. antiscience framing. For one thing, it lets us recognize that developing better ways of testing the safety of these foods won’t address the deeper political, economic, and ecological issues. Broader expertise—especially from social science fields, such as economics, sociology, and anthropology—is needed. Most important, we need to take up, explicitly, the question of what kind of food system, based on what values, we should have. This question cannot be answered by scientific evidence alone, although scientific evidence is, of course, relevant. Answering this question requires political deliberation at many levels of government and civil society.
Vaccines: Varying concepts of risk
In his book on the recent history of the vaccine controversy in the United States, Michigan State University historian Mark Largent describes two different conceptions of risk. On the one hand is risk as understood by experts in fields such as public health, decision theory, and policy. In these fields, risk is the probability or frequency of a hazard across an entire population, given a certain policy: how many people will get measles or suffer a serious side effect from a vaccination, for example. Further, the optimal or rational policy is the one that minimizes the total sum of these hazard-frequencies (perhaps under the constraint of the available budget). For instance, a mandatory vaccination policy that promised to prevent 5,000 measles cases, even while leading to 50 cases of serious side effects, would seem to be well worthwhile.
This conception of risk has important epistemological implications—that is, significance for what kind of knowledge is valuable. First, on this conception of risk, quantitative measures of hazards and their probabilities are essential. Qualitative phenomena that cannot be statistically aggregated across the entire population—such as the trustworthiness of experts—cannot be included in the most rigorous kind of hazard-minimizing calculation. Second, it’s not strictly necessary to understand why and how a certain policy will have its effects. All a policy maker absolutely needs is a reliable prediction of what these effects will be. Since research methods such as large-scale epidemiological studies, randomized controlled trials, and computer simulations are thought to deliver reliable, quantitative predictions, many policy makers and researchers in these fields have come to favor these approaches to research.
This conception of risk also tends to favor an expertise-driven, or technocratic, approach to governance. Once we have reliable predictions of the effects of various policy options, ideal policy making would seem to be simply a matter of choosing the option with the lowest total body count (again, perhaps subject to budgetary and legal constraints). Of course, policy makers are accountable to the public, and the public may not favor the optimal, hazard-minimizing policy. But these are deviations from rationality, and so, the product of emotion and ignorance. Tools from psychology and public relations might then be used to educate the public, that is, make it more compliant or deferential to expert judgment.
Hopefully, the last paragraph gave you pause. The technocratic approach to policy making had its heyday in the 1960s and 1970s; but over the past several decades we have gradually moved to a policy culture that places more emphasis on public engagement and deliberative democracy. We recognize that expert judgment can be fallible, that nonexperts might understand the situation on the ground in ways that are lost in the view from 30,000 feet, and that good policy must take into account factors that can’t be easily quantified. This means that insofar as we have come to recognize limitations to expertise-driven policy making, we also have reason to think that the classical, statistical conception of risk also has its limitations.
Returning to Largent, he contrasts what I’m calling the “statistical” conception of risk with the way vaccine-hesitant parents often think about risk. When parents make a medical decision for their child, their focus is on their child, not an overall social balance of costs and benefits. This approach to making decisions can potentially lead to selfish choices; but as philosopher Maya Goldenberg points out, we typically hold parents—specifically, mothers—responsible for acting in the best interest of their children. In addition, Largent notes that our society has developed a culture of responsible parenting, in which parents are expected to research issues from breast-feeding to educational philosophies to vaccines, then work collaboratively with experts to make the best decision for their children. In this cultural context, it’s not at all surprising that some parents would take steps to educate themselves about the potential vaccine side effects, then feel obligated to make a decision that protects their individual child from those potential side effects.
Parents’ individual conception of risk has its own epistemological implications. When it comes to the decision to vaccinate or not, the question is not how many people will develop measles or side effects, but instead whether their individual child will suffer a side effect or require hospitalization (or worse) if he or she contracts measles. This question requires a good understanding of the causal factors that contribute to vaccine side effects or measles complications. Are some children genetically predisposed to develop autism or a similar condition if their immune systems are overloaded by multiple concurrent vaccines? Do some children have immune systems that are especially vulnerable to a measles infection? Since these effects—if they exist—are rare, addressing them using an epidemiological study or random clinical trial would require a huge sample. A carefully designed case-control study would be much more informative. So it’s not surprising that some groups of vaccine-skeptic parents feel that the large, established body of vaccine research—based on epidemiological studies and clinical trials—doesn’t address their concerns and that parents should play a role in shaping the direction of vaccine research.
Vaccines are a proxy for a much deeper controversy about how we understand risk and expertise. It’s easy to caricature experts as distant and dispassionate, and just as easy to caricature parents as emotional and selfish. Both caricatures are misleading, and not just because they ignore the compassion and dedication of public health experts and the way parents evaluate the reliability of different sources of information, from pediatricians to YouTube. Perhaps more important, the caricatures miss the relationship between experts and parents. Are experts and parents equal partners, or should parents simply defer to the authority of expertise? As with GMOs, this question cannot be answered simply by pointing to the scientific evidence that vaccines are safe and effective.
Climate change: Debating a hockey stick
A controversy about the way scientists estimate historical climate trends—called “paleoclimate” research—can help us understand the way even very technical disputes can serve as proxies for deeper social, political, or economic issues. The example I have in mind is the “hockey stick” controversy concerning paleoclimate estimates produced by climatologist Michael Mann and his collaborators in the late 1990s. These estimates show a dramatic increase in average temperatures in the Northern Hemisphere over the past few decades, relative to the past 1,000 years, and when presented in graph form they resemble a hockey stick for the roughly flat trend and recent rapid increase. In 2003 and 2005, Steven McIntyre and Ross McKitrick published a pair of papers with statistical criticisms of the methods used by Mann and his colleagues to construct the hockey stick graph. Then, in 2007, Eugene Wahl and Caspar Ammann published an important response to McIntyre and McKitrick’s criticisms.
It’s worth taking a moment to understand the backgrounds and areas of expertise of those involved. McIntyre spent his career in the mining industry; he holds a bachelor’s degree in mathematics and a master’s degree in philosophy, politics, and economics, though not a PhD or an academic position. McKitrick is an economist at the University of Guelph in Canada. Today he is involved with the Fraser Institute, a policy think-tank that is generally considered conservative or libertarian, and The Global Warming Policy Foundation, which according to its website “while open-minded on the contested science of global warming, is deeply concerned about the costs and other implications of many of the policies currently being advocated.” Wahl and Ammann are both professional climate scientists. Wahl is a researcher in National Oceanic and Atmospheric Administration’s paleoclimatology program; Ammann is at the National Center for Atmospheric Research, which is funded by the National Science Foundation and administered by a consortium of research universities.
Perhaps because they are not climate scientists, McIntyre and McKitrick’s criticism focuses on the mathematical details of estimating past climate rather than on the physical science used to build climate models. In their response, Wahl and Ammann discuss the need to consider both false positives and false negatives in climate reconstruction and climate science more generally. A false positive is the use of a model—such as a reconstruction of long-term historical temperatures—that is not actually accurate. A false negative, by contrast, occurs when we reject a model that is actually accurate. Wahl and Ammann argue that McIntyre and McKitrick have taken an approach that strenuously avoids false positives, but does not take into account the risk of false negatives. In a 2005 blog post—around the time of the hockey stick controversy—McIntyre more or less acknowledges this point, writing that his “concern is directed towards false positives.” By contrast, in their paper, Wahl and Ammann prefer an approach that balances false positives and false negatives. Consequently, they conclude that the estimates produced by Mann and his colleagues—the estimates used to produce the hockey stick graph—are acceptable.
The philosophy of science concept of “inductive risk” lets us connect the standards of evidence used within science to the downstream social consequences of science. In philosophical jargon, “induction” refers to an inferential move that stretches beyond what we can directly observe: from data to patterns that generalize or explain those data. In the case of the hockey stick, the data are tree ring measurements; the inferential move is to historical climate patterns. Inductive risk refers to the possibility that this kind of inferential move gets things wrong, leading to false positives and false negatives. Philosophers, such as Heather Douglas, argue that the way we balance false positives and false negatives should depend, in part, on what the potential downstream consequences are. If the social consequences of a false positive error are about as bad as the consequences of a false negative error, then it makes sense to balance the two kinds of error within the research process. But if one kind of error is much more serious, then researchers should take steps to reduce the risk of that kind of error, even if that means increasing the risk of committing the other kind of error.
To apply the inductive risk framework to the hockey stick graph, we need to think about the meaning and social consequences of false positive and false negative errors. When it comes to estimating historical climate patterns, a false positive error means that we have accepted a historical climate estimate that is, in fact, quite inaccurate. This kind of error can lead to the conclusion that today we are seeing historically unusual climate change, which, in turn, feeds into the conclusion that we need to adopt climate change mitigation and adaptation policies, such as shifting away from fossil fuels and reducing carbon emissions. But, on the assumption that the paleoclimate estimates are actually inaccurate, these policies are unnecessary. So, all together, the likely social consequences of a false positive error include the economic costs of unnecessary climate policies, both for the economy in general, and for the fossil fuel industry, specifically. Furthermore, some conservatives and libertarians worry that environmental regulations, in general—and climate change mitigation policies such as cap and trade, specifically—are “socialist.” That is, above and beyond the economic impact of cap and trade, these individuals are concerned that environmental regulations are unjust restrictions on economic freedom.
Alternatively, a false negative error means that we have rejected historical climate estimates that are, in fact, quite accurate. This kind of error can lead us to believe that we are not seeing any unusual climate change today, which, in turn, can lead us to take an energy-production-as-usual course. But, if the paleoclimate estimates are actually accurate, staying the course will lead to significant climate change, with a wide variety of effects on coastal cities, small farmers, the environment, and so on. So, all together, the likely social consequences of a false negative error include the humanitarian and environmental costs of not mitigating or adapting to climate change.
These links between false positive and false negative errors, on the one hand, and the downstream social and economic effects of climate policy, on the other, can help us understand the disagreement between mainstream climate scientists and skeptics such as McIntyre and McKitrick. It’s plausible that many mainstream climate scientists think that the humanitarian and environmental costs of unmitigated climate change would be about as bad, or much worse, than the economic impact of policies such as cap and trade. In terms of inductive risk, this would mean that false negatives are about as bad, or much worse, than false positives. This might explain why Wahl and Ammann want to take an approach to estimating past climate that balances the possibility of both kinds of error.
Turning to the other side, there’s good reason to think that McIntyre and McKitrick believe that the consequences of cap and trade and other climate policies would be much worse than the consequences of unmitigated climate change. McIntyre’s career in the mining industry makes it reasonable to expect that he would be sympathetic to the interests of mining and fossil fuels; obviously those industries are likely to be seriously affected by a transition away from fossil fuels. And, as noted previously, McKitrick has connections to a group that describes themselves in terms of concerns about the economic effects of climate policies. In terms of inductive risk and the hockey stick, this means that false positives are much worse than false negatives.
Putting this all together, disagreements over the hockey stick graph can be traced back to disagreements over the relative importance of false positives and false negatives, which, in turn, can be traced back to disagreements over the relative seriousness of the social impact of cap and trade and unmitigated climate change. A technical dispute over how to estimate past climate conditions is a proxy for different value judgments of the consequences of climate change and climate policy.
This conclusion can be generalized beyond our four experts. Climate skepticism is especially high in central Appalachia, Louisiana, Oklahoma, and Wyoming—all areas of the country that are economically dependent on the fossil fuel industry. Quite reasonably, if your individual interests align with the interests of the fossil fuel industry, then a false positive error on climate change poses a direct risk to your economic well-being. That increased concern about false positive errors translates directly into climate skepticism.
It shouldn’t be surprising that people with an interest in fossil fuels might be motivated to be climate skeptics. But my point is that this isn’t acknowledged in the way we talk about climate science. Wahl and Ammann and McIntyre and McKitrick exchange technical criticisms about paleoclimate reconstruction and make points about the relative importance of false negative and false positive errors. These exchanges are unlikely to go anywhere, because the two sets of authors never address the deeper disagreement about the relative threat posed by climate change and climate policy. In other words, the technical debate isn’t just a proxy for a deeper political and economic disagreement; the technical debate myopically prevents us from recognizing, taking on, and trying to reconcile the deeper disagreement.
Making proxies more productive
Proxy debates do not necessarily prevent us from recognizing deeper disagreements. Consider the GMO controversy. The entire system of food production is too complex for us to debate as a whole, especially when we need to make fine-grained policy decisions. While keeping the rival general pictures in mind—the status quo food regime and the sustainability-based alternative—we can focus a policy discussion on a specific issue: How do GMOs fit into the general pictures offered by the two food regimes? Are there uses of GMOs that fit into both pictures? If so, how do we use policy to direct GMO research and development toward those uses? If not, how do we ensure that advocates on both sides have reasonable opportunities to pursue their different systems of food production?
Similarly, we might ask how public health policy and research funding can be used to address the concerns of both medical experts and vaccine-hesitant parents. Or how climate mitigation policy can be linked to economic development policies that will move places such as West Virginia away from economic dependence on fossil fuel extraction.
We need scientific evidence to answer these questions, and debates over the answers will likely still involve disagreements over how to interpret that evidence. But it is more obvious that science, alone, can’t answer these questions. For that reason, debates framed in terms of these kinds of questions are less likely to prevent us from losing track of the deeper disagreement as we debate the technical details.
Of Sun Gods and Solar Energy
Come, O Surya, of thousand rays, the store-house of all energies, the Lord of the world, have mercy on me thy devotee, accept this Arghya, O, Mother of the day.
—Invocation of the Spiritual Sun, The Rigveda
My family’s ancestral home in the village of Jakhan in India’s western state of Rajasthan exemplifies the challenges and opportunities of facilitating energy access in India. Though Rajasthan is perhaps the most densely populated desert on the planet, near Jakhan the population is spread more thinly, and electrification has been slow in coming. The dreams of people such as my grandparents, who wished to see central electricity access arrive at their doorstep, were unfortunately not met in time. My grandfather filed an application to have a grid connection reach his home in the 1970s. The connection came three decades after his passing. Today, over 300 million people still lack access to reliable centralized electricity in this nation of 1.2 billion people.
To help address the plight of those without energy access, decentralized technologies such as solar photovoltaics are being deployed across the country, thanks especially to innovative entrepreneurs, often working in difficult circumstances. Can decentralized energy sources make a difference to India’s people and its future? The question has no simple answer. Since 2007, I have ventured across the nation to try to more fully understand the complexities of solar technology diffusion. India turns out to be an extraordinarily complex solar energy laboratory, a shifting sociopolitical and technological landscape populated by innumerable, distinctive stories of how people are interacting with these innovations. For me, capturing these stories has been nothing short of a personal spiritual awakening. For India, the question is whether they are beginning to add up to a nation genuinely steering the course of development toward a more sustainable path.
Rajasthan: A barefoot revolution
“Aise, jata hai.” “Nahin, yeh dekho.” “Yahan par.” (“It goes like this.” “No, see here.” “Over here.”) Three grannies surrounded me, teeth missing and faces worn, yet wearing their old age with dignity. The sun beat down heavily outside as the warm winds, which locals call the “loo,” blew sand against the homes of the villagers. This parched land, blessed with powerful sunshine, was ready for the monsoons to arrive.
I was sitting indoors, surrounded by old, illiterate women, in the most unlikely of places: an assembly plant of sorts. The women, coming from many different states, produced a cacophony of languages, but after four months together they had learned to share a common language through the words that travelled across the room: “capacitor, transformer, jumper wire.” I, a literate fool, could hardly imagine being capable of knowing these words, let alone assembling the pieces to which they referred.
The subject of multilingual conversation among the grannies huddled around me was whether I was assembling my very first compact fluorescent lamp circuit correctly or not. The circuit would be part of a solar home lighting system, the likes of which the Indian government hopes to distribute to tens of millions of homes in an effort to expand electricity access by 2019.
Where was I? Barefoot College, a nonprofit started in 1972 in a remote corner of Rajasthan. This small, self-sustaining initiative has trained hundreds of illiterate women from across rural India and the world as “barefoot solar engineers.” These women are able to build absolutely everything—including the tools with which they assemble the entire solar home systems.
Indu Devi, age unknown, was busy building a complex circuit for a solar lantern when I first met her. Her hands moved diligently, soldering wires and connecting small circuits to a board. “Where are you from?” I asked. As she began to share her story, I listened in awe. In her native state of Bihar, only 20% of the population has access to reliable electricity. Monthly rations of kerosene distributed to families living below the poverty line sometimes last only five days. The black market price of kerosene to bridge this gap is astronomically high.
Indu Devi has mothered three children and weathered many of India’s harsh rural realities within her lifetime. She aims to go back to her village after the six-month training and help bring light into the lives of the destitute there. Armed with these skills, she wants to set up a rural electronics workshop from which she will fabricate and repair solar systems in her locale.
The deployment of solar technologies in India is not without its challenges. In the village of Dabkan, in the Alwar district of Rajasthan, a community struggled to keep its lights on two years after it received LED-based solar home lighting systems free of charge. Without any replacement parts, supply chains to procure them, or maintenance crews, the community continued to use its systems even as rats chewed through wires, monkeys and peacocks flung solar panels off roofs, and the sticky Thar Desert sand caked itself onto panels when villagers failed to maintain them. Still, lives were transformed: kerosene fuel was saved and the associated costs of having to purchase additional monthly amounts for lighting were avoided; and nighttime productivity of households increased. “There was nothing here 10 years ago except the jungle and we were only connected to the outside world when the road was built,” explained Babu Lal, the only shop owner in the village. It was probably thanks to the road that a two-person team from Grameen Surya Bijlee, an early entrant into the market of off-grid solar technology providers, stumbled across the village with a truck full of supplies that they could not install in another village.
The impact of the availability of lighting was so great that even children’s test scores were improved. “When I first started teaching here five years ago, most of the children couldn’t even write their names properly, and they would fail their tests even with only 50%-60% required for passing,” stated the village school teacher. “It took me one and a half years to just get them to memorize the prayer we do in the morning before starting school.” According to some accounts, the extended hours of study provided by the lighting systems has led to a 70% improvement in retention of knowledge, and, on average, students in Dabkan are studying one to three hours longer than they did before. The introduction of solar energy into an energy-starved community is not a mere convenience but can contribute to improved literacy rates and workforce skills for a new economy in geographies otherwise dominated by agriculture.
Karnataka: Two visions of urban India
Energy poverty is not just a rural problem. Over 65 million people reside in India’s urban slums and many face a daily struggle to get access to commercial energy.
On a cool June day in Karnataka state, I found myself in a slum in Bangalore, the city known as home to India’s high-tech companies. Within the shadow of fancy apartment buildings on an empty plot of land lay a community of 60 families in an informal settlement typical of those referred to as “blue sheet communities.” The blue sheet represents the color of the tarps residents use to cover their informal tenements and shield themselves from the elements. Trailing a young man named Sanjay as we went door to door, I learned about the plight of India’s urban poor, many of whom face the same energy poverty as their rural brethren. Families typically spend approximately $1.20 a week on 1.3 liters of kerosene to meet their lighting needs alone. This represents 10% of an average family’s weekly income.
In India’s solar energy innovation ecosystem, Sunjay is a “pollinator,” an energy entrepreneur from one of Bangalore’s low-income communities who is working for Pollinate Energy, a social enterprise that seeks to provide low-cost solar lighting solutions to slum dwellers throughout India. The model is simple: pollinators are trained in sales and management of solar lanterns and assigned a region to work in by Pollinate. Working under a system of monthly sales targets and corresponding financial incentives, pollinators go out in the evenings (when slum dwellers are at home) selling the devices and handling any maintenance or repairs that need to be made to products already sold. Pollinators may choose to hire a local “worker bee” who is paid a commission to provide leads to the pollinator and facilitate sales of solar lanterns. The approach is helping make lives a little easier for those living under the blue sheets. “The black market price of kerosene is too high,” explains a Neelam, a young girl from the community. “Ever since we’ve purchased these lights, we no longer need to pay high prices or go without light in our home.”
Sixty kilometers southwest of Bangalore in the city of Channapatna, I was offered a different vision of solar technology diffusion for a wealthier urban Karnataka. Twenty-six-year-old Srikant sat in his gleaming shop, its glass-paneled storefront resembling that of a fancy boutique. A web designer by training, Srikant has seen his monthly income rise from the equivalent of roughly $83 to $1,000 a month since he started selling solar products. He is one of Orb Energy’s roughly 170 franchisees who are licensed to sell Orb’s solar hot water heaters, street lights, and grid-connected as well as off-grid solar home lighting systems. “I got into this business for the name, fame, and money,” he says with a grin.
Srikant took a $12,000 loan to set up and stock his shop. To stay afloat, he must make a minimum of $3,300 a month. Entrepreneurs like Srikant leverage the brand of Orb Energy’s products as well as the software and training provided by the company to set up and run their businesses. The parent corporation guides franchisees to meet sales targets and they are rewarded for achieving or exceeding them. According to Orb, within two or three years of working as a franchisee, some of these entrepreneurs go on to start their own businesses. Though not its intention, Orb is essentially unleashing a trained workforce of solar sales agents and technicians into the solar energy ecosystem. These individuals will be critical for helping to ensure that this technology is well managed from factory to rooftops.
Karnataka offers a window into the future of solar technology diffusion in a country under various stages of economic development. New models are evolving to capture different segments of the market: not only urban versus rural but also the poor and the wealthy.
West Bengal: Islands in the solar stream
Kolkata, the capital city of the eastern state of West Bengal, looks like a yellowing old photograph. Yet not everything seems trapped in time. I am here to witness the diffusion of newer technologies. Thanks to progressive state policies, this city is home to many solar energy companies, including Onergy, started in 2009. As I depart Onergy’s office on a cloudy July day, I hear the rumblings of thunder, and soon find myself caught in a deluge, feeling the full force of a monsoon storm. Streets become choked with murky water and my rickshaw puller wades knee-deep past rats swimming for their lives. If the city infrastructure holds up a bit longer, I will soon begin the lengthy journey to the world’s largest mangrove forest, the Sundarbans.
The journey starts from Kolkata’s Howrah station on a local commuter train that takes me to a small town at the end of the line in West Bengal’s 24 South Parganas District. From there, I take a cycle rickshaw to one of Onergy’s regional energy centers (RECs), where I am greeted by Sandeep, an Onergy technician. I do not speak Bengali, so Sandeep explains in broken Hindi that although the electricity grid has reached this town, not everyone is connected, and even those who are on the grid experience planned brownouts for four-to-five hours each day. REC employees thus provide and service the solar technologies for an evolving energy ecology that mixes distributed solar with centralized electricity.
But the REC also distributes products to the Sundarbans, where there is no grid, and for the penultimate leg of my trip there, Sandeep and I board a bus that is bursting with people. For the next two hours it’s standing room only as we pass through a landscape dominated by palm trees, rice paddies, and the occasional water buffalo. The bus dumps us unceremoniously at the last stop in mainland India. After a brief lunch stop of fish curry and rice, we board a large wooden ferry which takes us on a 20-minute ride across the estuary and, finally, into the Sundarbans.
Straddling India and Bangladesh, the Sundarbans provide a critical habitat to endangered tigers and dolphins in addition to their large human population. Extending power infrastructure to a region where people live in pockets strewn over thousands of islands is obviously difficult. Over the past decade, the government has prioritized the distribution of off-grid solar technologies to meet peoples’ needs for lighting and small-scale industrial activity. Responding to government incentives, solar energy companies in the state compete aggressively for market share. This competition makes the Sundarbans a laboratory for studying how people interact with solar technologies and how the technologies fare in this harsh ecosystem.
On the islands, perfectly laid brick roads guide our motorcycle driver through a winding pathway past homes built of everything from concrete and brick to stones and mud. Solar panels dot the thatched roofs of many. My pulse rises with excitement and I start counting them, but I soon realize that they cap nearly every home. I have finally arrived in a place where rooftop solar panels are a common part of the landscape. We make our way to a market area where a solar powered micro-grid was supposed to provide local shops with cooling and lighting. Instead, as the local technician explains, the area’s diesel mafia felt undercut by the technology and forced shop owners to switch back to using diesel. Alas, now this 10 kilowatt (kW) system is used to charge peoples’ cell phones instead of providing power for refrigeration, lighting, and other small-scale commercial activity.
The Sundarbans are a laboratory for studying how people interact with solar technologies and how the technologies fare in this harsh ecosystem.
I begin to realize that micro-grids, heralded as the future of genuine energy access in many parts of the developing world, can come with surprising political and economic consequences. At a village down the road, an entrepreneur, Krishna, has taken on a bank loan to set up a 30 kW solar micro-grid in his village. With no competition, he has essentially become the local utility company. Although this is a welcome way to speed the diffusion of solar energy technologies, entrepreneur-based micro-grid deployment also has the potential to create power monopolies. In a country with caste and religious tensions, such monopolies could be used to create further economic disparities (by charging wildly different rates for the same level of service, for example) in communities that are already too far-flung to police. As I conduct interviews with local customers of Krishna’s micro-grid, I wonder if this is something that philanthropies and development aid agencies are thinking of when they support solar energy diffusion.
The solar entrepreneur is thriving here in the Sundarbans. One afternoon I walk the streets of a small town to interview one of the many shop owners who are assembling and selling solar home lighting components. I interrupt Sidmol, a young man in his early 20s, who is busy assembling a small fan that would be sold as part of his solar home lighting kit. He has been operating his shop for the past two years. “Business is good,” he states. “During the monsoons, I can sell up to 1,200 solar lanterns a month.” He also sells 150 to 200 bigger solar home systems per month. What surprised me the most was that informal sales agents such as Sidmol (who may number in the thousands across the country) often get paid in cash.
This seems strange. After all, the government provides end-user subsidies for these technologies, so why use one’s own cash? But one must have a bank account to access the subsidies, and most people do not have accounts. Banks would have to hand-hold potential buyers of solar products to get them to open accounts—even assuming that bank managers knew that the subsidy existed. Coupled with the amount of paperwork required to facilitate the transaction, it is no surprise that most solar sales for rural Indians happen outside the subsidy regime. Yet with solar systems costing as much as $500, it seems that development practitioners and academics may have underestimated people’s ability to pay for these technologies.
Back in Kolkata, I learn about solar entrepreneurs recalibrating their livelihoods in peri-urban areas such as Hingolganj, where the technological landscape straddles both the off-grid and an advancing central grid. Joy Chakravorty, divisional engineer at the West Bengal Renewable Energy Development Agency (WBREDA), explains the complex regulatory environment. Though the state has a strong base of solar technology manufacturers and leads the nation in the deployment of solar home lighting systems, it leaves small solar entrepreneurs who wish to be a part of the electrification solution in the dark about the future of their livelihoods. One entrepreneur trained by WBREDA in procuring, selling, and maintaining solar home lighting systems, managed to sell 10,000 of them at the remarkably low rate of $125 per system. Yet he saw his future business prospects shrink soon after when the Ministry of Power extended the grid to Hingolganj. Caught off guard by his new competition, the entrepreneur is now taking up the near impossible task of collecting customer fees for the electricity distribution company that runs the grid, while learning to maintain meters. The conflicting policies aimed at addressing the same challenge of energy access risk stranding assets and miss the opportunity to arm a workforce capable of managing a dynamic energy ecosystem that will power the future of a nation.
Bihar: Everyone’s a sales agent
Leaving West Bengal behind, I make my way to Bihar, one of the most impoverished states in the country. Here, the energy poor are taking matters into their own hands to light up their communities. My hotel in the capital city of Patna is near the famous solar bazaar on Exhibition Road. Shop after shop of sales agents hawk their photovoltaic panels and batteries. Posters of Indian cricket star Sachin Tendulkar smiling over a solar home lighting system—no doubt a good cut-and-paste job—adorn some of the shops. They are targeting those living in urban areas as well as passersby from the rural hinterlands who, unlike city dwellers, don’t even have access to the erratic electricity supply from the grid.
As I head toward Vaishali District just outside of Patna, I pass a defunct cooling tower from a local power station—signs of the state’s complicated history with power generation and distribution. Bihar used to be one of the most industrialized states in the country. A history of power politics and underinvestment in power infrastructure has crippled the energy generation and distribution system. No wonder solutions such as solar have taken root here.
Green Light Planet (GLP), a Mumbai-based company, sold 2.5 million solar lanterns in 2014, more solar energy products than any other company in India. Regional Sales Manager Vijay Tiwari accompanies me out toward their rural distribution area and explains their dual business model. GLP sells their Sun King-branded products through partners such as microfinance institutions and nonprofits, but they also have a direct marketing arm, with locally embedded sales agents who sell and service products directly to customers in their communities. In the same manner as Pollinate Energy’s pollinators, GLP’s sales business associates (SBAs) are part-time employees who operate under a system of sales targets and financial incentives to sell vast quantities of solar technologies.
Walking door to door with Rajeev Ranjan Kumar, who has been an SBA for GLP for approximately two years, I learn more about the business of solar in the area. “I have a target of selling 40 solar products a month,” he states. Part of his sales strategy is to go to a local shop owner and leave a solar lantern that the owner can turn on at night. Visitors, drawn to the light in the evening, inquire about the product and get Rajeev’s contact details from the shop owner. Targeting early adopters and community leaders is a great strategy for new innovations in such environments. “One of the first things we did was take a solar lantern to the head of the village,” explains Vijay Tiwari. The village chief, who I met later, explains that he managed to convince approximately 80 other people to purchase lanterns. Nearly everyone I talked to there explained that they managed to convince others to buy lanterns. “Everyone is essentially a sales agent here,” states Tiwari. Now, nearly everyone is saving money by not burning kerosene for lighting, and many families are selling surplus kerosene into the black market to earn extra cash. A local poultry farmer explains how switching out 20 kerosene-burning lamps in his poultry sheds for 20 of GLP’s lanterns has boosted his profit margin.
But this model of selling solar can have its downsides. Dinesh Rai, another SBA who has sold the most monthly products in the region, explains that “this is the business of tying the noose of debt around others.” His frustration stems, in part, from the fact that he is leveraging his social capital to make sales, but allowing people to pay for the products in small monthly installments instead of full upfront payments. The company does not encourage such practices but leaves it up to the SBAs since they take on the financial risk of the products once they purchase them from the parent corporation. Looking through his debt book he laments that he is owed nearly $500 from community members.
Local embedded SBAs have an advantage in making sales. Not only are customers more comfortable purchasing new technologies from a person they know, but they can also report maintenance and servicing needs to someone who will be more responsive than a service rep from a company’s nearby district headquarters. Indeed, maintenance is almost as important for building out the solar innovation ecosystem as sales support. Bloomberg Energy reports that globally, the market for unbranded solar products may be as large as the formal market. If these products are of poor quality or lack after-sales support from parent companies, consumer confidence may suffer, and along with it the market for quality solar products.
Bihar provides other cautionary tales of development in India and the fate of good ideas caught in the crosshairs of politics. On another day, I head to Dharnai, a village two hours south of Patna. I am supposed to be attending the inauguration of a grid-ready 100 kW solar micro-grid. The state’s chief minister, Nitish Kumar, was supposed to come to Dharnai for the inauguration. Under his watch, Greenpeace had allied itself with other organizations to help assist in the chief minister’s vision of developing Bihar and providing universal electricity access using solar energy.
For reasons unknown, the inauguration, I learn, has been pushed back. The change in plans reflected the changing political calculations of the Kumar-led Janata Dal Party (JDP), which feared losing to the central government-led Bharatiya Janata Party (BJP) in the upcoming state elections. The JDP sought to distance itself from Greenpeace, which was labeled “antinational” by the central government for protesting coal and nuclear energy projects. The JDP was also unnerved by protests that emerged overnight, pressing for “real electricity” from the grid and not solar for Dharnai—all a surprise given the amount of stakeholder consultation with locals that went into the design of the solar project.
Though I witnessed a village that was about to become self-sufficient in energy thanks to its 100 kW solar micro-grid and had the capacity to add more power through solar should the villagers need it, the political support for the project evaporated. To further improve his election chances, Nitish Kumar managed to get the central grid once again connected to Dharnai, and he has asked the state utility to give free electricity (paid for by the state) even to customers living above the poverty line. Not only is this approach to electrification economically and politically unsustainable, it is not even new: Dharnai had been down the path of electrification decades before, and through power politics and lack of investment, lost its connection. It seems hard to believe that just two hours south of Dharnai, in the town of present-day Bodh Gaya, the Buddha found enlightenment. Politicians in Bihar need to find a way to harness a bit more of that kind of power.
Governments, entrepreneurs, and gods
After a year of exploring India’s solar energy ecosystem, it seems fitting that my journey ends at Delhi’s international airport in front of a large statue of Lord Surya, the Hindu god of the sun. In its presence, I think back on the many stories I have heard, stories that even today convey a faith in the sun and its power, through solar technologies, to deliver India’s people from darkness. Although the aspirations of these people cannot be met through off-grid solutions alone, in a country with only 240 gigawatts of total power installed currently, the Indian government says it will add 100 gigawatts of solar energy capacity by 2022. But to realize this vision, India must find a way to streamline conflicting policies, clarify others to give better direction to investors and entrepreneurs, and above all, invest in the ecosystem of support structures that can manage and maintain the technologies once they are in use.
My exploration has revealed that firms in the business of deploying off-grid solar technologies in India are finding ways to work in or around a flawed regulatory regime. Most of the firms selling off-grid solar products are doing so in urban and peri-urban areas with grid access. In some ways, then, the market for such technologies may depend on the continued unreliability of the grid. Rural areas face more fundamental challenges that seem inadequately addressed by government policies and development assistance. I’ve learned that getting more locally embedded entrepreneurs into the game of deploying solar micro-grids is an important element of success stories. But many micro-grid companies are reluctant to invest in rural areas without having a clear sense of potentially competing national policies for building out the central electricity grid. To address this uncertainty, some states, such as Rajasthan and Uttar Pradesh, are starting to experiment with policies that clarify how micro-grids may work in tandem with the central grid system.
On financing, if the government continues to provide end-user subsidies for consumers to purchase solar technologies, then it must also accelerate financial inclusion programs that help the rural poor to open bank accounts. But another option may be to provide financing for those businesses that find innovative ways to make access to solar energy easy and reliable without subsidies. Examples include pay-as-you-go solar energy services or the ability to make mobile phone payments for however much local, micro-grid electricity consumers want to consume. Regulations could also encourage crowdfunding to support the solar entrepreneurs who are deploying the best technologies with the best financial models. At a time when incomes are rising and the cost of technology is falling, financial innovation in the deployment of solar technologies remains important because it is still unclear how poor people are making purchasing decisions.
India is angling to be a world leader in solar energy. It has indicated its commitment not only through domestic political targets, but also by introducing and leading the International Solar Alliance, launched at the November 2015 Paris climate conference. But, as the stories I heard make clear, solar technologies are being deployed across India thanks to innovative entrepreneurs who can manage working in difficult and often uncertain regulatory regimes. What these entrepreneurs need from India is not hyped political targets, but policy coherence, quality standards, better training, better access to testing facilities, access to more finance, and better support for incubation or acceleration of their ideas.
Solar energy in India is not a story of a battle between decentralized, renewable energy technologies and centralized grid distribution. Both approaches to providing energy in a nation as diverse and complex as India offer valuable lessons and opportunities. More important is India’s need to get its people access to energy to maximize their ability to thrive in the changing climate of the future. How this energy is delivered will take many forms and, perhaps, require the assistance of many gods.
Kartikeya Singh is an IDRC Fellow at the Center for Global Development and Deputy Director and Fellow of the India States initiative at the Center for Strategic & International Studies. His doctoral research was supported by the Center for International Environment & Resource Policy at the Fletcher School of Law & Diplomacy.
Inside the Energiewende: Policy and Complexity in the German Utility Industry
When the first German law to incentivize renewable energy (RE) came into effect in 1991, even its most ardent supporters could not have imagined that 25 years later RE would provide Germany with 195.9 terawatt hours of power—almost a third of the nation’s gross electricity consumption. Germany’s Energiewende, with its successive and increasingly generous RE legislation, made this unprecedented achievement possible.
The formal goal of the Energiewende (best translated as “energy turnaround”) is to reduce Germany’s greenhouse gas (GHG) emissions by 80% to 95% from 1990 levels by 2050 without relying on nuclear power and while maintaining secure and affordable energy access. This ambitious goal is to be achieved by following two strategic pathways: promoting the deployment of RE so that it provides at least 60% of the nation’s gross final energy consumption by 2050 and increasing energy efficiency to reduce gross final primary energy consumption by half from 2008 levels by 2050. The core energy-system-wide targets are, in turn, divided into quantitative sub-targets for the electricity, industrial heating, and transport sectors.
In 2004, Jürgen Trittin, the German Minister of Environment, declared that support for RE would cost the average German household no more than one scoop of ice cream per month. “The transformation of our energy system is not only feasible, it also pays off,” stated a later Minister of Environment, Norbert Röttgen, in 2012, based on a feasibility study for reducing carbon emissions by up to 95% without relying on nuclear power.
Despite such optimistic statements, Germany’s energy transition is coming at a very high cost to energy consumers and to the German utility industry. Energy systems are complex amalgams of technologies, institutions, markets, regulations, and social arrangements. Nations have little experience intervening in such socio-technical systems to steer them in desired new directions over specified periods. To date, the Energiewende offers strong lessons about the unintended consequences of such interventions, but whether Germany can meet its goals of creating a clean, affordable energy system remains unknown.
Up with renewables
The backbone of the Energiewende is a succession of interrelated laws and regulations aimed at deregulation of energy markets, deployment of REs, support of combined heat and power production for industry, and establishment of a carbon emission trading system. Other policy instruments include measures to increase energy efficiency in buildings; stimulate more intensive deployment of electric vehicles; import RE from European, Middle-Eastern, and North-African countries; and begin to explore and implement visions of a future hydrogen economy. The costs of the Energiewende are primarily being paid directly by energy consumers. This is a significant policy change from previous German energy programs (mostly for the deployment of hydroelectric, nuclear, and fossil-fuel power projects), which were typically financed from general government funds.
The raft of intertwined and interdependent legislation and policies comprising the Energiewende has appropriately been termed an “integrated energy and climate program.” But, as we will see, the consequences of this complexity means that individual policies cannot be understood in isolation and often have consequences that go far beyond those that were intended.
No other instrument from the convoluted Energiewende policy toolbox has contributed more to Germany’s impressive results in ramping up RE production than the successive RE acts, known as the EEGs (Erneuerbare Energien Gesetz), of 2000, 2004, 2009, 2012, and 2014, with the next EEG coming online in January 2017. Each EEG defines the conditions for incentivizing and connecting RE facilities to the grid, as well as the level of feed-in tariff (FIT) for each RE source—wind (on- and offshore); solar (rooftop and large-scale); biomass (liquid, solid, and gas); geothermal; and so on.
The EEG requires grid operators (the electric utilities) to connect, on demand, any RE facility to their grid, and to do so in a way that minimizes the connection cost for the facility owner. RE facility owners then receive from the grid operators generous payments based on the feed-in tariff for each kilowatt-hour of electricity fed into the power grid. The relevant FIT for any given RE site is fixed over 20 years and corresponds to the payment level valid at the moment of the facility’s initial operation. Moreover, because the FITs enacted by each EEG go down over time, the sooner RE owners can bring a facility online, the higher the FIT over the fixed 20-year period. In this way, rapid RE deployment is further incentivized. The EEGs also reduce the risks of RE ownership: even if the grid operator shuts down a renewable facility due to grid instability problems, the FIT has to be paid, as if there were no interruption.
The intensive deployment of RE resulting from incentives created by the EEG has put more power into the electricity market and wholesale prices over the past decade have fallen from about 60-80 euros (€) per megawatt hour (MWh) to €20-30/MWh. Yet household and small industrial consumers experienced the opposite trend because they still had to pay for the rising EEG feed-in tariffs that incentivized and subsidized all the new RE capacity that has continually been coming online. The consumer contribution, a surcharge on top of their regular electricity bills to cover the added costs of RE power generation, has risen with the successive EEGs from about 0.2 cents per kilowatt hour (kWh) in 2000, to 6.88 cents/kWh in 2017. The total electricity-related Energiewende costs for 2016 are estimated at €34.1 billion, of which €22.9 billion (67.1%) represents the EEG costs. For household consumers and small industrial consumers, this means that more than half of their 2016 electricity bills reflect the costs of the Energiewende.
Why have energy consumers had to foot the rising electricity bills even as the market price of electricity was dropping? First, the costs imposed by the Energiewende far outweighed the falling prices on the wholesale markets. Second, to preserve Germany’s economic health, which to a large extent depends on exports of industrial goods, the government shielded energy-intensive manufacturing processes, such as chemical, aluminum, paper, and glass production, from EEG-related charges to keep manufacturing companies from migrating to countries with cheaper energy, or simply to protect them from economic failure due to the high price of electricity. As a result, about 40% of the nation’s electricity is used by industries that are largely protected from contributing to the Energiewende costs—expenses that therefore must be borne by other energy users.
Down with nukes
If the EEGs have introduced significant price distortions onto the German energy scene, a second major policy change—the phasing out of nuclear power—makes the role of REs even more complex. After passing into law the first regulations for promoting RE and combined industrial heat and power, former German Chancellor Gerhard Schröder’s first administration signed in June 2000 a nuclear phase-out agreement with the German utility industry. The political motivation for the phase out was not climate change, but the antinuclear position of the Green party, which at the time was part of Schröder’s ruling coalition. Thus, the phase out was accompanied by policies that protected the use of cheap domestic lignite and subsidized domestic hard coal—the most carbon-intensive fossil fuels—in order to protect jobs, reduce energy imports, and help preserve energy security as Germany moved away from nukes.
This political and policy calculus soon evolved as climate change became an increasingly important policy priority. Current German Chancellor Angela Merkel’s first administration decided in 2007 to merge Germany’s energy and climate policies in an integrated action plan meant to reduce GHG emissions by 36.6% from 1990 levels by 2020. Three years later, Chancellor Merkel’s second government set the current decarbonization goals of at least 80% emissions reductions by 2050 and presented the first integrated road map to carbon neutrality. To achieve this ambitious target, the road map included a postponement of Schröder’s nuclear phase out by extending the life span for the existing German nuclear facilities by up to 14 years. The rationale behind this change in the policy was that nuclear technologies are nearly carbon-free, have a high energy intensity, cover about 60% of Germany’s base-load power, and can not only help meet higher decarbonization rates, but also make up for the lack of affordable electricity storage facilities needed to make up for intermittent power generation from renewable sources.
Only six months later, after the March 11, 2011, nuclear accident in Fukushima, Japan, and in the wake of fast-spreading antinuclear protests, Chancellor Merkel changed Germany’s policy course again. Driven this time by the fear of losing her political legitimacy, she decided to decommission all German nuclear power plants by 2022, without renouncing Germany’s ambitious 2050 GHG reduction targets.
Intermittent sun and wind
With nuclear power no longer a part of Germany’s energy future, the country’s aggressive decarbonization goals now had to be achieved through even more rapid deployment of REs, and that is the course the nation has been pursuing. But the rising share of intermittent RE sources—solar and wind—creates several technical, economic, and ecological problems.
Most important, as intermittent RE sources increasingly come onto the grid, the ratio of electricity generated to installed capacity goes down. For example, fossil and nuclear plants are able to reach about 8,000 “full load hours” per year (the amount of electricity actually generated in a year, divided by the installed capacity). The average full load hours in Germany for onshore wind is about 2,000 hours, and for solar it is about 800 hours. So the more that electricity is generated by intermittent sources, the more the full load hours decline.
In 2015, the installed RE capacity was slightly higher than the conventional capacity (97.4 gigawatts [GW] compared with 96.7 GW). The current conventional power plant pool is already sufficient to cover the entire energy demand without relying at all on RE. However, given the priority of RE feed-in, and a “power back-up” ordinance that prevents conventional power plant owners from phasing out uneconomic sites if they are necessary for grid stability, utilities are forced to run their power plants inefficiently and to generate significantly less electricity than they technically could. Despite these imposed operational inefficiencies, conventional plants still generate more than twice as much power as RE facilities can produce with nearly the same installed capacity.
One way to think about this problem is that for every megawatt (MW) of conventional base-load capacity generated by fossil or nuclear fuel, you’d need 10 MW in solar power or 4 MW in wind. Yet this RE capacity would ensure only that one could generate the same amount of power as conventional sources over one year and not that one could supply the power when demand is high. For example, on a sunny and windy holiday, when demand is low, the generated power would exceed by far the demand, but on cold, windless nights, when demand is high, it would be rather impossible to meet demand.
The more intermittent power is fed into the grid, the more difficult it becomes to ensure a reliable and stable grid operation, especially because there is no affordable technology for storing electricity at a large scale. Wind and solar intermittencies are currently leveled by conventional power plants, most of which are coal-burning. The alternative is pumped water storage—reservoirs that can provide hydroelectric power on demand—which is very expensive (yet cheaper than other storage technologies), with an estimated cost of 7.7 cents/kWh. Approximately 9,000 pumped-storage facilities would be needed to level the discontinuities generated by wind and solar energy in 2015. Currently there are 36.
Another consequence related to the intensive deployment of RE and the lack of appropriate storage facilities is that electricity prices have become negative in periods of low demand and high RE feed-in—that is, companies ended up having to pay users to consume electricity. The reason is that gas power is too expensive and coal power is not flexible enough to compensate intermittencies at the hourly-scale pace in which they appear. It typically takes about eight hours to run a coal power plant completely down and another eight hours to bring it up to capacity generation again. Yet coal power is still too important for the stability of the grid to be phased out, so these plants continue operation during the relatively short RE peaks where prices actually go negative on the wholesale power exchange.
Gaming the system
Intermittency is not the only difficulty created by the Energiewende. A significant if less publically known set of problems is related to the ability of actors in the energy system—especially large ones—to take advantage of loopholes and improperly specified rules, even if they know that such “gray” areas will be eliminated by policy makers as soon as they become aware of them. For example, one way that the EEGs generate revenue to support the costs of the Energiewende is through the surcharge on electricity consumption for all end uses (apart from exempted industries). But to further incentivize energy traders to increase the share of RE in their portfolio, EEG2009 allows traders with at least 50% RE power in their portfolio to deliver 100% of their electricity without the EEG surcharge. Traders dutifully designed portfolios with exactly 50% RE and 50% conventional power, reduced their electricity prices slightly, and kept the difference, thus enriching themselves while returning only minimal savings to their customers.
The RE acts also exempted companies that produced their own power from paying EEG surcharges. The resulting loophole allowed companies to lease a power plant (usually one that burned fossil fuel), produce their own electricity, and share the savings in EEG costs with the power plant’s owner.
Yet another example of the perverse incentives of the Energiewende is the booming business in small lignite boilers. To avoid disproportionate bureaucratic burdens for relatively small heat-generating facilities, boilers with a thermal capacity under 20 MW are not subjected to the emissions trading law, so operators of such boilers do not have to purchase allowances for their carbon emissions. This rule led to a flourishing business in 19.9 MW lignite boilers because lignite is the cheapest fuel—even though it is also the one with the highest carbon content.
Such unintended consequences should not be surprising given the daunting complexities of the Energiewende and related efforts to steer the German energy system toward a clean energy future. Since the 1990s, such efforts include the ratification of the Kyoto protocol, the implementation of the European Emissions Trading System, the liberalization and deregulation of electricity markets, the adoption of successive support schemes for RE deployment, and the creation of complex mechanisms for promoting energy efficiency and enforcing clean air regulations—all superimposed on the major geopolitical changes of German reunification in 1990 and the founding of the European Union in 1992. While trying to remain up-to-date with the steadily changing and increasingly complex regulatory framework, diverse actors in the energy arena have faced soaring energy costs, an increasing dependence on intermittent power sources, severe energy transmission and storage problems, forced electricity exports, negative electricity prices, and loopholes that motivate actors to take legal free rides on the backs of less favored, or less creative, players in the energy system.
Minimizing utilities
Inside the Energiewende there was no economic branch harder hit by these successive waves of induced complexity and change than the utility sector. Deregulation of the electricity market in the late 1990s triggered a strong consolidation wave; mergers among the nine largest German regional utilities led to the four big energy corporations that dominate Germany’s utility sector today. This consolidation phase was followed by a period of diversification and international expansion triggered by the EEGs and other Energiewende laws. National utilities became global energy companies almost overnight, investing in new facilities and companies in Germany and other countries and generally changing their focus from domestic to international markets.
At first, utilities ignored government efforts to encourage RE deployment; later, they began to lobby against them, as they realized that managing the problem of intermittency would be both technically difficult and expensive, and that hard assets such as coal and nuclear plants were being rendered worthless. Yet, utilities soon came to recognize that the EEGs offered a comfortable pathway to making profits without taking entrepreneurial risks. By 2008, the major utilities began massively investing in RE and by 2014 they began to split their companies into “bad” traditional fossil and nuclear energy businesses that could not make a profit, and “good” entities that invested in REs.
The Energiewende’s focus on RE feed-in forced utilities to run their power plants inefficiently and to generate significantly less electricity than they technically could. Meanwhile, the nondiscriminatory grid access rules created by the EEGs subjected utilities to increased competition and significant loss of market share as new players were enticed into the Energiewende arena and small, flexible entrepreneurs developed new business ideas that exploited market niches in the decentralized power generation realm. Electricity prices for industrial consumers and households significantly dropped in early deregulation stages, reaching their lowest level in 2000, and rising again under the generous schemes for the deployment of RE that became effective between 2000 and 2014.
Despite all efforts by the big utilities to improve their position in the market, the spread between revenues and earnings steadily increased and the sector shed nearly a quarter of its employees between 1998 and 2013. Shares of RWE, Germany’s largest utility in 2000, rose rapidly through 2007 and have since lost about 90% of their value; Eon, currently Europe’s largest utility, lost about 80% of its share value in the same interval.
Given the increased dependence on intermittent wind and solar energy, regional utility grids became increasingly difficult to operate. The grid business is strongly regulated, allowing only small predetermined margins, so the utilities lost their interest in operating transmission grids and sold significant shares of this business to compensate for losses triggered by the Energiewende. The tremendous decommissioning costs for nuclear power plants, coupled with the unsolved problem of nuclear waste disposal, added still more to the costs that the utilities had to bear and this once powerful sector was pushed to the brink of dissolution. In their desperate effort to survive, the big utilities defined new ways of working, organized and reorganized their activities, sold assets, changed the core of their business, and, finally, switched their focus to “intelligent” technologies, demand-side management, and energy services, but such efforts have done little to stabilize their long-term prospects. Today, the German utilities, especially those such as Eon and RWE that still operate major fossil and nuclear plants, lack the financial means to develop new business models, adjust to the continually changing policy frame, satisfy their stockholders, and actively shape the Energiewende. Indeed, on April 25, 2015, some 15,000 utility employees working in lignite extraction, fuel manufacturing, and coal power plant operation demonstrated in front of Chancellor Merkel’s office to get attention for their plight. But unless wholesale energy prices rise significantly, and soon, the future solvency of these major companies remains in doubt.
Is the Energiewende on track?
On the face of it, what amounts to an unintended sacrifice of the utility industry might seem like the necessary price to pay for creating a new clean energy system. Indeed, on May 15, 2016, Germany met almost its entire electricity demand with RE. These impressive results in the renewable electricity realm have attracted international attention and recognition. Numerous individuals and organizations, including Al Gore, Paul Krugman, and Greenpeace, share the optimistic view that Germany is now demonstrating that a totally decarbonized economy is both technically feasible and affordable.
But it is by no means clear that the addition of huge new RE capacity to the German electricity grid is translating into the desired outcome of reduced carbon emissions. As I have shown, the situation in the power sector is extraordinarily complex and the addition of RE capacity does not in any straightforward way displace fossil-based electricity; indeed, in some cases it has led to the increased use of cheap fossil fuels. Moreover, emissions are not determined by the power sector alone; RE deployment lags behind targeted deployment levels in the two other major energy sectors, transport and heat, making it difficult to meet the targeted RE share of the gross final energy consumption without adding yet another layer of regulation.
It seems that emissions reductions have for the most part been driven by entirely different forces than the Energiewende so far.
Current trends show a much slower reduction in carbon emissions than is needed to even come close to meeting the minimum target of 80% reduction by 2050. More perplexingly, the contribution of the power sector itself to reductions so far is quite minimal. Indeed, it seems that emissions reductions have for the most part been driven by entirely different forces than the Energiewende so far. Germany’s GHG emissions have decreased by 27% since 1990, yet more than the half of this decline was achieved before the European Union ratified the Kyoto Protocol, before the first regulations to mitigate climate change became effective, and before the sophisticated European cap-and-trade system was established. These pre-Kyoto achievements were primarily related to the deliberate selection of 1990 as the reference for measuring emission reductions, since it marked the beginning of eastern Germany’s economic breakdown and consequent reduction in energy use in the wake of reunification. Early voluntary commitments to climate mitigation by several industrial branches also contributed to the pre-Kyoto carbon reductions, but these were based mostly on substitution of natural gas for coal and oil. The global economic recession that started in 2008 also contributed to lower energy use and thus reduced emissions.
The post-Kyoto measures have led to relatively little mitigation in the intervening years. In fact, between 2009 and 2014, as 44,425 MW of RE capacity was added to the German power system, emissions increased. This occurred, in part, because zero-carbon nuclear facilities had to be replaced with carbon-intensive coal and gas plants. At the same time, all of the new RE capacity helped to drive down wholesale electricity prices. The European Emissions Trading System, which was supposed to be a market tool for reducing GHG emissions, proved instead to be a playing field for speculators hoping to profit from boom-and-bust cycles. And bust has been much more the norm as the emission trading rules and the rapid deployment of RE led to reduced production of fossil energy and a consequent glut of carbon allowances, whose value declined from above €20/ton of carbon dioxide emitted in 2008 to less than €3/ton in 2013 to just above €4/ton at the end of 2016. These very low allowance prices sent the wrong signals to the market and ended up making lignite and hard coal economically attractive, thus further contributing to the absolute increase of carbon emissions.
To date, then, the Energiewende’s record is mixed, but very troubling. On the plus side is continued public support and a very impressive ramping up of RE capacity. But on the deficit side of the ledger are exploding energy costs, failed policy tools such as the German and European Union trading schemes, and hard-hit institutional actors—above all the major utilities, which increasingly look as though they have been consciously sacrificed to help Germany to meet its ambitious GHG emission targets. But these targets are not being met.
The major challenge for Energiewende-like programs is to integrate intermittent sources of power into existing energy systems. But despite all efforts to convert excess electrical power to hydrogen, methane, heat, or other storable commodities, and despite all progress made in battery research, storing the electricity necessary to solve Germany’s intermittency problem remains technologically, economically, and politically out of reach.
An optimist might declare that the very fact that Germany’s electricity grid has not collapsed must mean that the intermittency problem is well on the way to being solved. In reality, collapse has been averted only through two mechanisms that run directly counter to the goals of the Energiewende. First, the intermittency balancing problems on cloudy and windless days could be managed only because utilities backed up intermittencies by running fossil power plants—and running them in ways that were uneconomic and especially bad for the environment. Second, Germany’s electricity generation on windy and sunny days exceeded, often by far, the grid’s balancing abilities, forcing the power surplus into adjacent grids, and obliging other countries to compensate for German intermittencies, which can lead to disturbances and additional costs in the other grids. Thus, these solutions are neither economically sustainable nor carbon-free. In the absence of nuclear power, Germany’s transition to a low-carbon energy system depends on its ability to store enough cleanly—and affordably—generated electricity to compensate for the intermittencies created by the massive introduction of REs. Until this problem is solved, the Energiewende will remain, above all, a testimony to the unintended consequences that result from well-meaning intervention by Dichter und Denker—poets and thinkers—into complex social and technological systems.
Philosopher’s Corner: The End of Puzzle Solving
Back in the mid-1990s, social commentary on science was dominated by the “science wars”—crossfire between one or another humanist scholar and the science establishment. The conversation was often shrill. Observers such as French sociologist Bruno Latour delighted in highlighting the ways in which values were embedded within scientific work. In furious counterattack, scientific realists such as Norman Levitt and, most notoriously, Alan Sokal dismissed such postmodernists as rejecting scientific objectivity, the scientific method, or any standards whatsoever. Over time the controversy faded, perhaps as much from exhaustion as from anything else. Now, some 20 years later, the needle seems to have settled somewhere in the middle: scientific findings are often robust, but they live within a larger social ecosystem, and scientific results are rarely the last word in policy disputes.
This position, however, implies that in important respects the postmodernists have won. From the point of view of the scientific realists the contagion has spread: the autonomy of science has been chipped away, and its status as a uniquely objective view on the world is widely questioned. The politicizing of science, once a distant threat, is today a commonplace. The academy has tried to put a good spin on it, calling it “interdisciplinarity” or “open science,” as social scientists, humanists, and citizens have been brought into the process. And greater societal responsiveness and accountability is a good thing. But this has also raised questions concerning competency of judgment. Walls may be falling, but norms are also breaking down. This is the case not only with science: for more than a year now Donald Trump has had the commentariat atwitter. Trump may have increased democratic participation, but also the rise of post-factual politics. Pundits keep waiting for the political order to reestablish itself, but there’s also a growing suspicion that the categories that once ordered our personal and public lives have lost their grip—a suspicion that Trump’s surprise victory has only accelerated.
Science as it has been practiced now finds itself maladapted to a changing social landscape.
This leaves younger scientists—and those who train them—inhabiting a changed landscape. Scientists not only need to defend their work on more-than-scientific grounds, for example, by satisfying the broader impacts criterion for National Science Foundation (NSF) proposals. They are also living through the breakdown of what Thomas Kuhn called “normal science.” Kuhn argued that scientists spend the vast majority of their time engaged in “puzzle solving,” working on specific problems within well-established and secure frameworks. But whereas Kuhn recognized the possibility of the occasional revolution in science—think of the shift from Ptolemy to Copernicus, or from Newton to Einstein—such revolutions were at least initially intra-scientific affairs. In contrast, the disruption today is between science and the other mega-categories of life.
The growth of an accountability culture and the renegotiation of the social contract of science isn’t a revolution in science. Rather, it’s a redefinition of the basic conceptual space of intellectual life. Kuhn imagined the eventual reestablishment of order with the creation of a new scientific paradigm. Today, however, it’s unclear whether we will ever again have generally accepted social norms for truth, in either politics or science.
Now, as Latour himself pointed out, the traditional view of science—what the philosopher Jürgen Habermas called the separation of the public spheres—was always something of a myth. The contract between science and society as outlined by Vannevar Bush, the architect of US science policy after World War II, did an admirable job of simultaneously asserting the relevance and neutrality of science. But this framing was always unstable. There was too much at stake. As we’ve discovered with climate science, the more striking the results, the more portentous the implications, the more inevitable the push back from one or another element of society. Ambiguities arise in the interpretation of complex phenomena that are a poor fit for a binary political culture. The current situation of science in culture can even be seen as the ironic result of its success—that it was inevitable that anything this powerful would become enmeshed in ethical, political, economic, and religious debates.
Science as it has been practiced now finds itself maladapted to a changing social landscape. It is being asked not only to demonstrate its economic and policy relevance, but also to be more attentive to a wide range of ethical and cultural effects. Criticisms come from unaccustomed corners. NSF’s broader impacts criterion—and similar requirements across the landscape of science—summarizes the new status quo: whether through talk radio or WebMD, science is now grist for everyone’s mill. Scientists may pine for the old days, but they are left with trying to adjust to changed cultural circumstances.
This change suggests the need for a new skill: the ability to spot how scientific work can morph into ethical, economic, or cultural questions at the drop of a hat. Across the next few installments of Issues in Science and Technology this column will try to map this new landscape. The authors, one or another type of philosopher, will trace out the paths whereby science leaves off and other concerns emerge—in the gender wars and genetic conservation, CRISPR and the security state, a political party for science and the nature of impact. What all of these essays will hold in common is the exploration of the redefined public space occupied by science, which functions as a real-world political and philosophical experiment.
Yes, philosophical. Of course, philosophers have a reputation for irrelevance. We’ve come by this status honestly: academic philosophers—and today there is hardly any other kind—are mainly known for their exercises in navel-gazing. The oldest story of philosophy involves Thales, by tradition the first philosopher in Western culture, and his confrontation with a milkmaid who laughed when Thales fell into a ditch while gazing at the stars. Thales, however, also made a fortune when he cornered the olive market. And this highlights the second goal of these essays: to see if philosophy has anything useful to add to debates about the role of science in policy making, and to culture more generally. For if the social space of science is changing today, the same is true for philosophy.
Robert Frodeman is professor of philosophy and religion at the University of North Texas.
Forum – Winter 2017
Needed: better labor market data
In “Better Jobs Information Benefits Everyone” (Issues, Fall 2016), Andrew Reamer ably describes recent progress in building longitudinal market data systems. But as he notes, there is still work to be done to create a nationwide, not simply a state-based, system. Some states are still in the early stages of connecting data on college programs with wage records, and most states have not yet begun to tap into this data to improve the college-to career transition.
In addition, most of these systems have a major deficiency: they lack data on the types of jobs that people hold. As a result, educators, employers, and policy makers have a tough time trying to pinpoint where individual postsecondary programs need to be expanded or reduced in line with employer demand. Without this information, it is also nearly impossible to trace the career trajectories that graduates take as they move from job to job. The solution is well-known: the federal government and states could simply add occupational identifiers and other detailed information to Unemployment Insurance wage data collected from employers.
Reamer recognizes that an information capability that connects individual postsecondary programs and careers has become essential for understanding middle-skill job opportunities. With middle-skill jobs, as with bachelor’s degree-level jobs, what you earn is closely related to what you study. These jobs tend to be closely connected to local labor markets and characterized by demand not only for traditional degrees, but also for a range of certificates, certifications, and licenses. What is sorely needed is a major effort to map such jobs—including all the programs, pathways, and credentials that lead to good jobs that pay without a bachelor’s degree.
Few people will disagree when Reamer says, “Remarkable opportunities are available to enhance the workings of US labor markets through modest investments to improve workforce data resources.” As he suggests, building out the national information infrastructure is a high-leverage opportunity with relatively low costs. If policy makers want to get serious about the future of the middle class, then mapping the connections between education and economic opportunity will naturally be Job No. 1.
Anthony P. Carnevale
Research Professor and Director
McCourt School of Public Policy
Georgetown University Center on Education and the Workforce
Andrew Reamer rightly calls for improving the collection and use of data for advancing decisions about human capital. He methodically and thoroughly recounts the various sources of workforce information that, as he points out, are numerous, often scattered, and sometimes redundant.
Although Reamer briefly mentions various stakeholders who would benefit from improving the connectedness and usability of this information, these issues should matter to everyone. What are people supposed to do after a mass layoff when they believe that they do not have the skills required for the jobs remaining in their hometown? How can employers more efficiently find the workers they need to grow their businesses? How can policy makers know whether student financial aid investments are helping to move students into successful careers?
Among Reamer’s list of recommendations for federal and state data improvements, he calls for adding occupation information to state Unemployment Insurance wage records, along with incorporating shorter-term nondegree credentials along with traditional degrees into statewide longitudinal data systems that can show how people go through all of the stages of education and training, and into the workforce.
When matched with data on education and training, occupation information on wage records would help us to see whether people are finding jobs in their fields of study and indicate the success of workforce training programs. Moreover, requiring the addition of occupation information on wage records would reveal what is happening on a far greater scale than methods that currently rely on surveys, as Unemployment Insurance wage records cover about 80% of the civilian workforce. Although industry codes are currently required on wage records, this information is insufficient. Industry codes cannot indicate, for example, whether people who received training in data processing and now work in the retail industry are supporting the computer systems that serve their employers, or instead are working as sales clerks at company stores.
Fully supporting statewide longitudinal data systems that securely match this information would empower students and workers to see how much they might be able to earn given their occupational goals. Moreover, if ongoing efforts to catalogue skills across occupations are successful, we would be able to delineate which skills are most valuable across occupations, even as the labor market changes more frequently. Educators could make their coursework more market-relevant. Employers would have a better sense of the skills of the available workforce, and thus could make more informed decisions about where they might want to set up or expand shop.
With all of this great potential, the changes Reamer calls for would be well worth it. Although it will require more investment upfront to modernize federal and state data systems, all education and workforce stakeholders would ultimately benefit by having powerful information to make better decisions about investments of time and money.
Christina Peña
Policy Analyst
Workforce Data Quality Campaign (a project of the National Skills Coalition)
Washington, DC
What are middle skills?
In “The Importance of Middle-Skill Jobs” (Issues, Fall 2016), my colleague Alicia Sasser Modestino provides a good review of labor market trends. Her focus on middle-skill jobs is especially important given persistent and widespread concerns regarding prospects for the middle class in the United States. A number of points are worth considering further.
The concepts of middle-skill jobs and middle-class jobs have no official or standard definitions and the ways the two concepts are used often refer to somewhat different groups of jobs. Also, the education levels of the workers are often used to define the skill levels of the jobs they hold, but it would be better to define the skill requirements of job tasks independently of worker credentials. Although it is likely that most middle-skill workers are matched to middle-skill jobs, and vice-versa, defining job requirements based on worker characteristics makes it more difficult to investigate whether there is any mismatch between workers and jobs.
Most definitions of middle-skill jobs include those discussed in the article, such as skilled trades, higher-level clerical and administrative support occupations, technical jobs, some sales jobs (e.g., insurance agent, wholesale sales representative), and a diverse group of associate professional and similar jobs, such as teacher, social worker, nurse, paralegal, police detective, and air traffic controller, among many others. Although most of these jobs are likely to support a middle-class lifestyle and personal identity, the degree to which this is the case will depend on whether one’s definition of middle class emphasizes earnings, job education requirements, or other job characteristics, such as freedom from close supervision, as well as the type of household to which an individual belongs (e.g., single individual, two-earner couple, single parent). Likewise, there are jobs that are generally considered less-skilled whose pay may be within the range considered middle class, such as long-haul truck driver. Such jobs were even more common prior to the decline of manufacturing production jobs and unionization rates that began in the late 1970s, a fact that attracted renewed attention recently in political discussions. All of which is to say that there are strong relationships between workers’ education and training, job skill requirements, job rewards (both material and nonmaterial), and social class, but that these concepts are not identical and their relationships are not one-to-one.
The author makes a significant point regarding the future of middle-skill jobs, most of which are presumably middle class. A large literature in labor economics argues that computer technology and automation are eliminating such jobs, driving inequality growth. However, the article indicates that the share of all jobs that are middle-skill has not changed recently, although a greater share of such jobs may require some college. These trends are important to monitor.
It is also important to understand that occupational change in the United States and other advanced economies has been more gradual than often recognized and has not accelerated appreciably in recent years, despite widespread belief that the diffusion of information technology is radically altering the nature of work. Moreover, official projections suggest continued gradual change in the occupational structure in the next 10 years. In addition, retirements and ordinary turnover will create vacancies for new job seekers even within occupations that will decline as a proportion of workforce. The US Bureau of Labor Statistics projects that between 2014 and 2024 there will be fewer than 10 million net new jobs created, but more than 35 million openings because of such replacement needs.
Finally, research shows there is a persistent tendency among observers to confuse cyclical weaknesses in overall demand with structural changes in the labor market. Concerns regarding technological unemployment spiked during the Great Depression and post-war recessions, but dissipated after economic growth rebounded and unemployment fell to normal levels. The extent of technological unemployment tends to be overestimated while the role of aggregate demand insufficiency is underestimated. The United States and other countries do not need to look to the future for a possible jobs crisis; they have experienced a jobs crisis since the beginning of the financial crisis in 2008. Raising education levels among young cohorts is necessary to keep up with technological change that is steadily but gradually altering the structure of employment. However, more effective macroeconomic policies can have a quicker and broader impact on the job prospects of middle- and less-skilled workers, as the strong growth of the late 1990s demonstrated.
Michael J. Handel
Department of Sociology and Anthropology
Northeastern University
New toxic chemical regulations
Two informative articles in the Fall 2016 Issues—“Not ‘Til the Fat Lady Sings: TSCA’s Next Act,” by David Goldston, and “A Second Act for Chemicals Regulation,” by Keith B. Belton and James W. Conrad Jr.—are minimally to moderately encouraging about the human health ramifications of the recent overhaul of the Toxic Substances Control Act (TSCA). However, the argument in both reviews would be strengthened, as would the amended TSCA, by putting public health concepts at the forefront.
The original TSCA was a mixture of two types of preventive approaches. Primary prevention, which results in the chemical never being produced, occurred through the law’s requirement of pre-manufacturing approval, based primarily on reviews of the chemical structure by experts at the US Environmental Protection Agency (EPA) who were knowledgeable about basic toxicological science. The EPA could ask for toxicological or other data if there were concerns of potential mutagenicity or other adverse consequences. Common to all primary health prevention modalities, we cannot directly measure the effectiveness of this approach as we do not know how many chemicals would have produced adverse health effects had industry not weeded them out by routinely using existing tests for such endpoints as reproductive and developmental toxicity. Note that there are many billions of potential chemical compounds, and it is estimated that the industry does toxicity testing on perhaps seven compounds for every one that is eventually manufactured.
The secondary preventive aspects of the original TSCA, related to chemicals that were already in commerce, were far weaker for many reasons, including all of the difficulties in removing a product once it is in circulation. It required the use of risk assessment, a valuable technique for secondary rather than for primary prevention.
Public health theory and practice gives primary prevention far higher priority than secondary prevention. Yet the recent focus on amending TSCA has been on chemicals in commerce. Although of great importance, particularly with the limitations of the original TSCA, the risk of harm due to the inappropriate release of a new chemical is potentially far greater. Even assuming 99% effectiveness of existing toxicology testing aimed at avoiding a chemical with adverse reproductive and developmental effects, one of every hundred chemicals will not be adequately tested—and I personally doubt that current tests are 99% effective. Yet the new TSCA, like the European Union’s REACH regulatory program, though highly dependent on toxicology testing, does not focus sufficient resources on improving the effectiveness of testing techniques. Further, by requiring epidemiological evaluation of possible cancer clusters and an unnecessary focus on reduction in animal testing, it inherently reduces the priority that should be placed on primary prevention. Although epidemiology is important, a causal linkage between a chemical and cancer found in an epidemiological study in essence represents a failure of predictive toxicology. Let’s avoid such failures through better toxicological science.
Both articles point out that defining many of the central terms in the amended TSCA will require years of regulatory decision making and court battles. Unfortunately, neither the EPA’s leaders nor those adjudicating competing interpretations will be guided by a clear statement in the new TSCA of the relative importance of primary prevention in guiding the EPA for perhaps another 40 years.
Bernard D. Goldstein
Professor Emeritus and Dean Emeritus
University of Pittsburgh Graduate School of Public Health
To read the article by David Goldston and the one co-authored by Keith B. Belton and James W. Conrad Jr., one might be inclined to think that there were two different laws recently passed attempting to bolster chemical safety and regulation. That in and of itself might be the primary indicator for the future success or not of the Frank R. Lautenberg Chemical Safety for the 21st Century Act, otherwise known as the long-awaited update to the Toxic Substances Control Act (TSCA).
If history can tell us anything about the present (and it most assuredly can), then the authors are more than justified if they seem a bit worried about the future of chemicals management under the guidance of a reformed TSCA. Implementing a bill as multidimensional as TSCA proved to be a Herculean (maybe Sisyphean?) task in the first go-around. Will this second attempt, 40 years later, prove any easier?
Goldston offers some insider perspective on the evolution of this most recent iteration of the law and seems concerned that some of the flaws nagging implementation of TSCA over the past several decades may now be baked into this new version as well. He points, in particular, to issues such as preemption (i.e., federal law preempts attempts by states to impose stricter laws of their own) as signs of where the language appears strong and severe but is also ambiguous, which may prove an early indicator of where fights are most likely to crop up in the coming years. And although data sharing and confidential business information issues appear to have gotten a useful (if not perfect) upgrade, Goldston points out that provisions for applying TSCA and other forms of chemical controls over imports actually got weaker in the new law.
While Goldston seems most concerned about process and procedure in some of the murkier areas of the new TSCA, Belton and Conrad point to concerns with the uptake of new scientific models, methods, and practices. They point out that today’s toxicology has risk-assessment tools that were previously unavailable, and that there is a need to keep pace in the regulatory realm. But, they argue, these tools and techniques “are far from battle-tested”—that is, they aren’t quite up to the legal fight that will inevitably fall on their shoulders when they are used.
Though the procedural elements that Goldston raises are surely worrisome, in a sense they are a part of the standard implementation process and therefore anticipated sites for continued work. The scientific issues raised by Belton and Conrad, however, present one of the unique challenges of implementing a law such as TSCA. Over the past 40 years, the scientific infrastructure underpinning environmental and occupational health and safety, and more generally toxicology and human health, have evolved tremendously. The questions we ask, the ways in which we measure health, and our understandings of vulnerability and vulnerable populations have all changed dramatically. Endpoints, disease etiology, epigenetics and endocrine disruption, and the tools available to measure and identify chemicals at previously unmeasurable concentrations have all changed—and transformed how we think about and what we expect when we talk about safety and risk. How can we build resilient, adaptive regulatory systems that don’t take 40 years to be updated?
One key piece to building this sort of learning regulatory system is to ensure that the law is not abandoned during the course of implementation. In the first go-around 40 years ago, TSCA was orphaned shortly after birth. Changes in the oversight committees of TSCA, along with natural electoral changes, left TSCA abandoned in Congress. The nascent environmental community lacked the dedicated expertise and resources it needed to follow TSCA over the long haul. And since TSCA had emerged without a broad public foundation and the intricacies of the law were largely invisible outside of government operations, there was no public to hold anyone accountable. Even though the flaws of the original TSCA were many, its orphan status during its early, difficult years may have been the weakest aspect of the law. This time around, successful implementation will require participation and vigilance from a diverse group of stakeholders—the same group that helped to make this revision finally possible.
Jody A. Roberts
Director, Institute for Research
Chemical Heritage Foundation
Philadelphia, Pennsylvania
Rethinking biosecurity
In “Biosecurity Governance for the Real World” (Issues, Fall 2016), Sam Weiss Evans has done an excellent job of laying out the reasons why current biosecurity rules are ill-suited to provide the protection we seek against the misuse of biological knowledge. By framing the problem as one of controlling access to a limited number of “select agents” and monitoring only the life sciences research conducted with government funding, the current regime cannot help but be partial in coverage and almost certainly ineffective against a range of potential threats.
As usual, however, it is easier to see the faults in an existing set of institutions and rules than to devise a more workable remedy. Evans suggests that the biology community needs a group of indigenous professionals, similar to the “white hats” that have emerged in the field of computer/network security research that would police ongoing life science research in areas of concern. But just as the National Research Council concluded in what has come be called the Fink Committee report that the “gates, guards, guns” model employed in the area of nuclear weapons research was inappropriate for the diffuse and largely civilian biological sciences research community, it is questionable whether a concept that fits computer science would work for biology. Software is created in a form that is easily shared online; biological research, as Evans points out, is produced in laboratories, each with its own form of tacit knowledge and organizational culture.
Will the pharmaceutical companies, whose research is currently not covered by the federal government’s Dual Use Research of Concern rules except on a voluntary basis, be willing to fund professional biologists to monitor their research projects the way a company such as Microsoft might hire a “white hat” to debug its computer code? Could an insider designated to monitor research in a life science laboratory be expected to blow the whistle on the research of the lab leader? Is there a community of amateur biologists with the required professional expertise analogous to the amateur hackers who search through code for fun, and if so, how would they gain access to the biological research at an early stage, when control is still possible? The DIY biologists and BioArt communities might seem to fit the bill, except that their numbers are few compared with the hundreds of thousands of people with advanced degrees in the life sciences in the United States alone, and their access to established laboratories is almost nonexistent.
In short, the design of a new regime raises many problems that need to be analyzed using the approach that Evans champions in his critique of the current controls: it should respect the specific context of the biological sciences, including the diversity of settings in which research takes place and their national and international links to other laboratories. In the long run, the most effective response to biosecurity concerns is likely to lie in the slow process of increasing awareness of the issues in the life sciences community, a job that is likely to take more than one generation to accomplish.
Judith Reppy
Professor Emerita
Department of Science & Technology Studies
Cornell University
Recent advances in biotechnology, such as gene editing, gene drives, and synthetic biology, challenge the criteria and procedures put in place for identifying and regulating what the federal government considers to be Dual Use Research of Concern in the biosciences. It is increasingly difficult to flag experiments for additional scrutiny or limits on publication in the name of biosecurity. For example, with advances in gene editing, we can transform benign organisms into vehicles of toxicity or disease without technically inserting recombinant DNA, thus skirting regulatory definitions and the limits of detection.
In the face of these challenges, Sam Evans suggests that “instead of building fences around narrow objects of concerns, we should be building conversations across areas of relevant expertise.” Namely, he highlights approaches where “sensible scientists would turn to when they have a question about the security aspects of their research” as an alternative to the static lists of objects that trigger assessment and oversight, such as the Select Agents Rule and the roster of seven categories of experiments deemed to be of concern. Societal interests would be embedded in the design and conduct of research, as natural scientists reflect on the societal goals of their work with security as one of these goals, and in partnership with security experts. This is a laudable concept; however, I would argue that it will not be a reality without an umbrella of external, legal motivators and the wisdom of outside actors.
The history of environmental releases of genetically engineered organisms suggests that natural scientists are not prone to reflexivity or favorable to scrutiny beyond the norms of scientific integrity. They have balked at the idea of regulation, questioning its necessity and innovating around it through the use of gene editing; labeled as luddites those citizens and stakeholders with concerns about genetically engineered organisms; and discredited scientists who publish studies showing potential risk. What makes us think that biotechnologists with a vested interest in seeing their work progress would feel any differently when it comes to intentional threats (biosecurity) versus unintentional hazards (biosafety)?
A balance must, therefore, be struck between Evans’s model of self-governance in partnership with security experts (in a reflexive approach) and mandatory, legal mechanisms with external checks and balances. However, we are then back to the problem that Select Agent Rules, the Biological Weapons Convention, and other regulations cannot keep pace with advances in genetic engineering, gene editing, and synthetic biology. I suggest that we should consider models from the fields of public administration, risk governance, and environmental management that focus on adaptive, inclusive, engaged, and iterative approaches based in law, but with the flexibility to change with the technologies. These approaches should include the participation of those involved in the research, but not rely on them for prudent vigilance. They should also include different types of external experts who can more holistically and objectively evaluate potential for misuse, including those in ecological sciences, risk analysis, social sciences, political science, psychology, anthropology, ecology, business management, and world history, among others. The first step toward the design of such oversight systems is to dispense with the idea that self-governance by those invested in advanced biotechnologies is the foundation of future biosecurity. Then, the work can begin.
Jennifer Kuzma
Goodnight-NCGSK Foundation Distinguished Professor
Co-Director, Genetic Engineering & Society Program
North Carolina State University
Sam Weiss Evans crafts a compelling argument that our risk governance strategies rely on dangerously oversimplified assumptions about the relationships among science, security, and the state. As someone who has studied and managed safety and security policies within biotechnology research programs, I agree with the author’s assessment of the shortcomings of our governance regime and though he raises important policy considerations, his argument would benefit from a greater focus on implementation.
Evans grounds his argument in a critique of newly enacted US policies for the oversight of Dual Use Research of Concern (DURC). When asking “does DURC work?” he misses an opportunity to examine just what “working” entails. The DURC policies articulate multiple goals and guiding principles including control, monitoring, and awareness building. These goals signal a more complex appreciation of knowledge production and oversight, but they have become muddled in practice. Updates to the policies and their implementation may help realize the objectives that Evans promotes.
If controlling research with security risks is the primary goal of the DURC policies, then the author’s critique is well warranted. In practice, there is considerable ambiguity, uncertainty, and disagreement over the identification of DURC. Narrowing the policy scope to 15 agents creates artificial clarity about the policies’ application at the cost of real confusion about the policies’ purpose. Maintaining a broader scope of oversight could incentivize institutions to learn from a wider range of use cases and expose key gaps and needs.
Rather than controlling research, the DURC policies’ primary goal could be seen as an element of the monitoring regime that Evans promotes. New information collected about potentially concerning research (and researchers) via the policies could factor into broader threat assessments and mitigation plans. The DURC policies include as a stated goal the collection of information that should inform policy updates aimed at managing the risks of research. In practice, the policies lack a mechanism to update policy and an oversight entity to ensure that the data collected is useful and use. If a mechanism existed, the DURC policies might be updated (in concert with other oversight policies) to prompt the collection of additional information, such as accident data, that is important to risk assessments.
An overlooked goal of the DURC policies is raising security awareness. In practice, awareness often translates into rote educational tasks that strive for standard processes (i.e., a “code of conduct”). If DURC policies were more explicitly communicated as incomplete, they could prompt richer interactions among researchers, policy makers, and law enforcement officials. But supporting these interactions requires resources devoted to ongoing and collaborative security governance research in place of box-checking educational modules. In this function, the DURC policies are symbolic, helping to legitimate security as an important consideration of research.
When policies strive to achieve complex goals, we must ensure they don’t fall into foreseeable pitfalls in implementation. DURC policies are incomplete—but recognizing that this is by design can create productive paths forward.
Megan J. Palmer
Senior Research Scholar
Center for International Security and Cooperation
Stanford University
Sam Weiss Evans expresses concern about current efforts to manage risky life sciences research in the United States. He argues that these efforts seemingly rely on faulty assumptions. The author is right to be concerned. Our efforts to manage that small sliver of research with unusually high potential for adverse consequences if misapplied are inadequate and, in some cases, misdirected. In addition, these assumptions, as Evans describes, are clearly faulty. But in practice, the problems are even more complex: although some policy makers, security specialists, and scientists understand that knowledge is not discrete and that social context matters, they operate under perverse incentives, with insufficient tools, and without the benefit of appropriate expertise in social sciences.
Scientific investigation always involves choices about experimental design and approach for answering a question or addressing a hypothesis. Some designs and approaches will be riskier than others in generating information that might be exploited by others to do harm. Usually, scientists consider only technical feasibility, effectiveness, and expediency, because the research enterprise system rewards quick results with high impact and does nothing to reward risk awareness. Admittedly, identifying risk is difficult. Current research oversight policy is narrowly focused on a few specific infectious agents in order to be clear and concrete. We need a more comprehensive and generalized scheme for identifying the kinds of research results that require oversight. Certainly, the identification of risk should also consider the social context in which the work is conducted, but, as well, the unspoken social contract between scientists and the general public that demands avoidance of unnecessary harm.
How can we influence the choices made by scientists in the workplace about the specific questions they ask and the experimental approaches they take? Evans mentions the importance of communicating and making explicit contextual information regarding, for example, threat awareness and beneficial applications. Though helpful, alone this is not enough. Unless there is an understanding of and public discussion about conflicts of interest, we will not recognize selective and biased use of this contextual information. Deliberations about H5N1 avian influenza work in 2012 by the National Science Advisory Board for Biosecurity (of which I was a member) failed to acknowledge such conflicts, nor did they adequately address the timing and real-world delivery of putative benefits.
Additional perspectives and tools should be made available. We need to instill a sense of moral and ethical responsibility among scientists and other parties within the science research enterprise. New approaches (as yet to be described) for effective governance of scientific research are also necessary. Role models and incentives will be crucial. And none of this will work unless it is “forward-deployed”—that is, embraced by those in the “field” and by all those who stand to gain and lose by the conduct of the work about which we care so much.
David A. Relman
Thomas C. and Joan M. Merigan Professor in Medicine, and Microbiology & Immunology
Co-Director, Center for International Security and Cooperation
Stanford University
Chinese technocracy
China is well known for the technocratic character of its political structure and governance. A large number of political leaders either were trained as engineers or had extensive experience working in state-owned technical companies. Liu Yongmou’s article, “The Benefits of Technocracy in China” ( Issues, Fall 2016), offers a good, brief, historical and cultural interpretation of this fact and argues the relevance of technocracy to contemporary Chinese politics. It also challenges the common “antidemocratic” and “dehumanizing” view of technocracy in the West and invites Western scholars to reconsider their oppositions.
Complementing Liu’s argument would be a consideration of the influence of technocracy in current Chinese politics, given the decreased percentage of current politburo members trained in applied science and engineering. One explanation for this shift might be that current leaders were mostly educated after the Cultural Revolution or during the early years of the Reform and Opening-Up, when the focus of national development shifted toward reconstructing the social and political order, which required experts from the humanities and social sciences. Over the past 30 years China has been in transition from a centrally planned economy to a socialist market economy. The national economic system became less centralized, and more state-owned companies were either integrated with private capital or transformed into private firms. Thus, engineers had fewer opportunities to be promoted to higher leadership positions in the government through the meritocratic system, and more engineering students were interested in going to work for private firms where they could earn much higher salaries.
It is important to realize that government workers and Communist Party cadre do not earn the high salaries typical of those working in private corporations. Today, there may also be more political leaders from political science, law, and economics because of China’s increasing interest in promoting social equality and global economic and political influence.
Another complementary topic concerns the connection between technocracy and meritocracy in Chinese politics. Certainly, loyalty to the Party and strong relations with Party leaders are crucial for elite selection and promotion. However, without a certain threshold of competency, including the ability to understand technical and economic indicators for development, anyone in power can have his or her legitimacy challenged by upper-level leaders, peers, subordinates, and the public. Success in managing economic development remains the most important factor for evaluating the performance of political leaders. The elite selection system in China today might be more appropriately called “techno-meritocracy”—that is, the most qualified political leaders are arguably still those who have passed numerous rounds of “tests” on their competency in promoting economic development driven by technological change. Officials may gain power not through a political meritocratic system, but their legitimacy can always be criticized on the basis of technological meritocratic criteria. As Liu Yongmou rightly suggests, this is one of the strengths of the current Chinese techno-meritocratic political system.
Qin Zhu
Ethics Across Campus Program
Colorado School of Mines
There are few, if any, of the “benefits of technocracy in China” described by Liu Yongmou with which I would disagree. I have, in fact, insisted that scientistic and technocratic movements have played a central role in increasing the production of material goods and the effective providing of public services wherever they have been employed, and I am convinced that many public decisions in today’s world unavoidably depend in large part on technically competent advisory input.
Moreover, Liu is undoubtedly correct in arguing that modern technocracy in China, which began with the ascendance of Deng Xiaoping, is consistent with a long-standing Chinese tradition of government by an intellectual elite symbolized by the Confucian call to “exalt the virtuous and the capable.” He is also correct in pointing out that knowledge traditionally was more important than the representation of the interests of the people, and that virtue was privileged over capability, but also that in modern China, while knowledge remains more important than expressions of the interests of the people, the traditional emphasis on virtue has been given lower priority. This is where my view of technocracy in modern China begins to diverge from that of Liu.
The technocratic branch of modern economics, which has been driving Chinese policy, places a high priority on economic growth. Justification for this priority has come from the assumption that in a growing economy labor demand will be high, so wages will be relatively high and the wealth produced will thus be distributed, in significant part, to workers. Yet since the mid-nineteenth century in the advanced industrial world, economic growth has been produced almost exclusively by technological innovations that have had the effect of lowering labor demand and increasing wealth concentration. Technocrats have historically been insensitive to issues of wealth concentration, and that seems to have been true in China. Relatively short-run increases in labor demand are very likely to diminish even as the economy continues to grow, exacerbating the concentration of income that saw China’s Gini coefficient (a measure of income dispersal for which equality = 0 and all income to a single individual = 1) grow from 0.30 in 1980 to 0.55 in 2012.
There is a second downside to a technocratic elite that, as in China, is particularly hostile to criticism and that can, as a result, afford to be narrowly focused. The heavy emphasis on engineering, and more recently on economic, expertise, both of which focus on efficient production, has not, to date, been balanced by expertise in the psychological consequences of intense work environments or on the environmental consequences of focusing exclusively on producing specific material goods. One consequence has been that even where relatively high wage jobs have become available, suicide rates have increased among workers, and the health costs of pollution have exploded.
As Liu Yongmou pointed out, I have argued elsewhere that engineering education has been broadened, making some forms of technocracy more open to considering a broad range of issues ancillary to the primary focus of policy decisions, and that may mitigate some of the negative effects of technocracy in China—but the evidence on this issue is still fragmentary.
Richard Olson
Professor of History of Science and Willard W. Keith Jr. Fellow in Humanities
Harvey Mudd College
Green accounting
In “Putting a Price on Ecosystem Services” ( Issues, Summer 2016), R. David Simpson provides a thoughtful assessment of the concerns raised by the valuation of ecosystem services. I, like Simpson, have been working in this area for close to two decades. I have marveled at the ascent of ecosystem services from obscure terms in the mid-1990s to near ubiquity today, while expressing concern that the concept’s mainstreaming risks meaning all things to all people.
Simpson’s core concern is that “The assertion that ecosystem services are undervalued is repeated so often, and so often uncritically, as to seem almost a mantra.” He points out, rightly, that few studies have credibly provided economic valuations of service provision in the field, and that in many cases service provision may not actually be worth very much. He is certainly correct that location matters. At the same time, if service provision is simply ignored in land use decisions, as is often the case, then their value becomes zero. That is almost certainly incorrect. I would suggest though, that focusing on the inadequacies of service valuation risks missing two larger points.
First, although economic valuation and big numbers may prove rhetorically important in persuading policymakers that they should pay attention to the provision (or loss) of services, calculating their dollar value can often be irrelevant to policy decisions where the key concern is relative cost. In the celebrated story about New York City’s drinking water, for example, officials had to choose between ensuring water quality through a built treatment plant or land use investments in the Catskills watershed. Investing in the Catskills proved much less expensive. In this case and others, the absolute value of the ecosystem service doesn’t matter. The question is whether it is wiser to invest in “built” or “green” infrastructure, and this is relatively easy to calculate. Yes, valuing ecosystem services is hard and we are still not very good at it, but that doesn’t matter when choosing between policy options.
Second, marginal biophysical valuation is usually more important than economic valuation. Following on the previous paragraph, decision makers need to know how much service bang they are getting for the buck. This requires far better understanding of the science of service provision. We know with confidence that paving over an entire wetland can cause water quality problems. But what is the impact on service provision if the development removes just 10% or 20% of the wetland? This type of piecemeal loss is where most land use decisions take place; yet the science in this field remains nascent. Contrast this, for example, with our understanding of marginal productivity for agricultural lands. We are very good at managing land to provide ever more food per acre. We simply do not have similar experience explicitly managing land to provide services or prevent their loss.
Simpson rightly cautions over the need for rigorous and credible economic valuation, but it is equally important to recognize that, for many land use decisions in the field, absolute valuation is less important than the relative costs of service provision and biophysical valuation.
Jim Salzman
Donald Bren Distinguished Professor of Environmental Law
Bren School of Environmental Science & Management
University of California, Santa Barbara
The Importance of Middle-Skill Jobs
Globalization and advances in science and technology are transforming nearly every aspect of modern life, including how we communicate with each other, how we shop, how we make things, and how and where we work. In response, US firms are seeking workers with greater proficiency in basic literacy and numeracy as well as more developed interpersonal, technical, and problem-solving skills. For the United States to remain competitive on the world stage while fostering greater innovation and boosting shared prosperity, it needs not only a sufficient number of workers, but also a workforce with the right mix of skills to meet the diverse needs of the economy and to fully engage in civic life.
Yet employer surveys and industry reports have raised concerns that an inadequate supply of skilled workers could hamper future economic growth by creating barriers for firms looking to locate or expand in the United States. Indeed, there has long been a concern that shortages sometimes develop and persist in specific industries or occupations, leading to inefficiencies in the economy. More recently, it has been suggested that the lack of skilled workers has made it difficult to fill jobs that are in high demand during the economic recovery, leading to slower than expected improvement in the labor market—particularly among “middle-skill” jobs that require some postsecondary education and training, but less than a four-year college degree.
Compounding the problem in the middle-skill sector is a demographic shift in which a significant portion of the existing workforce consists of baby boomers nearing retirement, with fewer younger workers to replace them. At Boeing, for example, 28% of the firm’s 31,000 machinists are older than 55 and eligible for retirement. The combination of the upward shift in skills on the demand side and the decline in the number of experienced workers on the supply side is likely to give rise to the sorts of labor market anxiety that is reflected in employer surveys, particularly in health care, manufacturing, and production. However, few employers have raised wages in response to the difficulty in hiring skilled workers, although some reports indicate that this may be due to competitive factors in industries where the pressure to limit costs is great and outsourcing is an option.
This potential mismatch in the labor market has important implications for both the economy and the individual worker. For the economy, an insufficient number of middle-skill workers means that the rate at which employment and output can grow is constrained. Slower employment growth means tighter labor markets that may require firms to find innovative ways, such as outsourcing or automation, to increase productivity in the face of rising labor costs, raising concerns about the types of jobs that will be created and the possibility of lost opportunities for workers. It also means slower growth in tax revenues at a time when a greater share of the population will be retiring and drawing support from public programs such as Social Security and Medicare.
For the individual worker, obtaining a sufficient level of skill is critical to maintaining employment and is associated with a range of better outcomes. A recent international survey of adult skills by the Organisation for Economic Co-operation and Development’s Program for the International Assessment of Adult Competencies demonstrates the problem. The survey assessed the proficiency of adults from age 16 to 65 in literacy, numeracy, and problem solving in technology-rich environments. The most recent published report includes survey data on more than 165,000 adults in 22 of the organization’s member countries and two partner countries. It revealed that skills have a major impact on life chances: lower-skill individuals are increasingly likely to be left behind, leading to greater inequality in income. Having lower basic skills also impedes the ability of individuals to gain more education or training when demand shifts toward industries or occupations that require additional competencies. Finally, those with lower skill proficiency tend to report poorer health, lower civic engagement, and less trust.
Defining middle-skill workers and jobs
Many scholars and practitioners point to a lack of middle-skill workers, yet one can obtain vastly different estimates of shortages and mismatch based on how this group is defined. To measure the number of middle-skill workers in the labor force, researchers typically rely on the education level of the workforce as a proxy for skill. This is largely due to data limitations as nationally representative demographic surveys that cover work and education experiences do not ask about their other types of training or particular skills acquired.
Using this method, researchers typically define middle-skill workers as individuals with some postsecondary education, but less than a four-year college degree. (Similarly, low-skill workers are defined as those with a high school degree or less and high-skill workers are defined as those with a bachelor’s or advanced degree.) Postsecondary education or training requirements can include associate’s degrees, vocational certificates, significant on-the-job training, previous work experience, or generally “some college” without having earned a degree. Workers in this category typically hold jobs in the clerical, sales, construction, installation/repair, production, and transportation/material moving occupational groupings. Using this definition, there were 37.7 million middle-skill workers in the labor force as of 2015, according to the US Bureau of Labor Statistics. The share of middle-skill workers in the population has been increasing steadily, rising from 28.7% of the population in 2006 to 33.4% in 2012. This is primarily due to a greater share of individuals having gained some postsecondary education rather than having completed an associate’s degree—likely reflecting the low completion rates at community colleges. In comparison, over the same period, the share of low-skill workers decreased by 7.5 percentage points while that of high-skill workers increased by 2.7 percentage points.
Policy makers at all levels have an opportunity to make the workforce development system more demand-driven and accountable to better support the middle-skill workforce.
To measure the number of middle-skill jobs, researchers have typically used either a relative or absolute ranking to determine skill level based on education or wages. For example, relative rankings classify occupations by skill level from lowest to highest and then use cutoffs at specific percentiles of the distribution to determine what falls into the “middle” (e.g., occupations falling into the 20th to the 80th percentiles). In contrast, absolute rankings of middle-skill jobs use pre-defined skills criteria for specific jobs (e.g., education beyond high school, but less than a four year degree) and then categorize occupations accordingly.
Using the latter method, I identified 272 middle-skill occupations in which more than one-third of the workers have some college or an associate’s degree. These include jobs in health care (technicians, EMTs, therapists); education (teacher assistants); information technology (network administrators, computer support specialists); and other growing occupations. Between 2006 and 2012, labor demand decreased for low-skill jobs (down 5.4 percentage points), increased for high-skill jobs (up 6.6 percentage points), and held steady in the middle at just under one-third of all jobs.
Harry Holzer has observed that a sizeable share of these occupations have undergone a shift from high-volume, low-tech jobs to low-volume, high-tech jobs—prime examples of the “new” middle-skill labor market. Although the historical middle of the job market (composed primarily of construction, production, and clerical jobs that require fairly little education) has indeed been declining rapidly, another set of middle-skill jobs (requiring more postsecondary education or training) in health care, mechanical maintenance and repair, and some services is consistently growing, as are the skill needs within traditionally unskilled jobs.
As a result of this shift, some observers have pointed to recent labor market indicators suggesting that a potential mismatch already exists in the short run between the skills of those looking for work and the needs of employers looking to fill vacant jobs. Indeed, the National Governors Association Center for Best Practices estimated in 2011 that of the 48 million job openings projected through 2018, 63% would require some postsecondary education. At the time, only approximately 42% of the current workforce had an associate or higher degree, and the association calculated that the nation would need to increase the current level of middle-skill workers by 3 million by 2018.
However, there is considerable controversy about the nature of labor market shortages and middle-skill gaps or mismatches. On one hand, the persistently high rate of unemployment coupled with a rising share of vacancies would seem to indicate some type of mismatch in the labor market. Indeed, during this period, the share of workers with a college degree increased rapidly within middle-skill occupations. Yet on the other hand, the lack of wage growth observed even within industries and occupations with relatively strong demand would suggest otherwise. As a result, economists have been searching for ways to measure the degree to which the perceived mismatch in the labor market might be due to cyclical (e.g., short-term or temporary adjustments) versus structural (e.g., long-term or sustained trends) forces. Unlike mismatch due to cyclical causes, structural mismatch will persist even as economic conditions improve, possibly warranting a change in labor market policies.
Setting aside the mismatch debate, significant demographic changes suggest that the supply of skilled workers may not keep pace with demand in the long run. The retirement of the baby boomers—a well-educated group—will result in large numbers of skilled workers leaving the labor force. In addition, the population of native workers who are needed to replace those retiring has been growing more slowly over time such that net international migration is projected to be the dominant component of population growth by 2025. This shift toward greater reliance on immigration as a source of population will alter the composition of the labor force in terms of educational attainment. Although the share of individuals with a bachelor’s degree or higher is similar across native and immigrant populations, immigrants are more likely to be high school dropouts or to lack additional postsecondary education beyond high school, such that these individuals often lack the formal education and English language skills that employers require. As a result, some observers suggest that there is likely to be a potential mismatch between the level of education and skill among the population and the needs of employers in the coming decades.
Trends in the middle-skill labor market
Does the supply of middle-skill workers meet the demand of employers now and in the foreseeable future? To address this question, it is helpful to examine data and analyses on the current supply of and demand for workers, as well as the forces that are likely to affect supply and demand conditions over time. Although it is inherently difficult to measure the imbalance between labor supply and demand, as both forces are changing over time and the movement of one affects the movement of the other, it is still instructive to look at trends over time to detect changes in the magnitude or direction of any potential gap.
Current patterns. One way to measure the current imbalance between supply and demand within groupings is to look at vacancy rates by detailed occupations. Specifically, I examined job vacancy measures to determine which major occupation groups experienced the tightest labor market conditions as of the most recent peak of the business cycle (2006), and whether these conditions persisted through the recovery (2012).
It turns out that those major occupation groups with persistently high vacancy rates employ a relatively high share of both middle- and high-skill workers. These include occupation groups with “critical” vacancies as evidenced by having both a higher than average vacancy rate (number of vacancies as a percent of total employment) and vacancy share (number of vacancies as a percent of total vacancies). Critical vacancies are largely found in management, business and financial operations, computer and mathematical science, architecture and engineering, and health care and technical occupations. Contrary to conventional wisdom, these professional occupations—categories often labeled as high-skill—contain a significant percentage of middle-skill jobs.
Within these major occupation groupings, critical vacancies exist in occupations that primarily employ middle-skill workers. For example, within the health care and technical occupation group, critical vacancies exist in occupations such as medical and clinical laboratory technicians, surgical technologists, licensed practical and licensed vocational nurses, and medical records and health information technicians; these are jobs that employ a high share of workers who possess only some college or an associate’s degree. Moreover, most of these middle-skill occupations exhibit high and rising wages as well as projected growth through 2022.
In fact, middle-skill jobs are sprinkled throughout the broad occupation categories, suggesting that such workers are not contained in just a few easily identifiable sectors. Moreover, many of the jobs held by middle-skill workers appear to be complementary to those held by high-skill workers. For example, hospitals need both physicians as well as nursing and other support staff—jobs not easily automated or outsourced. Engineering firms need both engineers as well as technicians. Businesses need both systems analysts as well as computer support specialists. Among all detailed occupations that exhibited critical vacancies, those that employed a greater share of middle- and high-skill workers had higher job vacancy rates both before and after the Great Recession, suggesting that there may be a limited set of jobs that are difficult to fill in key sectors of the economy such as management, business and financial operations, computer and mathematical sciences, and health care.
How will the skills of new market entrants match up with demand? Recent media reports and surveys of job posting data suggest that employer requirements for education within occupations shifted during the Great Recession and subsequent recovery. In particular, it appears that a college degree is now required for a number of middle-skill occupations. For example, according to a survey by CareerBuilder in late 2013, almost one-third of employers said that their educational requirements for employment have increased over the past five years, and, specifically, that they are now hiring more college-educated workers for positions that were previously held by those without a bachelor’s degree.
Looking within detailed occupations reveals substantial upskilling for some occupations that have historically been dominated by workers without a college degree, suggesting that entry-level middle-skill workers face an ever-rising bar. For example, a recent report by Burning Glass Technologies found that 65% of online vacancies for executive secretaries and executive assistants now call for a bachelor’s degree, but only 19% of individuals currently employed in these roles have such a degree. In other occupations, such as entry-level information technology help desk positions, the skill sets indicated in job postings do not include skills typically taught at the bachelor’s level, and there is little difference in skill requirements for jobs requiring a college degree from those that do not. Yet the preference for a bachelor’s degree has increased. This suggests that employers may be relying on a bachelor’s degree as a broad recruitment filter that may or may not correspond to specific capabilities needed to do the job.
Interestingly, upskilling appears to be less likely when there are good alternatives for identifying skill proficiency. For example, many health care and engineering technician jobs, such as respiratory therapists, show little sign of upskilling. It may be the case that these positions are resistant to the use of higher education as a proxy because they are governed by strict licensing or certification standards, well-developed training programs, or measurable skill standards.
Future projections. How will the supply of middle-skill workers meet demand in the foreseeable future? To answer this, I analyzed aggregate data on projections for both the supply of and demand for skilled workers by education level. Specifically, I use a cohort component model to project the size and educational attainment of the population in five-year age groups by nativity and race/ethnicity over the coming decade (2012 to 2022) as new cohorts enter the labor force and older ones retire and then aggregate over groups to obtain estimates of the total labor force. I compare these supply simulations to projections of labor demand based on employment growth forecasts made by the Bureau of Labor Statistics through 2022 for each detailed occupation and then aggregate over occupations to the economy-wide level.
On the supply side, the number of middle-skill workers is likely to hold steady, but the composition will change such that it is unlikely to keep pace with demand in the not-so-distant future. Among individuals with middle-skill credentials, the share of labor force participants with some college is projected to increase while those earning an associate’s degree will remain stagnant. It is also important to note that these projections may overestimate the supply of middle-skill workers as labor force participation has been declining, particularly for those with less than a college degree.
On the demand side, projections of future employment indicate rapid growth among major occupation groups that employ a high share of middle-skill workers, particularly in health care. Middle-skill occupations in the health care field that are likely to be in high demand include medical and clinical laboratory technicians, surgical technologists, and licensed practical and licensed vocational nurses—almost identical to those where critical job vacancies currently exist. These jobs typically involve tasks that require personal interaction or abstract thinking and are unlikely to be outsourced or automated in the future, unlike other middle-skill jobs, such as telemarketers, clerks, and computer operators.
Will the education/skill levels of future labor force participants stack up against those demanded by firms over the next decade? Prior to the Great Recession, there was a mismatch in the middle of the labor market that abated with the massive job destruction that occurred during the downturn. As the economy strengthens, our projections indicate that by 2022, any future mismatch in the distribution of labor supply versus demand would again be likely to occur in the middle of the distribution. In this category, the percent of middle-skill jobs in the economy is likely to exceed the percent of middle-skill workers in the labor force by roughly 1.3 percentage points. In addition, as baby boomers continue to retire over the coming decade, the absolute number of middle-skill workers is likely to fall short of demand. By 2022, the number of middle-skill jobs is projected to exceed the number of middle-skill workers by 3.4 million. Moreover, these projections are rather conservative and are likely to underestimate any future skill imbalances as they are based on the current educational requirements of jobs and these requirements tend to generally increase over time.
Although these projections can indicate where future investments in human capital may be warranted, it is crucial to note that the future path of employment will be determined not only by the demands of employers and the skills of existing workers, but also by future unexpected adaptations. Thus, these forecasts of future labor demand are used only to place bounds on the problem and provide context rather than to pinpoint the exact number of workers that will be demanded in the future. Indeed, there are likely to be some labor market adjustments over the next decade in response to any potential gaps on the part of both workers and employers. Workers may adjust by obtaining more education or training or applying current skills in their existing jobs to growing occupations. Employers may adjust by adopting new technologies, outsourcing, or restructuring jobs.
Overcoming market frictions
How can the nation ensure that its workers have the skills to meet these new and changing needs, and how can the match be improved between the demand for and availability of skills? Economic theory suggests that it should be possible to rely on market incentives. In the short run, rising wages will encourage greater labor market participation and in-migration on the part of skilled workers to help alleviate the shortage. In the long run, higher returns to skilled labor will encourage individuals to obtain more education and training and create incentives for firms to find innovative ways to increase labor productivity.
But labor markets in the economy do not function perfectly all of the time. This might occur if wages are constrained by wage controls, pricing regulations, competitive pressures, equity concerns, or imperfect information such that they cannot rise in response to an increase in labor demand. Another possibility is that the pace of technological change will be sufficiently rapid that the demand for skilled workers continually grows more rapidly than the supply.
Indeed, there are certain conditions that can create persistent labor market imbalances, particularly for middle-skill markets where demand can change rapidly and the incentives for adjustment on the supply side are weak. On the demand side, structural changes associated with advances in science and technology and competitive forces have been shown to accelerate middle-skill job creation and destruction over the course of the business cycle. In addition, the cost of finding, hiring, and developing middle-skill workers can act as a disincentive for firms, creating additional frictions. A 2014 survey by Accenture of human resource professionals, indicated that employers use higher levels of education as a proxy for employability rather than hiring workers based on demonstrable competencies that are directly related to job tasks. Indeed, my research shows that employers chose to raise credential requirements quite suddenly during the Great Recession, at least in part because more educated workers were in greater supply and could be hired “on the cheap.”
On the supply side, there are additional frictions present that make it difficult for middle-skill workers to obtain the necessary credentials on their own. For example, lack of information about job requirements can make it difficult for workers to develop requisite skills. Moreover, if certifications or experience do not easily transfer across jobs, occupations, sectors, or geographic areas, then workers have less incentive to invest in such training. In addition, required training that is lengthy or costly might mean that workers cannot capture the value of their educational investment.
Finally, the efficacy of education and training programs and their ability to adapt to changing skill requirements has also been identified as a potential source of friction in middle-skill labor markets. Institutions that provide education and training for middle-skill workers, particularly community colleges, often have inadequate resources and weak incentives to expand capacity in their technical workforce courses or to boost completion rates. Moreover, inadequate development of basic skills in the K-12 system, especially in science and mathematics, can limit the ability of individuals to invest in technical middle-skill postsecondary training down the road in occupations such as health care. Finally, inaccurate or outdated perceptions of certain occupations, such as manufacturing, can also reduce incentives for individuals to invest in training notwithstanding the strong job prospects in those sectors.
Despite the difficulties in measuring skill shortages and mismatches, there is sufficient evidence that middle-skill markets may not be clearing as efficiently as they could and these frictions are likely to be exacerbated by business cycles and global trends. As a result, the nation’s approach to workforce development and skills acquisition must acknowledge and overcome these frictions in the labor market. Whereas older middle-skill jobs in occupations such as production and transportation are being eliminated through automation and outsourcing, newer middle-skill jobs that require the ability to use technology are in high demand in growing occupations such as health care, high-tech manufacturing, and information technology. Many of the newer middle-skill jobs require only secondary degrees or certificates while offering salaries and benefits packages as well as the opportunity to advance to better positions. If sufficient information and resources about these jobs are generally available, they can potentially be filled by people with high-quality education and training provided by community colleges, vocational and career technical education programs, apprenticeships, and a growing number of web-based educational programs.
Developing and sustaining skills proficiency is essential to sustaining US leadership in innovation, manufacturing, and competitiveness and to creating and retaining high-value employment. As policy makers work to tackle the challenges of social and economic development at local, state, and national levels, they must consider whether they are creating the conditions that will prepare citizens for middle-skill jobs that provide a pathway to sustainable employment at a living wage. With the implementation of the recently re-authorized Workforce Innovation and Opportunity Act of 2014, policy makers at all levels have an obligation to make the workforce development system more demand-driven and accountable to better support the middle-skill workforce. For example, sector-based partnerships between employers and postsecondary institutions can provide curriculum tailored to employer skill requirements so that students acquire a set of skills that are in high demand, often leading directly to a job upon graduation.
Regardless of the policy response, it is important to keep in mind that interventions should be assessed for their effectiveness and efficiency, as well as for their distributional effects. Initiatives to encourage high-quality education and workforce development programs need to keep employers engaged while maintaining a focus on serving less-skilled populations lest administrators be tempted to engage only those students who can produce the best results. Finally, it must be recognized that the nation needs to balance general and specific skill-development needs. Although sector-based or occupation-specific programs may deliver the biggest bang for the buck in the short term, if these are not balanced with general skill development, workers may find themselves back at square one when demand shifts.
Defining Skilled Technical Work
The nation needs to better understand and more effectively develop this essential component of the US workforce.
Humans were generally poor until the industrial revolution unleashed a flurry of innovative activity. Many might assume that the intellectual and entrepreneurial breakthroughs were driven by highly educated elites who graduated from leading universities. In fact, it is well documented that high-skilled blue-collar and technical workers, in machinist and production occupations and typically with no post-secondary training, made the largest direct contributions to innovation during the industrial revolution, as measured by patenting activity and other indicators. The predominance of blue-collar workers in technological innovation continued well into the second half of the twentieth century.
As employment in manufacturing has gradually eroded, skilled technical workers—varyingly called trade workers, craft workers, or somewhat more pejoratively, middle-skilled workers—have received little attention among social scientists, but many of these occupations remain a viable pathway to the middle class for millions of Americans and play a critical role in maintaining the nation’s economic productivity. Thus, a more precise understanding of these occupations and their training requirements could lead to fruitful policy reforms that enhance individual well-being and national economic vitality.
The study of skilled technical workers goes back to the origins of economics as a disciple. In The Wealth of Nations, Adam Smith offered a succinct definition of skilled laborers: “The policy of Europe considers the labor of all mechanics, artificers, and manufacturers, as skilled labor.” He distinguished this group from skilled professionals, such as academics and lawyers.
Contemporary scholars have defined this group of skilled technical workers variously by their occupational categories, their wages, or educational characteristics. Some define middle-wage occupations as having earnings between 75% and 150% of the US median wage. Within middle-skilled jobs, economists have also distinguished between occupations that perform routine versus nonroutine tasks or those in newer and growing versus older and declining occupations. A report from the National Research Council defines middle-skilled jobs as requiring education or training beyond high school, but less than a four-year degree.
There are strengths and weaknesses in all these definitions. Using wages to gauge middle-skilled occupations can be misleading because workers in the middle of the wage distribution may be relatively unskilled but compensated well because of union contracts or other characteristics of the industries in which they commonly work. Likewise, some low-wage occupations may be relatively skilled but experiencing negative wage trends as a result of trade, immigration, or technological change. Using educational requirements also runs into difficulty because there is tremendous variation in the technical skills of people who have the same level of education.
For these reasons, it is important to include measures of skill in the definition of skilled technical workers, for it is their mastery of certain knowledge domains and techniques, not their level of education or salary, that distinguishes them. I propose that a skilled technical occupation should meet two criteria: a high level of knowledge in a technical domain and openness to workers without a bachelor’s degree.
The first criterion distinguishes low-skilled jobs from skilled jobs. It also distinguishes occupations that require nontechnical knowledge such as writing, law, foreign language, management, and sales from those requiring technical knowledge. For the purposes of this definition, technical knowledge refers to the domains listed in Table 1. They extend a little beyond what is usually considered science, technology, engineering, and math (STEM) knowledge.
Within these fields, the next step is to define what a “high” level of knowledge means. I propose using the Department of Labor’s Occupational Information Network (O*NET) classification that rates the skill requirement for all jobs on a scale of 1 to 7. A score of 4 is the midpoint, and I use a cutoff of 4.5, which reflects a significant component of cognitive math skill. The second criterion is needed to distinguish skilled technical work from skilled professional work, which usually requires at least a four-year degree.
Findings
Using the previously mentioned definition, 16.1 million US workers (11.9% of the total workforce) were employed in skilled technical occupations as of 2014. This is a smaller number than what would result from using other criteria. If one used education beyond high school but less than a four-year degree, the percentage would be 16.2%, and if one used the wage distribution of 75% to 150% of the median wage, the total would be 23.1%.
It is widely believed that tacit or informal knowledge—as opposed to that gained through formal education—is important for skilled technical workers. As defined here, skilled technical workers do, indeed, work in occupations that require more experience and training than the average occupation. Likewise, on-the-job-training requirements are significantly higher for skilled technical workers relative to the other two middle-skill definitions.
Notably, the tasks and skill levels of the definitions are quite different. Broadly speaking, the skilled technical occupations report higher general knowledge requirements, greater knowledge in STEM disciplines, specifically, and greater knowledge in the fields most relevant for technical work. On cognitive skill, however, as measured by the ACT WorkKeys exam, each set of occupations performs slightly above average and the differences are not statistically significant among the definitions.
Of the occupations that comprise the skilled technical workforce, very few entail many routine tasks. This may indicate that they are relatively unlikely to be offshored or supplanted by computers in the short term. Previous research identifies clerical occupations, heavily concentrated in administrative positions, as most likely to be exposed to pressure from automation, but just 1% of office and administrative support occupations qualify as skilled technical workers.
Where do they work?
Skilled technical workers are found in a diverse array of occupations. Indeed, of the 22 major occupational categories identified in O*NET, only five have zero occupations that meet the criteria. Most skilled technical workers are in “blue collar” occupations: installation, maintenance, and repair; construction; production; protective services; and transportation and material moving. Yet, many are in traditionally professional occupational families. The second largest group—representing 3.3 million jobs—is health care practitioner and technical occupations, and the fifth largest group—representing 0.82 million workers—is computer and mathematical occupations. Architectural and engineering occupations comprise another 0.65 million.
The occupational family with the highest percentage of skilled technical workers is installation, maintenance, and repair, which also has the highest absolute number of such workers. This category includes general maintenance and repair workers, automotive technicians and mechanics, supervisors of mechanics, machinery mechanics, and HVAC installers. Construction and extraction is next, with just over half of all workers qualifying to be part of the skilled technical workforce. Surprisingly, perhaps, just under one-third of production occupations meet the criteria. Most of these jobs simply do not report sufficient skill levels to qualify, but those that do include carpenters, electricians, plumbers, building inspectors, and telecommunications installers. Computer and mathematical occupations are almost as likely as production occupations to qualify, with 22%. Three titles—computer user support specialists, computer network architects, and web developers—qualify in this family. Registered nurses (within health care practitioners) represent the largest specific skilled technical occupational category. Machinists and production supervisors also qualify under production occupations, as do firefighters under protective service occupations.
Consistent with their distribution across occupations, a high percentage of skilled technical workers report mechanical expertise (52%). A smaller but still large percentage qualify as skilled through medical expertise (21%), knowledge of building and construction (19%), or understanding of computers and electronics (13%). High knowledge scores in other fields, such as economics or physics, are fairly infrequent for skilled technical workers, perhaps because it is difficult to obtain such knowledge without a bachelor’s degree.
Skilled technical occupations disproportionately employ workers with sub-bachelor’s level higher educational credentials. Almost one-quarter of skilled technical occupations report a postsecondary certificate as their highest level of education, compared with only 6% of all other workers. This makes a certificate the most common level of education besides a high school diploma for skilled technical workers. Another 15% of skilled technical workers have earned an associate’s degree, compared with 6% of all other workers. Relative to the rest of the US workforce, skilled technical workers are much more likely to have a postsecondary education beyond a high school diploma, but less likely to have earned a bachelor’s or higher degree.
Although bachelor’s level education is lower for skilled technical workers, on-the-job training is significantly higher. Skilled technical workers report receiving eight months longer on-the-job-training compared with the average worker in other occupations (weighted by employment). Moreover, skilled technical workers tend to have an extra year of experience. Both differences are statistically significant. Taken together, they provide further evidence that skill levels are relatively high for skilled technical workers, even if acquired through less formalized channels, such as on-the-job training and learning.
Policy implications
A broad policy goal of the United States should be to maximize the opportunities of youth and displaced older workers to acquire valuable skills. This requires optimizing policy interventions at multiple stages of life.
Throughout childhood and early adolescence, preparation for a job as a skilled technician should look the same as preparation for a skilled professional job at the highest level of sophistication. In other words, high-quality education in math and reading need to be universally available at the earliest years. A number of rigorous studies show large benefits to high-quality prekindergarten education, but it is rarely provided by the government and is thus unaffordable to the children who would benefit the most from it.
US children and adults consistently underperform their peers in other developed countries on tests of mathematics and science ability. Fortunately, a large and growing literature finds that various school reform policies—such as access to high-quality charter schools, vouchers for low-income children, and sophisticated teacher accountability and pay policies—raise the quality of public education, leading to improved test scores, education levels, and future earnings.
School districts and states can also adopt curriculum-based policies that increase learning opportunities in technical fields. For example, the Virginia Beach school district partners with a local community college to allow any high school student in the district to take rigorous STEM or technical courses that lead directly to industry-designed certificates. Approved apprenticeships at companies that provide on-the-job training should also count toward high school credit.
Likewise, as Harry Holzer has argued, states should use their funding power to provide clear incentives and encouragement to better align funding with high-quality college education. One important and readily measurable aspect of quality relates to the earnings of attendees. My research finds that even fairly crude measures of alumni economic outcomes can be used to construct value-added metrics, which perform better than popular college rankings and can inform the public about the strengths of community colleges and nonselective four-year schools. States should use tax and high school administrative records to construct comprehensive measures of earnings, test scores, and family income to measure and report the value added by colleges for each broad field of study and use these data to inform funding decisions. Finally, as argued by Mary Alice McCarthy, the accreditation process in higher education is flawed as it relates to career and technical education. Presently, institutions rather than fields of study receive accreditation, which misses the important and specific link between a course of study and occupational success.
Workforce policy at the state and federal level should also consider how unemployment insurance, welfare payments, and workforce funding could be better arranged to foster the development of technical skills. Recipients should have the flexibility to maintain benefits while embarking on training or even to use the benefits to pay for training, and government agencies should collect better outcomes data at the program level to evaluate which programs and providers are providing the most value.
The skilled technical workforce performs a number of functions that are critical to innovation, health care, infrastructure, and economic growth. It is therefore important for policy makers to understand the tasks, skills, and training required of these occupations, and consider whether public resources are adequately meeting industry and social demand for these workers.
Jonathan Rothwell is senior economist at Gallup Inc., in Washington, DC.
Recommended reading
Timothy Bartik, From Preschool to Prosperity: The Economic Payoff to Early Childhood Education (Kalamazoo, Michigan: W.E. Upjohn Institute for Employment Research, 2014).
Harry Holzer and Robert Lerman, “The Future of Middle-Skill Jobs” (Washington, DC: Brookings Institution CCF Brief #41, 2009).
Harry Holzer, “Higher Education and Workforce Policy: Creating More Skilled Workers (and Jobs for Them to Fill)” (Washington, DC: Brookings Institution, 2015).
Thomas Kane and Cecilia E Rouse, “Labor-Market Returns to Two- and Four-Year College,” The American Economic Review 85, no. 3 (1995): 600-614.
Mary Alice McCarthy, “Beyond the Skills Gap: Making Education Work for Students, Employers, and Communities” (Washington, DC: New America, 2014).
Jonathan Rothwell, “The Hidden STEM Economy” (Washington, DC: Brookings Institution, 2013).
Rothwell, Jonathan, “Using Earnings Data to Rank Colleges: A Value-Added Approach” (Washington, DC: Brookings Institution, 2015).
The White House, “The Economics of Early Childhood Investments” (Washington, DC: Executive Office of the President of the United States, 2014).
Pathways to Middle-Skill Allied Health Care Occupations
Better information about the skills required in health occupations and the paths to career advancement could provide opportunities for workers as well as improved health care.
Health care has been a “job engine” for the US economy, given the sector’s historically strong job growth, an aging population, and increasing demand for health care due to the Patient Protection and Affordable Care Act of 2010 (ACA). Health care professions dominate the list of the 20 fastest growing occupations, with growth rates between 25% and 50%, according to data compiled by the federal Bureau of Labor Statistics. With a good demand outlook and the relatively low entry requirements for several of these jobs, health care occupations appear to be a good career path.
Many of the growing health care professions are “middle-skill,” a term with considerable overlap with the term “allied health,” a category that encompasses a diverse and not precisely defined set of careers. The Association of Schools of Allied Health Professions has identified 66 such occupations; the Health Professions Network, a collaborative group representing the leading allied health professions, has identified over 45; and the Commission on Accreditation of Allied Health Education Programs provided accreditation in 2010 to 28 occupations. These jobs may or may not involve direct patient care, and some do not require specialized skill at entry. Many require less than a baccalaureate degree for entry. Table 1 provides a selective list of jobs in health care that do not require a four-year college degree.
The pathway to an allied health career can be unclear, especially in relatively new and emerging positions. Clear career pathways and ladders that lead to socioeconomic success need to be clarified in order to direct investments for attracting and retaining a competent workforce. Our task here, then, is to describe what is known about the career pathways into middle-skill allied health careers and the challenges that exist for individuals seeking such careers.
Career pathways and ladders in allied health, as with other health occupations, can be confusing, but making them clearer can help ensure that the nation has a pipeline of skilled workers to deliver high-quality patient care. The first need is to identify potential job areas for people just starting on their career paths. To help identify clear pathways through education into career, the National Association of State Directors of Career Technical Education Consortium developed a National Career Clusters Framework identifying 16 career clusters (including a cluster on health sciences) and 79 career pathways, which the Carl D. Perkins Career and Technical Education Act of 2006 promotes for adoption by educational institutions. The consortium also identified five health science career paths with a common career technical core, knowledge and skill statements, and a plan of study for each of the following pathways: therapeutic services, diagnostic services, health informatics, support services, and biotechnology research and development.
In addition, the National Consortium for Health Science Education developed knowledge-assessment tools and an educational tool clearinghouse for programs in over 300 health science careers. The consortium developed these tools in partnership with six state departments of education, the American Hospital Association, and Kaiser Permanente. By aligning educational tools with the needs of future employers, students will have better preparation for a health care career.
Next comes the need to help those already in the workforce to move up to higher-quality jobs. Several initiatives have been set in motion to help incumbent workers identify career ladders in health care. For instance, the Jobs to Careers Initiative provided incumbent frontline health care workers with on-the-job training as well as career and education planning tools that helped them identify possible career ladders.Another employer-led initiative dedicated to helping low-wage workers identify career ladders is the National Fund for Workforce Solutions. This group has over 20 regional collaboratives and over 30 workforce partnerships focused on the health care sector. They bring together employers, workers, communities, and funders to identify the skills needed by employers and then develop relevant training to help workers gain these skills and advance in their careers. Delivering basic and remedial education, providing strong support and leadership from the employer, and identifying sufficient funding to support training and increase wages are elements that help these programs succeed.
Programs to support a career ladder can improve job satisfaction, reduce turnover, and improve patient care, and they do not necessarily require additional education. The Extended Care Career Ladder Initiative, developed under the Massachusetts Nursing Home Quality Initiative in the early 2000s, represents an early example of an employer-led career ladder program for incumbent health care workers. The initiative brought together nursing homes, home health agencies, community colleges, and regional employment and workforce investment boards to develop career ladders for certified nursing assistants and home health aides. Although the individuals who participated in these programs did not necessarily move into a higher level occupation, the participating organizations saw positive outcomes, such as reduced turnover and vacancies, improved work environments, and improved quality of patient care.
Workers also face challenges in transitioning across occupations. Career transitions across health care occupations are generally rare because pathways are unclear. Although moving among entry-level positions that require no specialized education is relatively simple, moving among highly specialized positions, especially if credentialing is involved, is more difficult—and less likely. A dental hygienist, for example, could potentially move into dental sales but not into nursing without nursing-specific additional education and training. On the other hand, a person with specialized health information technology skills may be able to translate those skills to a non-health care environment.
The career ladder in health care may be better characterized as a career “lattice,” and the myriad education and training choices with different consequences can make career growth and professional development daunting for entrants with minimal education and training or lacking mentors and role models. As students head down one career path, they may realize it is a poor fit and feel uncertain about the next move. Also, some occupations, such as medical assistant, are so new that pathways into other roles, such as a nurse or medical technician, are not yet clear. To make career transitions easier, the US Department of Labor’s Employment and Training Administration is enhancing the Occupational Information Network, or O*NET, which classifies occupations into career clusters in which workers might easily move. O*NET contains information on hundreds of standardized and occupation-specific descriptors. The database, which is available to the public at no cost, is continually updated by surveying a broad range of workers from each occupation. Searching O*NET can help workers identify other jobs that require the same skills.
One motivation for career ladder initiatives is to improve workers’ socioeconomic opportunities. Many allied health care occupations in high demand have low educational entry requirements and are among the lowest paid. A high share of racial and ethnic minorities is in these low-income health care occupations, especially in long-term care settings. Low- and middle-skill workers in long-term care positions generally experience high turnover, high rates of disability, and high rates of poverty. These workers could benefit from opportunities to acquire additional skills and qualify for better-paying positions.
Employers can improve the socioeconomic opportunities for health care workers by supporting on-the-job educational and training opportunities that direct them to career ladders. Having an associate degree and certificates (long-term and short-term) is linked to significantly higher earnings, especially in allied health. Students attending vocational or career technical education programs delivered by community colleges have among the highest rates of returns in earnings relative to other similar educational investments. For those whose education pathways will eventually lead to a bachelor’s degree, starting in community college rather than a four-year college may mean a delay in finishing the higher level degree, but gaining a middle-skill health care occupation could provide financial assistance for meeting higher educational goals.
Supporting education and training
Community and technical colleges are particularly important players in educating the allied health workforce. Private, for-profit institutions are emerging as alternative sources for education and training, although there is some concern about whether they are as cost-effective for students as are the not-for-profit institutions. This is important to policy makers because health care job-specific training opportunities and job assistance programs are often supported through federal and state funds. Public-private partnerships, including apprenticeships, have shown success in training a health care workforce with the skills desired by employers.
In a study of 18 allied health occupations, 62% of the individuals completing a post-secondary program did so at a community college, which may make health care careers more accessible due to a shorter time commitment and lower tuition and living costs compared with four-year programs. Private, for-profit institutions are attracting a growing number of students interested in health care careers. One study by Julie Margetta Morgan and Ellen-Marie Whelan found that 78% of the health care credentials awarded at for-profit institutions were associate degree or non-degree programs for careers that are in high demand. However, many of these students, including a large number of minorities, older students, and otherwise disadvantaged students, experience poor job outcomes, such as high unemployment, lower earnings, and high debt burdens, and they receive a lower rate of return on their educational investment relative to those who received training in non-profit institutions. Education from for-profit institutions may not be perceived well by potential employers. A recent study found that for health jobs that do not require a certificate, applicants with a certificate from a for-profit institution were 57% less likely to receive a callback than applicants with a similar certificate from a public community college.
Federal and state funding programs have attempted to support training programs for students interested in health care careers, with many of the target institutions being community colleges, but the results have been mixed. For example, the American Recovery and Reinvestment Act of 2009 supported 80 community colleges through the Community College Consortia to Educate Information Technology Professionals in Health Care Program. Most of the participants who completed the programs found employment, employers expressed that the hired individuals had the desired competencies, and many of the funded community colleges are continuing their trainings beyond the original two-year grant.However, one-fourth of the community colleges did not continue their programs.
In addition, the Health Profession Opportunity Grants established under the ACA covered educational costs for recipients of support through the Temporary Assistance for Needy Families and other low-income individuals to train into health care jobs that pay well, are in high demand, or both. The most common occupation training course, however, was for “nursing assistant, aide, orderly, or patient care attendant,” which are occupations not well linked to career ladders and upward mobility.
In 2014, the Workforce Innovation and Opportunity Act (WIOA) reauthorized the Workforce Investment Act (WIA) of 1998 with a few key changes. WIA stimulated health workforce development across the states, particularly for occupations requiring short courses of education or training (on-the-job training, certificate programs, and associate degree programs). WIA provided job search assistance, assessment, and training for eligible adults, dislocated workers, and youths under a “work first” mission, and as a result, many allied health occupations were among those pursued by WIA program recipients. WIOA calls for the adoption and expansion of best practices around career pathways, industry or sector partnerships, and the use of industry-recognized certificates and credentials, which opens the opportunity for more rigorous discussions around allied health career pathways. WIOA has been implemented too recently for outcomes to have been assessed.
Employer-provided training and apprenticeships offer another route. Partnerships between employers and educational institutions can ensure that individuals get the competencies their employers need. The Hospital Employee Education and Training program in the state of Washington, a multiemployer training fund that pools resources through collectively bargained employer contributions, supports incumbent hospital workers to attain allied health education prerequisites to become, for example, a clinical lab assistant, emergency department technician, central service technician, or lab assistant/phlebotomist. The Jobs to Career Initiative, supported by the Robert Wood Johnson Foundation, the Hitachi Foundation, and the Department of Labor, brought together 34 employers and served 900 individuals to promote skill and career development in frontline health care workers by integrating curriculum, learning, and assessment into work processes and recruiting co-workers to serve as coaches, mentors, and preceptors.
Apprenticeship programs that provide on-the-job training opportunities are not common in the health care industry, but are being explored. The Department of Labor has identified 10 apprenticeship programs, most of which are allied health occupations, including home health aide, home care aide, pharmacy technician, and medical transcriptionist. Although employers expressed high satisfaction with these apprenticeships as a cost effective way to train and retain workers with desired skills and competencies, they are little-known and often face a lack of resources to ensure oversight of regulated practices.
The accreditation, credentialing, and scope-of-practice measures that help ensure quality care and protect patients from harm can discourage potential allied health workers seeking to follow a career ladder. Credentials required to practice vary by state and by occupation, making it difficult to move from one state to another or follow the career ladder to a new occupation. The cost of credentialing has especially been an issue as job opportunities are expanding across state lines with the increasing use of telehealth services. This barrier not only limits patient access to care, but also the opportunities for allied health workers to grow their skillsets and enter new communities.
Scope-of-practice laws that dictate what a trained worker can and cannot do in an occupation also vary across the country and make interstate moves difficult. Given potential overlaps in skillsets among occupations, competition for job opportunities has caused turf wars over which profession may offer which set of skills in their legal scope of practice. Scope-of-practice laws may hinder team-based environments by limiting practice flexibility that could otherwise enhance delivery of patient care. In areas with workforce shortages, scope-of-practice laws can limit the use of potentially innovative solutions involving shifting tasks from one occupation to another. Recent findings by Kuo et al. and by Spetz et al., published in Health Affairs, suggest that states with less restrictive scope-of-practice laws, specifically for nurse practitioners, result in increased access to care for patients and cost savings.
A path forward
The skills, roles, and education pathways of allied health occupations are changing as health care delivery changes. All health care workers, including middle-skill workers, will need to coordinate and manage care, use technology, work in teams, and help patients navigate the system. The extent to which these new skills and roles are incorporated into current occupations or yield new career categories is not yet clear. For workers to acquire these skills, educational programs and on-the-job trainings must be attuned to this changing health care landscape.
Monitoring the pipeline and supply of allied health professions is a challenge due to the decentralized nature of data collection for allied health professions, especially middle-skill workers, and the highly variable roles that they fill from one employment setting to another, and from state to state. Moreover, since the career pathways to middle-skill allied health occupations are not always clear, capturing data on the educational pipeline of available workers can be a challenge. To track their supply and distribution requires use of data from different sources, each with varying quality, amounts, and types of information.
The available data suggest, however, that pay is relatively low for many entry-level allied health positions and that career ladders may be difficult to identify or are lacking. With increases in reports of high levels of educational debt facing health career students, along with the prominence of for-profit institutions with low returns on employment, individuals should carefully assess their decision to invest in health care careers, especially those requiring low- and middle-level skills.
Given current conditions, then, we offer five recommendations to strengthen the case for entry into middle-skill careers in allied health:
First, research and discussion should be increased to make allied health career pathways more clear, especially for those in the lowest-skilled and potentially low-paying occupations.
Second, interprofessional dialogue should be increased throughout the educational pipeline with health care employers to make sure the right competencies are delivered in a rapidly changing health care landscape.
Third, the apprenticeship opportunities identified by the Department of Labor should be explored as potential avenues for a career path in health care, especially where access to training may be a challenge, such as in rural areas, and for veterans who may have years of experience from the field that could be quickly leveraged into a civilian job.
Fourth, awareness of career opportunities in allied health should be raised by increasing the dissemination of the health science career clusters identified by O*NET and the curricula designed by National Consortium for Health Science Education and National Association of State Directors of Career Technical Education Consortium.
Fifth, a panel of experts should be appointed and charged with regularly monitoring the pulse of the allied health middle-skill workforce, much like the National Health Care Workforce Commission created (but yet to be funded) through the ACA.
These steps comprise a general, though by no means exhaustive, set of actions that may help to improve the prospects for individuals seeking to enter allied health or trying to advance their careers in these fields. They also may help governments and employers build and retain a competent workforce. And they ultimately may lead to improved care for patients in various health settings. Much remains to be done, but the rewards are likely to be commensurate with efforts.
Bianca K. Frogner is an associate professor and health economist in the Department of Family Medicine in the University of Washington’s School of Medicine. Susan M. Skillman is deputy director of the University of Washington Center for Health Workforce Studies.
Better Jobs Information Benefits Everyone
Economic growth and full employment require well-functioning labor markets—ones that enable workers to acquire skills that are in demand and employers to hire workers with necessary skills. Accurate and detailed information is essential to the functioning of a labor market that will make this possible.
To find a decent job in today’s economy, most workers need some level of specialized knowledge and skills, but it is not easy to figure out what specializations are in demand now and are likely to be needed in the future. Choosing poorly has long-term career consequences.
Unfortunately, the information needed to make good decisions, particularly concerning middle-skills jobs, either does not exist or is difficult to find. Neither Congress nor the executive branch has adequately fulfilled its responsibility to collect, organize, and make available reliable labor market information. A coordinated and adequately funded federal program to make this information available could provide enormous benefits to middle-skills workers and to employers as well as to a variety of other constituencies including students, educators, career and guidance counselors, state and federal policy makers, and researchers, all of whom play a role in creating an efficient labor market.
The needed information includes:
Occupational descriptions, including tasks performed and knowledge, skills, abilities, and training required.
Occupational demand and supply, current and projected, at the local, state, and national levels.
Employment outcomes of individual education and training programs and particular career pathways.
Extent of the match between existing talent pool and occupational and career options.
The existing crazy quilt
There already exists an information infrastructure composed of several federal agencies, numerous state programs, and a variety of commercial and nonprofit data vendors. The federal government is the primary provider of information, and it alone has the fiscal, technical, and intellectual capacities, the legal authority, the imperative for objectivity, and the public trust to gather, analyze, and disseminate reliable, useful data that are consistent over time. The current federal information effort is extensive, but idiosyncratic and without apparent logic.
The Bureau of Labor Statistics (BLS) in the Department of Labor and the Census Bureau in the Department of Commerce have the most extensive responsibilities. BLS has primary responsibility for data on jobs and labor markets, and the Census Bureau covers data on workers. Much of BLS’s data are generated in cooperation with state agencies.
The Employment and Training Administration (ETA), the Department of Labor’s workforce development agency, provides workforce information grants to states. Each state receives a formula grant to prepare occupational employment projections, analyze and otherwise add value to data generated through the federal-state cooperative system, and prepare additional useful datasets. ETA also offers several online information tools, including detailed occupational descriptions and occupational competency models.
The Department of Education’s National Center for Education Statistics (NCES) collects and disseminates detailed information from the nation’s postsecondary institutions and gives grants to state education agencies to build longitudinal data systems that track student progress from secondary and postsecondary school into the labor market.
The Commerce Department’s Bureau of Economic Analysis (BEA) provides detailed data on jobs, proprietorships, earnings, and inter-area price differences. The National Science Foundation’s National Center for Science and Engineering Statistics (NCSES) produces annual statistical reports on the science and engineering workforce.
A growing number of for-profit and nonprofit vendors offer access to information not found in federal agencies. Database categories include job openings, personal profiles and resumes, student achievement (transcripts), formal assessments of personal knowledge and skills, informal assessments of firms, and industry-recognized certification programs.
The US Chamber of Commerce Foundation’s Talent Pipeline Management (TPM) Initiative is creating regional employer collaboratives to better manage employers’ skill needs, in part through pooling data to ascertain future talent needs for critical jobs and identify and assess the sources of current workers.
An opportunity for action
Concern about the nation’s need for talented workers and questions about the adequacy of training programs led Congress to pass the Workforce Innovation and Opportunity Act of 2014 (WIOA) to replace the Workforce Investment Act of 1998 as the primary federal effort to promote workforce development. In 2014, the White House also released Vice President Biden’s report on reforming the federal workforce development effort, Ready to Work: Job-Driven Training and American Opportunity.
WIOA and the Biden report want to enhance the workforce development system’s capacity to respond to the existence of “in-demand” occupations. To ensure data availability, WIOA requires the secretary of labor to work through BLS and ETA and with the states to create and maintain a workforce and labor market information system to “enumerate, estimate, and project employment opportunities and conditions at national, state, and local levels in a timely manner.”
WIOA says a key goal is meeting the information needs of all labor market participants—including jobseekers, students, employers, workforce investment boards, and state and local educational agencies. Mandated data topics include employment and unemployment, occupational supply and demand, occupational skill trends, job vacancies, and mass layoffs.
WIOA gives the labor secretary directions regarding the design and operation of the information system. The secretary is to prepare a two-year plan for the system; eliminate data gaps and duplication; and solicit input and cooperation from other federal agencies and a 14-member, user-dominated Workforce Information Advisory Council.
Transforming data into useful information
Neither middle-skills workers nor their employers are social scientists with the ability to explore disparate data sources to ferret out useful information. The government has devoted substantial resources to collecting data, but these data are dispersed across numerous agencies, and most data are not in a form useful to those who most need them. A relatively modest investment could significantly enhance the value of these data troves by merging them and presenting the information in a user-friendly format. They can begin by identifying what already exists and what additional work could make it more useful.
Occupational descriptions. Federal occupational information products are based on the Standard Occupational Classification (SOC) System. Last updated in 2010, the SOC contains 840 detailed occupations grouped successively into 23 major occupation groups. It is scheduled for revision in 2018 and every 10 years after that.
BLS offers three independent sources of information based, to some extent, on the SOC:
Occupational Outlook Handbook, which includes detailed information on 580 occupations;
National Compensation Survey of employers, which collects wage data by occupation and competency level; and
Occupational Requirements Survey, which collects detailed occupational information—including physical demands, environmental conditions, and vocational preparation requirements.
The ETA has two sources of its own:
Occupational Information Network (O*NET), which covers 1,110 occupations; and
Competency Model Clearinghouse, which has competency pyramids for 26 occupational groups, each constructed in cooperation with industry.
Although all of these activities generate extensive data, there are significant weaknesses that make the whole less than the sum of the parts. The lack of consistency and complementarity across the five information products is not helpful to users. Once-a-decade updates of the SOC do not keep up with a rapidly changing occupational structure, and O*NET, the largest and most detailed product, is not current because of insufficient funding. It updates only about 100 occupations annually. In addition, the government does not regularly evaluate the impact of its various occupational information tools.
Characteristics of labor markets. BLS, Census, BEA, and state governments provide a substantial amount of information on local, state, and national economic conditions that present an important context for labor market decisions. Topics include jobs, unemployment, labor force participation, and the socioeconomic characteristics of workers.
Federal data describing general regional economic conditions are good, for the most part. Model-based data products reflect initiative and innovation. However, the current employment estimates from BLS have reliability problems. Also, several members of Congress—citing privacy—regularly seek to terminate the Census Bureau’s American Community Survey (ACS), the replacement for the decennial “long form” and a source of relevant data.
The BLS Occupational Employment Statistics (OES) program annually produces employment and wage estimates for over 800 occupations at the national, state, and metropolitan levels. Due to limitations on sample size, OES estimates are based on data collected over a three-year period, so it is not as timely as its annual schedule indicates.
BLS is exploring adjustments to OES methods. Most desirable is adding an occupation field to the unemployment insurance employee wage record collected by states from employers. This would obviate the need for an OES job title to be available for each worker.
Near-term, BLS is making information technology investments to model one-year OES estimates from the existing sample. It also is testing “autocoding” employer records to SOC occupations to reduce the paperwork burden on employers. If BLS is able to significantly reduce that burden, it could expand the OES sample size with existing funds and, in combination with modeling, generate even more reliable one-year estimates.
Detailed workforce characteristics by occupation are available through the Census Bureau’s ACS and Current Population Survey (CPS). Traditionally, postsecondary educational attainment is measured in terms of degrees. Data have not been available on the attainment of nondegree credentials such as industry-recognized certifications, state occupational licenses, and community college certificates, but it is these nondegree credentials that are particularly germane to middle-skills jobs.
To address this data gap, NCES organized the Interagency Working Group on Expanded Measures of Enrollment and Attainment, which has resulted in the CPS adding a nondegree credential question and NCES conducting a detailed household Adult Training and Education Survey. The new data should help middle-skills labor market participants assess the value of nondegree credentials for employability, earnings, and career advancement.
Middle-skills labor market participants make decisions on the basis of perceptions about near-term occupational demand relative to supply. The relevant data are flow measures—which concern changes in individual worker and job status such as job openings; job hires, separations, and turnover; school-to-job movements; and worker job-to-job movements—and stock measures—which cover overall demand and supply, such as the number of jobs in an occupation (filled and open) compared with the number of qualified persons available. Wage-level changes are a corollary indicator, waxing and waning in response to shifts in demand relative to supply.
Although the United States does not have a reliable system of near-term occupational demand and supply indicators, several components of such a system are available and others could be added with proper investment.
Information on flow measures is typical of the grab bag state of labor market data. Private vendors conduct automated analysis of the text of online job openings to provide estimates of openings by occupation, industry, and geography. Although this is a creative new approach to mining real-time information, the results suffer from deficiencies in coverage, quality, compatibility, and comparability. The BLS Job Openings and Turnover Survey estimates job openings by industry, but only at the national level and not by occupation. State agencies generate short-term projections of average annual openings for detailed occupations.
For information on hiring, separation, and turnover, one can glean some information from LinkedIn’s database on occupational status, entry, and exit. The Census Bureau’s Longitudinal Employer-Household Dynamics program links establishment and employee records from each state’s unemployment insurance system. The BLS Employment Projections Program estimates average annual replacement rates by occupation. The US Chamber of Commerce Foundation’s TPM Initiative has created an occupational demand planning tool kit for use by its regional employer collaboratives.
Information on school-to-career transition is available from the NCES Integrated Postsecondary Data System (IPEDS), which reports the number of students and degree and certificate recipients by field of study by year. But it includes only full-time students at one point in time, not the flow of all students through each institution. With assistance from NCES, nearly every state is building a longitudinal data system that tracks students from prekindergarten into K-12, postsecondary training, and the workforce. However, most systems cannot track former students who move out of state. The National Student Clearinghouse Research Center provides access to enrollment and completion data from more than 3,600 postsecondary institutions, enrolling 98% of all students. The Association for Career and Technical Education has created a new Certification Data Exchange Project (CDEP) “to expand and improve data exchange between industry certification organizations and state longitudinal data systems … that will allow states and educational institutions to gain access to data on industry-recognized certifications earned by students.” The multi-partner Credential Transparency Initiative is launching an open, voluntary nationwide credential registry that will provide access to detailed, standardized information on individual degree and nondegree credential programs. TPM regional collaboratives are conducting talent flow analyses to identify educational institutions that provide qualified and valued employees.
Resources for stock analysis are similarly diffuse. The ACS provides estimates of employment for 526 detailed occupations by industry. OES estimates three-year average employment and wages by occupation for the nation, states, and metropolitan areas. National estimates are by industry. Development of an annual OES time series would identify shifts in the demand-supply equilibrium by occupation. The Occupational Outlook Handbook includes a series of national occupational tables by industry. Coverage includes the self-employed. State agencies generate short-term employment projections for detailed occupations. Census publishes Nonemployer Statistics, annual estimates of proprietors without employees, by industry and geography. At present, there is no reliable set of estimates of the supply of persons qualified to work in various occupations. Moreover, the development of reliable occupational demand-supply models is in its infancy.
The Chamber Foundation’s TPM Initiative provides its regional employer collaboratives with a guide to talent flow analysis—identifying and evaluating the sources of current employees in key occupations, with sources including education and training programs and prior employers. BLS and the state agencies produce 10-year employment projections by occupation, emphasizing that the projections are not forecasts. BLS says its prior efforts correctly projected the direction of change for two-thirds of occupations, more accurately projected employment for large-sized occupations than small-sized ones, and was fairly accurate in projecting the distribution of employment among occupations. BLS and the states regularly make improvements in their methodologies and recently created a working group to coordinate their efforts, but there is no easy answer. The group will have to develop a slow, steady program to test various approaches.
The apparent disorder and lack of coordination in federal programs stems from inertia, inadequate market assessment, and lack of leadership.
Career pathways. Labor market participants want to understand and compare the trajectories that one can follow from training through steps up the career ladder. Two IT advances are allowing researchers to understand the nature and results of various career pathway patterns by occupation. Census is building a Job-to-Job Flows Tool that enables researchers to trace worker trajectories across jobs and changes in labor force status, with information regarding industry, earnings, and location. In addition, academic researchers are analyzing large volumes of personal career histories available on LinkedIn and in resume banks, but this type of research is in its infancy.
The NCES Statewide Longitudinal Data System (SLDS) Program allows labor market participants to see the employment outcomes of individual educational institutions and programs. However, three issues impede this effort—difficulty obtaining employment information when someone moves out of state, the absence of an occupation field on the wage record, and insufficient data on nondegree credentials.
Each of these issues is being addressed. Data on employment of out-migrating workers are being sought through Census, ETA, Department of Health and Human Services, and NSRC resources. BLS is examining the desirability and feasibility of adding an occupation field to the unemployment insurance wage record. The CDEP aims to develop a nationwide system providing access to data on industry-recognized certifications that can be added to SLDS.
Tools for individuals. Advances in information technology offer the possibility of providing customized guidance to students, workers, educators, and employers regarding the extent of fit between an individual’s knowledge, skills, and abilities (KSAs) and those required for a particular occupation or job. Nearly one-quarter of job applicants now take a skills test, often administered by a predictive analytics firm. On the basis of the test results, the firm then provides guidance to the employer regarding the applicant’s likely fitness for the job. With access to test results, researchers could analyze the large volumes of data to create career guides and design more useful career testing.
Optimizing the government investment
The annual federal spending of $800 million on labor market information might sound significant, but it amounts to less than $2.50 per capita. Compare this with the $450 billion that US employers spent on training in 2013 or the $17 billion that the federal government spent in FY2014 on employment and training programs. Average training expenditure per worker is $3,300. Timely, reliable, and detailed data and analysis could help ensure that this investment is spent wisely. Better coordination and a little more funding could make this possible.
The federal labor market data effort is not fulfilling its potential and the problem begins with lack of resources. Congress needs to recognize the enormous leverage that this effort could produce through guiding private and government training and education programs. The funding shortfall is repeated for state programs. Annual funding for BLS grants to state agencies has been stuck at about $72 million for many years, and ETA state workforce information grant funding has been flat at $32 million. Too little money to begin with, and utility of these grants is eroding with inflation.
The apparent disorder and lack of coordination in federal programs stems from inertia, inadequate market assessment, and lack of leadership. Agencies often are bound by legacy methods for collecting and producing data, particularly surveys. They have paid too little attention to understanding the nature and needs of their customers, on the one hand, and measuring—and adequately explaining to Congress—the value of their programs to well-functioning labor markets, on the other. Since 2001, no secretary of labor has taken seriously the charge to create a nationwide workforce data system through interagency collaboration, and Congress has not provided oversight on this mandate’s implementation.
WIOA’s detailed, thoughtful specifications for improving data collection provide the legal and organizational basis for addressing these problems. Administration officials can take a number of steps. The secretary of labor can develop and regularly update a two-year labor market information plan with a clear vision, roadmap, and rationale, and then direct BLS and ETA to:
coordinate and collaborate on data-related activities;
better understand data uses, issues, and opportunities;
measure the performance and impact of their products and services;
work with other statistical agency heads, including Census, NCES, and the National Science Foundation, to reduce data duplication and address gaps; and
brief congressional staff on the value of labor market information to diverse stakeholders.
The White House policy offices should work together to support a coherent strategy and make the case for adequate congressional appropriations. The Federal Committee on Statistical Methodology should create a study group to develop principles and practices for use of advanced IT data methods and third-party services.
Under the authority and directive provided by WIOA, the secretary of labor—through BLS, ETA, Census, NCES, the Office of Management and Budget, other federal agencies, and employer associations—should facilitate implementation of the following program priorities:
Occupational descriptions
Create a strategy for regularly updating details in occupational descriptions, including emerging and receding occupations, changes in KSAs, and changes in educational requirements.
Align and integrate the government’s suite of occupational information tools in a way that meets labor market participant needs.
Encourage employers to adopt a standard template for on-line job postings that would allow for more productive text analysis for the purposes of understanding occupational KSAs and educational requirements.
Characteristics of labor markets
Improve occupational statistics through modeling the annual OES time series, autocoding OES responses to reduce costs and expand the sample size, and adding occupations to the unemployment insurance wage record.
Actively support a mandatory-response ACS.
Continue efforts to collect nondegree credential attainment data.
Develop useful occupational supply-demand models at all levels of geography.
Continue to improve short-term and long-term national and state occupational projections.
Expand IPEDS to include nontraditional students.
Monitor and support regional employer collaborative efforts to trace supply and demand trends.
Support the Credential Transparency Initiative.
Employment outcomes and career pathways
Pursue technically and legally viable methods to track the employment outcomes of out-of-state movers.
Support the Certification Data Exchange Project.
Monitor and support regional employer collaborative efforts to trace education-employment trajectories.
Enhance researcher capacity to analyze job-to-job and career trajectories.
Convene a national conference to explore the potential of analyzing the results of personal assessment tests to inform workforce development processes.
The development of a robust, fully employed middle-skills workforce requires that students, workers, employers, educators and trainers, and policy makers be able to make labor market decisions on the basis of current, reliable, detailed information.
At present, such information is not readily available to a sufficient degree. However, significant advances in information technology and widespread interest by government agencies, advocates, researchers, and vendors suggest that the way and the will exist to address this situation. Remarkable opportunities are available to enhance the workings of US labor markets through modest investments to improve workforce data resources.
Not ’Til the Fat Lady Sings: TSCA’s Next Act
The newly enacted revision to the failed chemical safety law marks a rare recent example of bipartisanship, but whether it will lead to improved environmental protection remains to be seen.
When President Obama signed the new chemical safety legislation into law on June 22, 2016, he formally ended decades of stalemate and conflict over whether and how to fix a broken system. He was also inaugurating an era—perhaps equally long—of sparring over how to ensure that the new statute actually does improve the regulation of chemicals.
The bill the president enacted, the Frank R. Lautenberg Chemical Safety for the 21st Century Act, was the product of three years of tortuous, and often tortured, negotiations. Even its name was controversial. Advocates for and against the bill disagreed over whether the measure was a fitting legacy for Senator Lautenberg, who had long fought for greater environmental protection. (The senator’s widow was a dogged advocate for the bill, mostly behind the scenes.)
It was Sen. Lautenberg who, in 2013, jump-started the talks that led to the new law, which amends the 1976 Toxic Substances Control Act (TSCA). TSCA had been widely viewed as a broken statute for many years—the one foundational environmental law from the 1970s that had not worked. The Environmental Protection Agency (EPA) had reviewed just a few of the 80,000 or so chemicals that were already in use when TSCA was passed and had regulated only about a half dozen.
EPA’s glacially slow review of chemicals that were on the market before 1976—and even today that’s most chemicals—came to a virtually complete halt in 1991 when a federal appellate court overturned EPA’s proposed ban on asbestos, a well-known carcinogen. That ruling, never appealed by EPA, left much of TSCA a dead letter because the court interpreted the law in a way that made it just about impossible to ever successfully defend a chemical regulation when the agency was (inevitably) sued.
Efforts to revise TSCA had run aground because of profound differences between the chemical industry and environmental and health groups, but by 2013, elements of the chemical industry were feeling pressure to get some kind of federal system in place. States and large retailers were taking action to limit the sale of particular chemicals, and citizen groups and the media were drawing more attention to the dangers of commonly used toxic chemicals, such as flame retardants in furniture. The industry had no official national arbiter it could point to when challenged, the way the pharmaceutical industry, say, could use the Food and Drug Administration. A hamstrung EPA no longer looked like an unalloyed good to companies with products under attack, especially if the industry could shape whatever new regulatory system was put in place.
Unicorn sausage
That was the context when discussions began between Sen. Lautenberg and an unlikely interlocutor, Sen. David Vitter (R-LA), a hard-edged conservative and defender of the chemical industry, especially the petroleum companies in his home state. The history of those discussions remains to be written, and much about them continues to be unclear, including exactly how they were initiated and who knew what about their content when. But they resulted in a draft bill that was publicly released in the spring of 2013, a few weeks before Sen. Lautenberg passed away.
That draft became the template for altering TSCA, and set the parameters for the three years of negotiation that led to the new law that President Obama signed. The Lautenberg-Vitter bill’s fatal flaws are the origin of many of the fundamental problems with the new law. To begin with, the original bill was demonstrably weaker than the 1976 TSCA law—no mean feat. It would have enabled EPA to make unchallengeable determinations that chemicals were safe with virtually no scientific review while taking away much of the authority states have to regulate chemicals. An industry-oriented EPA (as was the case, for example, in the early years of the Reagan presidency) could have used the law to declare chemicals safe with impunity. And the bill failed to correct some of the most basic failings in TSCA, such as the lack of any enforceable deadlines to get EPA to act.
But the Lautenberg-Vitter bill did raise the possibility (and the specter) that a bipartisan agreement on TSCA was feasible, and it made progress on a few key issues. Most notably, it attempted to prevent EPA from taking cost into account in making safety determinations—albeit as part of an overall bill that would have been a step backward. And in today’s polarized Congress, any bipartisan effort is noteworthy enough to have some momentum; many in the press and in Congress assume anything bipartisan must be a thoughtful compromise no matter what its actual content. A bipartisan bill these days is seen as a kind of miracle; if you criticize a bipartisan bill, you’re treated as if you killed the last unicorn.
So the Lautenberg-Vitter bill did end up being the start of serious talks on TSCA, despite its severe tilt toward industry’s interests. Sen. Tom Udall (D-NM) took over the Lautenberg role as the lead Democrat after Sen. Lautenberg’s death. The primary bloc of environmental and health groups, the Safer Chemicals, Healthy Families Coalition, panned the bill, but expressed willingness to enter into talks. One environmental group, the Environmental Defense Fund, expressed support for the measure. And EPA, which had earlier released general principles it said should guide a TSCA rewrite, made clear privately that it was eager to have work on TSCA continue.
The serpentine path from that moment to the White House signing ceremony should truly be the subject of a book. It would offer not only a case study of legislating on a complex issue in a deeply divided Congress, but also enough personality conflict, high emotion, melodrama, and cliff-hanger moments to live up to TSCA’s operatic acronym. But the process was prologue; the law will likely govern how chemicals are regulated for many years to come. So where did things end up?
It’s a mixed bag, and the actual results will, even more than with most statutes, depend largely on agency implementation decisions and future court rulings. The law leaves a lot of critical decisions to EPA, sometimes in cloudy or unprecedented language.
The bill calls for making decisions based on the “weight of the evidence”—a term that a National Academy of Sciences report has said is so ambiguous it should be avoided.
A new hope
In some important ways, the new law sets the stage for real advances. It sets an enforceable schedule—albeit not a particularly aggressive one—for EPA to review existing chemicals. (The schedule is complicated, but EPA has to have 30 risk assessments under way within three and a half years of enactment.) The law requires that EPA determine whether chemicals are safe solely on the basis of health impacts without taking cost into account. It makes it easier and faster for EPA to require industry to submit more test data about chemicals that are in the marketplace. It requires that EPA consider the risks to vulnerable populations—those facing greater exposure or with greater susceptibility, such as children and pregnant women—when determining the risk a chemical may pose. These provisions make the amended TSCA more similar to effective environmental statutes such as the Clean Air Act.
The law imposes (limited) fees on the chemical industry to help pay for the new work EPA will have to undertake, and it makes it harder for industry to withhold information from the public by misusing the “Confidential Business Information” designation.
The law also fixes provisions in TSCA that led to the court decision blocking asbestos regulation. The original TSCA required EPA to impose the “least burdensome” regulation to achieve its goal—a seemingly sensible requirement that, in practice, meant that EPA had to cost out and formally consider any conceivable approach to risk abatement and perhaps some inconceivable ones for a regulation to be upheld—an impossible task. The new law says that EPA need only review a finite number of alternatives of its own choosing; one can suffice. EPA can (but is not required to) choose among the options on the basis of cost, but the regulation has to eliminate the risk the agency has determined the chemical poses.
And the new law ameliorates some of the worst features of the Lautenberg-Vitter proposal. For example, that bill would have enabled EPA to declare a chemical a “low priority”—basically, giving it a clean bill of health—with virtually no scientific review. The designation could not have been challenged and would have pre-empted any future state action on the chemical. The new law, unfortunately, retains the low-priority category, but it provides some limits on when EPA can use the designation (it cannot, for example, assume that a lack of information means the chemical presents a low risk), allows low-priority designations to be challenged in court, and eliminates the pre-emptive effect.
Whether these provisions will turn out to be actual advances that increase public protection remains to be determined. For example, the legal formula the law uses to describe unacceptable risk and to keep cost considerations out of safety determinations, which originated in the Lautenberg-Vitter measure, has never been used this way before, and its precise meaning will first be determined by EPA and then likely challenged in court. The chemical industry was adamant that the law use the “unreasonable risk” language that has previously been associated with cost considerations rather than formulations that have been tried in other statutes. EPA will also need to decide which vulnerable populations to consider when reviewing a chemical and how to determine their level of risk.
The agency will have to determine when to label a chemical low-priority, and its decisions may be challenged in court. Current EPA officials have said they view the low-priority label as applying only to chemicals that are virtually free of risk, but it remains to be seen whether they will act accordingly, given industry pressure. And in any event, a future EPA could still try to apply the category more broadly.
Courts may also be asked to rule on the language that replaced the “least burdensome” requirement, which inartfully combines wording from several different versions of the bill. A case could arise if, for example, industry challenges a regulation by claiming that EPA should have selected a cheaper alternative, especially one reviewed by the agency.
EPA will also have to determine and describe what scientific methods it will use to evaluate chemicals and how it will evaluate the results. Most of the language in Lautenberg-Vitter that sought to dictate scientific procedures has been removed, but the bill still calls for making decisions based on the “weight of the evidence”—a term that a National Academy of Sciences report has said is so ambiguous it should be avoided.
This list only begins to hint at the number of questions that will arise during implementation—some arcane, yet all consequential—and many are complicated by drafting defects that originated in Lautenberg-Vitter, even though the final law cleans up most of the (sometimes purposeful) ambiguities presented by almost every line of that initial proposal.
Now for the bad news
And these are only some of the matters raised by the positive aspects of the new law. Then, there are its significant shortcomings. Most notable is the extent to which the new law pre-empts state authority—the most volatile issue during the negotiations over the bill and the last to be settled. Industry was seeking broad pre-emption from state regulation as the quid pro quo for a functional federal regulatory system, and although negotiations narrowed pre-emption, state action will now be much more circumscribed than it was under the 1976 TSCA. For example, under the original TSCA, states retained the capacity to ban chemicals even after the federal government acted, and states were never pre-empted by EPA finding a chemical to be safe. The newly amended law blocks most state actions (including bans) on a chemical once EPA has either declared it safe or imposed federal regulations.
Most troubling is that the law takes the apparently unprecedented step of blocking state actions before the federal government has decided whether to regulate a chemical. Pre-emption is triggered simply by EPA deciding to review a chemical, a multiyear process. The period of that pre-emption was reduced in the final bill from prior versions—it now covers only some of the period when EPA is examining a chemical and it can’t be extended if EPA delays a decision—but there is no legitimate rationale in principle or practice to prevent states from protecting their citizens when the federal government has not made a decision. Indeed, the law is perverse—a federal statement that a chemical should be reviewed because it could present a serious risk is what blocks a state from taking action.
The pre-emption provisions are complex, and disputes may arise over exactly which actions states are still allowed to take and when.
The new law also allows industry to determine up to half the list of existing chemicals for EPA to review, if it pays for those reviews. Formally allowing a regulated entity to hijack the priority-setting of a federal agency is a dangerous precedent that offers no public benefit. This was simply a political bargain that originated in an even more damaging form in a House bill.
The new law also weakens EPA’s ability to acquire information on the use of chemicals in imported products—disturbing when imported products such as toys from China and elsewhere have caused so much concern. Much of the language on imports is murkily crafted, but its source was quite clear. It came from a business coalition dominated by aircraft and automotive manufacturers, which had concerns about having to keep track of chemicals in numerous component parts their products use. But the bill does not target that problem or even those industries. Instead, it creates barriers to regulating imported goods generally. Those industries also were granted an exemption from regulation for any replacement part “designed” before an applicable standard is imposed—a giant loophole—when earlier versions of the bill exempted only those parts that had already been manufactured, allowing current inventories to be drawn down (even though the product presented a danger).
Uncertainty ahead
Ben Franklin famously said after the Constitutional Convention that Americans now had a republic “if you can keep it.” With far greater skepticism and uncertainty, it can be said that Americans now have a functional chemical safety law, if EPA can properly implement it. “Properly” will, of course, be in the eye of the beholder and vehemently disputed as EPA makes its decisions and courts decide if they pass muster. For now, the extent of public protection still hangs in the balance. The TSCA law is an opera that is about to spawn many sequels.
David Goldston is director of government affairs at the Natural Resources Defense Council in Washington, DC.
A Second Act for Risk-Based Chemicals Regulation
The Toxic Substances Control Act amendments put risk assessment at center stage. How will it perform?
At a time when partisan squabbles and election-year politics dominate the headlines, Congress did something remarkable in June 2016: it passed the most significant piece of environmental legislation in a quarter century. The Frank R. Lautenberg Chemical Safety for the 21st Century Act amends and comprehensively overhauls the Toxic Substances Control Act (TSCA), a 40-year-old statute with a disapproval rating potentially higher than that of Congress itself.
Unlike the Clean Air Act or Clean Water Act, which focus on preventing or remedying pollution, the focus of TSCA was upstream. The intent of the legislation was for the US Environmental Protection Agency (EPA) to look at the universe of chemicals in commerce and regulate those chemicals that posed an “unreasonable risk” to human health or the environment. TSCA may also have represented the high-water mark in congressional optimism (or hubris): it turned out there were significant quantities of about 60,000 chemicals in commerce when TSCA was enacted. Over 20,000 more have been added since.
TSCA proved to be a disappointment. In large part this was due to EPA’s grossly inadequate level of productivity. The agency required very few chemicals to be tested and restricted even fewer—none in the past 25 years. (Compare this with the several hundred active ingredients in pesticides that EPA has successfully reviewed since the early 1970s under the Federal Insecticide, Fungicide, and Rodenticide Act.) The US Government Accountability Office lists TSCA among federal programs that are high risk due to their vulnerabilities to fraud, waste, abuse, and mismanagement, or are most in need of transformation.
Frustrated with the lack of federal action, environmental and public health activists turned their energies to state legislatures and agencies, which began banning or restricting chemicals and even establishing their own chemical review processes, as California did after the passage of voter Proposition 65 in 1986. Consumers, meanwhile, began pressuring major retailers and consumer products companies to “deselect” certain chemicals.
These developments were welcomed neither by chemical manufacturers nor firms that use chemicals in industrial processes. Instead of dealing with one national program to control chemicals, they now had to deal with a patchwork of state laws and growing pressures from consumers, all overlaid on the federal program.
Congress ultimately responded by giving each group of stakeholders something: The newly amended TSCA (which we’ll call “amended TSCA” through the rest of this article) addresses environmentalist concerns by granting EPA increased powers (and fewer hurdles) to identify and regulate chemicals in commerce, as well as industry concerns by granting the federal government greater power to preempt state action. Under amended TSCA, once EPA makes a final decision over a chemical, states are limited in their ability to control it. And while EPA evaluates a chemical, states generally must refrain from taking action.
TSCA’s original failings were of two types: those arising from its legal framework and those arising from the science policy issues inherent in risk assessment and the so-called risk paradigm. Although the new amendments largely fix the antiquated legal framework, problems with the risk paradigm are more challenging and the solutions less amenable to legislative action. How EPA addresses these latter problems during the implementation phase will determine the success of the new law.
TSCA’s former legal problems
When it was enacted in 1976, TSCA channeled EPA’s attention toward chemicals that had not yet been introduced into commerce. EPA was required to review, within 90 days, every such new chemical before it was manufactured to determine if it might pose an “unreasonable risk.” EPA had the power, albeit limited, to seek relevant information from the manufacturer. Over time, the new chemicals program was broadly seen as having worked as intended, ensuring safety while not hindering innovation, a key consideration of TSCA. Amended TSCA effectively eliminates any limits on EPA’s power to seek additional information about new chemicals from manufacturers and requires EPA to make affirmative findings of what the bill terms “unreasonable risk” (a term left undefined in the legislation that EPA will effectively have to redefine through its choices under the amended statute).
By contrast, TSCA did not mandate EPA to evaluate chemicals already in commerce. Other statutes required the agency to direct resources toward things such as setting land disposal standards for hazardous waste. It was much harder for EPA to justify throwing indefinite amounts of resources at a subset of chemicals that the agency had to choose, essentially by judgment call.
But even if EPA chose to regulate such chemicals, it could do so only with great difficulty. The agency’s information-gathering powers were subject to a catch-22: EPA needed information to compel testing of a chemical, but testing was required to obtain the necessary information. Even when the agency had enough data to make a finding of unreasonable risk, the statute demanded a “least burdensome” approach to regulation. A 1991 court decision interpreted this to mean calculating and comparing the costs and benefits of “each regulatory option,” and struck down much of EPA’s ban on asbestos-containing products for not doing so adequately. For all these reasons, the existing chemicals program has barely worked at all, and has created a regulatory bias toward continued use of existing chemicals over the creation of new, typically “greener” chemicals. Amended TSCA requires EPA to prioritize and evaluate all existing chemicals currently in commerce and sets deadlines for action. It also empowers EPA to order testing whenever necessary for an evaluation. And it eliminates the “least burdensome” standard, requiring EPA, when setting restrictions, merely to “factor in, to the extent practicable,” considerations such as economic consequences and alternative approaches.
Finally, the “unreasonable risk” standard under prior TSCA required EPA to weigh considerations related to the environment and health against a variety of economic and social factors. The seminal text in risk assessment, the National Academy of Sciences’s (NAS) 1983 “Red Book,” declared that the process of assessing risks should remain separate—though informed by—the process of managing them. TSCA, which predated the Red Book by seven years, thus violated this recommendation by conflating the science-based risk assessment step and the policy-laden risk management step. The daunting challenge of trying to solve both problems at once was another reason EPA was so reluctant to act against existing chemicals. Amended TSCA slices through that Gordian knot by requiring EPA to assess risk without consideration of non-risk factors, with the latter relegated to being a consideration in choosing restrictions.
Chronic problems with chemical regulation
With TSCA’s major legal flaws eliminated, EPA will be forced to confront, prominently, a range of problems that have bedeviled risk assessment for years, albeit in other regulatory contexts. These problems, which can involve dozens of science policy decisions, are compounded by the sheer number of chemicals (and chemical uses) in commerce. EPA’s efforts will also highlight the questionable public health significance of regulating relatively small risks. Each of these issues is worth examining more closely.
For starters, epidemiology is rarely a helpful tool for chemical risk assessment. Even occupational studies, where exposures can be high and prolonged, are plagued by confounding factors such as smoking history, diet, and the tendency of healthy workers to work for more years than sick ones. In population-wide studies, exposures are far lower, harder to estimate, and even more subject to confounding factors. Researchers are forced to make adjustments that critics can challenge as manipulation. Distinguishing the “signal” from the “noise” is thus almost always debatable. Indisputable epidemiological evidence probably means you have a public health disaster.
Regulators have thus relied principally on animal studies to identify the hazards of chemicals and assess their degree of toxicity. But regulatory toxicology is hobbled by its own set of challenges. First, agencies, such as EPA, need to extrapolate from the high doses required to produce effects in small numbers of animals to the lower doses observed in the environment. These “maximum tolerated doses” (the highest amount that doesn’t kill the animals outright) often can cause cancer by processes that would not be produced by ambient exposures (e.g., tissue damage, triggering cell proliferation, which magnifies the chances of mutations). Second, regulators need to extrapolate the findings from animals to people. People may be more sensitive than animals—or they may be less sensitive. The underlying mechanical course of disease may involve metabolic processes that do not even occur in humans. Human relevance is thus a constant subject of dispute. People also vary among themselves in their susceptibilities to various effects—particularly as children or if already challenged by another disease or debility.
Fortunately, animal studies are gradually being displaced by new laboratory techniques for evaluating the toxicity of chemicals using cellular materials (ideally, from humans). For example, toxicogenomics enables experimenters to assess the tendency of a chemical to produce changes in gene expression. Related “-omics” techniques evaluate the effects of chemicals on the structure and function of proteins, on the creation of metabolites, and on the formation of RNA transcripts. High-throughput screening, a technique developed by pharmaceutical companies for testing potential new drugs, involves the use of “gene chips” or “microarrays” containing DNA sequences that can be exposed to a great number of chemicals on a rapid basis. These techniques offer the potential not just to evaluate the toxicity of chemicals in the abstract, but to interpret information gathered from the biomonitoring of populations. The power of all of these techniques is enhanced by the ability of computers and other information technology to find patterns in vast quantities of biological information and to model biological processes.
Yet these new technologies are far from battle-tested. Reliably tying an effect at the cellular or subcellular level to the production of disease in individuals remains problematic. Hot debates can emerge over whether a particular change is adverse—the beginning of a progression toward illness—or just an adaptive effect that is reversible and of no lasting ill effect. Also, the relationships between particular chemical agents, the “toxicity pathways” associated with those chemicals, and specific illnesses (or normal processes, for that matter) are typically highly complex and difficult to elucidate. These issues become especially pressing in the case of chemicals with well-established uses: although it makes sense for a drug company to reject one of thousands of molecules as a potential pharmaceutical based on a possibly-toxic effect detected in the lab, such a result seems insufficient for EPA to justify a ban on a chemical that is already produced in large volumes and used in a wide variety of products and processes.
The old and new approaches to assessing chemical toxicity thus share the problems of uncertainty and contestability. Although the uncertainties may be reducible in the future, agencies are required to make policy-based assumptions in the meantime, typically conservative ones. For example, the Occupational Safety and Health Administration clings to a policy that one study finding that a chemical causes cancer in an animal requires it to be labeled a carcinogen, even in the face of a contradictory finding from more sophisticated mechanistic analyses. Practices such as this make agencies lagging indicators of scientific progress. And risk evaluations, like most other scientific issues, can be manipulated by advocates (and agencies) to present a “fractal” problem, where more studies can be characterized as generating more questions.
Comparisons of risk-reduction efforts across federal agencies show that chemical control regulations are not cost-effective relative to other types of interventions.
Making progress on the foregoing challenges has historically been hampered by the unwillingness of agencies, such as EPA, to follow rigorous analytical frameworks and to “show their work.” In perhaps the most relevant example, EPA issued a TSCA “Work Plan” in 2012 describing how it planned to revive its long-dormant program for regulating existing chemicals. The Work Plan outlined a complex decision logic for winnowing down over 1,200 chemicals to a list of 83 on which EPA would focus. But EPA’s explanation of how it chose the first seven of those chemicals was inscrutable: EPA said it “consider[ed] a number of factors.” As a result, not all of the chemicals with the highest potential risk scores on EPA’s screening approach were among that group. These sorts of “black box” approaches obviously raise the possibility that political considerations affected the final results of what was supposed to be an objective exercise. They also prevent others from replicating the agency’s analysis, which is unfair to outside stakeholders and opens the agency to criticism.
A handful of other issues also pose a threat to EPA’s ability to successfully execute a risk-based TSCA program that can achieve the level of productivity required by Congress (and public expectations) and that will not be debilitated by lawsuits alleging arbitrary and capricious action.
The first is the sheer number of chemicals in commerce—about 80,000—each one of which may have multiple uses, with each use potentially presenting a unique risk subject to analysis.
Second, many of the chemicals that EPA is likely to include on its statutorily mandated list of “high priority” chemicals are those that have been targeted by activist groups and the media (such as brominated flame retardants). Any decision EPA makes involving them will be controversial: activists want nothing short of a ban; manufacturers still believe they are safe. And although controversial chemicals are usually the most-studied, and hence the most data-rich, no amount of data can satisfy the most determined opponents of chemicals. This is especially true of industry-generated data—and most of the data EPA will be evaluating has to be produced by industry. The legacy of industry misinformation campaigns, especially around tobacco, has cast a permanent shadow over all industry-supported science in many people’s minds.
Third, outside of its pesticide-regulatory program, EPA is not used to making the kinds of tradeoffs between risks that are the norm at agencies such as the Food and Drug Administration (which has to balance the reduction in illness or death that a new drug might produce against its potential to create other such risks). Nor does EPA typically consider the availability of substitutes and whether they are more or less beneficial than the regulated chemical—a problem exacerbated by the reality that there are typically less data on the health and environmental effects of substitutes.
A final challenge relates to the public health significance of regulating relatively small risks. Comparisons of risk-reduction efforts across federal agencies show that chemical control regulations are not cost-effective relative to other types of interventions. For example, a 1995 study by Tengs and others showed that regulations aimed at injury reduction were more than 100 times more cost-effective than chemical regulations. Other more recent studies are consistent with this finding. The principal reason is that the threshold that EPA has conventionally established to determine unacceptable risk is relatively low. For example, other EPA programs typically target cancer risks as low as one case of cancer beyond the amount ordinarily expected among a million persons exposed over a lifetime. It is extremely difficult for regulators to control such small risks cost-effectively. And, as just noted, a regulation that results in a substitution of one chemical for another could increase net risk if the regulator is not careful.
These challenges with applying the risk paradigm have inspired a movement toward alternative policy approaches. Most prominently at the federal level, Congress in 1990 abandoned risk as the basis for the Clean Air Act’s hazardous air pollution program, instead requiring maximum achievable control technology for major sources of such pollutants. In recent years, states increasingly have enacted similar hazard-based policies (e.g., toxics use reduction, alternatives assessment) in which formal risk analysis (and its emphasis on exposure) is foregone.
Critics of the risk paradigm decry its technical complexity and slow pace and they rightly point to the speed with which hazard-based approaches can be implemented. But the fundamental drawback of hazard-based policies is the absence of knowledge about baseline risk or the resulting change in risk that comes from reducing hazards without consideration of exposure—a serious deficiency indeed. Without an ability to measure risk reduction, it is impossible to compare the efficacy of two different approaches with reducing risks. One is simply guessing, or worse, just devoting resources to hazards in proportion to the degree they are feared or disliked by the public or to the degree of imbalance in political power between the proponents of regulation and its opponents. And since hazard-based policies can’t be compared for efficacy, they cannot be compared for cost-effectiveness.
Finally, hazard-based policies can’t be evaluated via cost-benefit analysis (CBA). The shortcomings of CBA are widely known. Most jarring is the requirement that “invaluable” things such as life or health be assigned some monetary value. Other inherent limitations include the prospect that benefits and costs will be assessed from the perspective of those doing the valuation, who may discount or outright omit consequences that matter to others. Although these challenges are indisputable, in our view they can be mitigated; for example, objectivity can be increased through the development of best practices and the application of external peer review. Every regulatory program involves the expenditure of resources for the production of benefits. CBA simply makes explicit what otherwise happens implicitly. And in a regulatory system fundamentally grounded on the notion of rationality—as the US system is—it is incumbent on us to seek to understand how much we are devoting to risk reduction and how much it is accomplishing. CBA is the standard tool for doing so.
Needed solutions
Applying the risk paradigm to thousands of chemicals in commerce was a much more daunting task in 1976 than it is today. Indeed, it may be that Congress chose to focus EPA on the relatively small universe of new chemicals as a logical reaction to the nascent discipline of risk assessment. Since TSCA was enacted, however, the practice of risk analysis has evolved, and the science supporting that practice has grown dramatically. Although that science will remain uncertain to some degree, we believe that such uncertainty has been reduced overall. And tools for characterizing risk have also advanced, so that identification and characterization of major uncertainties is a well-accepted principle. Thus, challenges that once seemed Herculean are more tractable today.
A successful approach to risk-based chemical regulation—one that addresses the major challenges discussed previously—starts with a risk-based prioritization exercise across the universe of existing chemicals to separate the bigger potential threats to public health from the smaller threats. Many different sources of information, including high-throughput screening, will be used to determine whether a substance is a priority for an in-depth risk evaluation. By screening substances based on relative hazard and exposure, EPA can greatly narrow the universe of substances to those that should be subject to closer scrutiny.
After identifying the highest priority substances, the risk assessment process should follow recommendations made in a series of canonical publications by the NAS and other blue-ribbon advisory bodies (such as the Presidential Commission on Risk Assessment and Risk Management established under the 1990 Clean Air Act Amendments) over the past few decades. These important recommendations include:
• Bringing risk managers into the assessment process early to help with problem formulation to ensure that risk assessment resources are directed toward known decision points;
• Consistently and rigorously following transparent and replicable frameworks for literature review;
• Drawing scientific conclusions across multiple studies based on the weight of evidence; and
• Advancing mechanistic research, toxicogenomics, and other new and emerging toxicological techniques.
During prioritization and the subsequent in-depth risk assessment, the agency should not ignore substances lacking basic information on hazard and exposure. In other words, “data-rich” chemicals should not be penalized relative to “data-poor” chemicals. Some chemical substances, such as bisphenol A, have been the subject of hundreds of studies, whereas others have been subject of very few. To generate new data, which can be an expensive undertaking, the agency should employ a value-of-information approach to assess whether additional data generation is likely to be worthwhile given limited resources, including laboratory capacity. For example, a substance that comes up positive on a low-cost screening test can then be subject to a more specific (and more expensive) test to minimize the possibility of a false positive.
After identifying substances that pose an unacceptable risk based on a health-based standard, the agency should identify a manageable number of regulatory alternatives (including the alternative of not regulating at all) based on economic principles. For example, the presence of a market failure, such as an information asymmetry, might best be addressed through a mandate to provide information to consumers. When comparing among the alternative regulatory options, EPA should consider both costs and benefits. Particular attention should be paid to potential countervailing risks consistent with the “no net harm” regulatory maxim.
Perhaps most important, EPA must be given realistic but action-forcing deadlines for conducting risk assessment and risk management. Experience under TSCA and other statutes, such as the Clean Air Act hazardous air pollutant program discussed earlier, has proven that, absent such mandates, the agency’s incentives are to avoid making controversial choices and to postpone decisions by playing up the significance of potential new, unanswered questions. Achievable, yet ambitious, deadlines will also better ensure sufficient appropriations through the congressional budget process.
How does amended TSCA compare?
Amended TSCA largely enacts these recommendations. The new law sets up a three-step process (prioritization, risk evaluation, and regulation) for existing chemicals. EPA must look across the universe of chemicals and compare them based on hazard and exposure. Chemicals that are identified as high priority will then go through a risk evaluation exercise to determine if the substance meets the health-based standard. Substances determined to pose an unreasonable risk must be regulated after consideration (but not detailed analysis) of the costs and benefits of at least two regulatory alternatives.
Although Congress justifiably refrained from being prescriptive about risk assessment in the new act, it did require EPA to follow general principles consistent with past NAS recommendations, including use of the best available science and making decisions based on the weight of the evidence—concepts for which EPA must now provide fleshed-out regulatory guidance that will likely direct, but not dictate, the agency’s action. It also requires EPA to consider the relevance of information to a decision, how clearly and completely information is presented, and the extent to which it has been peer-reviewed. Amended TSCA further requires EPA to reduce and replace vertebrate animals as toxicology models “to the extent practicable, scientifically justified, and consistent with the policies of [TSCA],” and requires EPA to develop a strategic plan, with notice and comment, to accelerate the development and validation of nonanimal techniques. Key rule making on how the agency will conduct risk prioritization and risk evaluation must be completed in a year and all other policies, procedures, and guidance must be finalized the following year. Amended TSCA also requires EPA to establish a Science Advisory Committee on Chemicals.
The new law creates a regulatory regime that erases artificial distinctions among chemicals based on non-risk factors, such as economic considerations. The agency must make an affirmative determination on whether a substance is likely or not to present an unreasonable risk. This requirement for an affirmative declaration (previously absent from TSCA), coupled with new legal tools to compel data generation by industry, will help to level the playing field between data-rich and data-poor chemicals. The application of the new health-based standard to all chemicals will level the playing field between new and existing substances.
Amended TSCA maintains prior deadlines (a 90-day review period, plus one additional 90-day extension) for EPA to assess new chemicals. More importantly, it specifies deadlines for each step of the prioritization-evaluation-regulation process for existing chemicals. It also establishes minimum throughput requirements (to start with, EPA must have begun risk evaluations of 10 chemicals by December 2016 and three years later is to have started evaluations of 20 more “high priority” chemicals and to have identified 20 low-priority chemicals requiring no further action). With any luck, these deadlines, and the prospect of judicial review, will work together to lead EPA to make adequately protective decisions regarding clear risks and to avoid regulating tiny risks or making highly precautionary, policy-driven decisions in the face of scientific uncertainty. And, crucially, the deadlines should also override EPA’s reluctance to make controversial decisions.
As noted, amended TSCA replaced the law’s previous “least burdensome” standard with a softer mandate to consider (but not weigh) costs and benefits before choosing restrictions. As a practical matter, EPA will still have to undertake a cost-benefit analysis to comply with an executive order issued by President Clinton in 1993 requiring “regulatory review” of rules that may have significant economic or policy impacts. Amended TSCA also requires the agency to explicitly consider the risk posed by chemical substitutes, which arguably is the same as requiring a “no net harm” test.
Some have predicted that the pace of the program is likely to remain an issue because the sheer number of existing chemicals is so large and the prioritization-evaluation-regulation process can take up to six years for a single chemical.
As to the first issue, amended TSCA requires EPA to “reset” its inventory of existing chemicals into “active” and “inactive” chemicals (depending on whether a chemical was manufactured or processed commercially within the 10 years preceding enactment) and to prioritize from the active inventory; it seems likely that the list of active chemicals in substantial use may be considerably lower in number. EPA can also improve matters by leveraging the risk analysis expertise of external parties. For example, the act requires the agency to develop guidance for any interested third party that wishes to submit a risk evaluation for agency consideration, which should reduce the agency’s workload, although EPA would retain discretion regarding whether and how to use such evaluations. But there is no reason to limit this idea to just risk evaluation. EPA could do the same with respect to the risk analysis component of prioritization and the substitution risk component of regulation. To make this work, the agency must first specify transparent and replicable procedures that it plans to follow and then indicate a willingness to consider external submissions that follow the agency’s own internal procedures. EPA could also provide incentives for such crowdsourcing of risk analysis through reduced user fees.
The TSCA amendments require the agency to be transparent in its procedures and methods. The degree to which EPA lays out replicable methods and follows objective frameworks in each step of risk analysis (formulating problems, reviewing and analyzing the literature, conducting a weight-of-evidence analysis across multiple toxicological studies, and identifying and characterizing uncertainty) will go a long way toward determining whether EPA can achieve the objectives of the new law. Such transparency and consistency will enable manufacturers and processors to forecast how their own products will fare under EPA review and to take actions to minimize regulatory consequences. Anticipating regulatory agency behavior will improve the cost-effectiveness of the regulatory program and increase net public benefits.
By its sweeping amendment of TSCA, Congress has addressed the major legal deficiencies of the statute while leveraging modern techniques of risk analysis to create a level playing field for all chemicals in commerce. The success or failure of the new law will depend on the policy choices the agency makes during the first two to three years of implementation. Only after this implementation phase is over will we begin to see how a risk paradigm bolstered by emerging scientific capabilities fares against the considerable expectations of stakeholders who supported the new law.
Keith B. Belton is Principal of Pareto Policy Solutions LLC (www.paretopolicysolutions.com), a policy analysis and advocacy firm with a focus on making federal regulation more efficient and effective. James W. Conrad Jr. is Principal of Conrad Law & Policy Counsel (www.conradcounsel.com), through which he represents a range of associations and companies in environmental, security, and other legal areas.
Recommended reading
James W. Conrad, Jr., “Reconciling the Scientific and Regulatory Timetables,” in Institutions and Incentives in Regulatory Science, Jason S. Johnston, ed. (Plymouth, UK: Lexington Books, 2012), 150-159.
National Research Council, Review of the Environmental Protection Agency’s Draft IRIS Assessment of Formaldehyde (Washington, DC: National Academies Press, 2011), 112-123.
National Research Council, Science and Decisions: Advancing Risk Assessment (Washington, DC: National Academies Press, 2009), 240-256.
National Research Council, Toxicity Testing in the 21st Century: A Vision and Strategy (Washington, DC: National Academies Press, 2007), 35-52, 98-113.
Daniel Sarewitz, “How Science Makes Environmental Controversies Worse,” Environmental Science & Policy, no. 7 (2004): 396-97.
US Environmental Protection Agency, “The Frank R. Lautenberg Chemical Safety for the 21st Century Act.”
Biosecurity Governance for the Real World
In 2011, controversy erupted over the publication of two peer-reviewed papers that discussed how to convert a deadly strain of influenza in birds (H5N1) to one that could be spread among mammals. How was this research allowed to happen? Was it actually dangerous? Much attention has been given to answering these questions and to considering how we might better address security concerns around biotechnology research more generally.
The H5N1 papers certainly do not mark the first time that worries have been raised about how to prevent scientific research from threatening our security. In the 10 years leading up to these publications, for example, no fewer than four reports came out of the National Research Council about science and security. Those reports, in turn, built on other efforts to govern security concerns in science since the world wars. These efforts continue today as yet another National Academies’ committee, on “Dual Use Research of Concern: Options for Future Management,” considers recommendations to control sensitive pieces of scientific studies, with attendant new procedures for how those sensitive findings would be stored and for vetting who would have access to them.
But before creating another—likely very costly—system to govern security concerns, we ought to consider the validity of the foundation on which this whole form of governance is based. Our current system builds on assumptions about the structure of knowledge and the relationship between science and the state that do not match up with actual practice. By continuing to be guided by such assumptions, we risk overplaying some concerns and expending unnecessary resources and anxiety for marginal returns on security, while missing an opportunity to enhance security in other ways.
Scientific society
Most scientists know that myriad factors—from previous research to funding sources to the pressures of the academic merit system and a drive to profit from new ideas—have a significant impact on the content and direction of research programs. Current research sits within an ecosystem of sponsors, universities, federal and state oversight, and other factors that principal investigators must quickly master if they are to advance their careers. Similarly, scientists must have at least an unconscious appreciation of the importance of things such as lab training to build the skill set necessary to understand the knowledge transmitted in publications and to use those skills and training to create new knowledge and applications. When a paper says, for instance, that a certain method was used, unless a scientist is familiar with that method, the ability to assess and use the knowledge is limited.
Yet when it comes time to consider how best to govern security concerns around science, scientists and security experts often rely on radically oversimplified assumptions about scientific knowledge and its relation to the state and society. These assumptions are familiar to many people, because they are the bedrock of most science education: science is the pursuit of truth unburdened by any concerns about society; if we can just get politics and corporate interests out of the way, scientists will uncover the truths of the universe, and we will all reap the rewards; and science advances through the accumulation of discrete facts and causal assertions—the world is round, nothing goes faster than the speed of light, pathogen A causes disease X.
But basing our governance system on these assumptions is dangerous because they eliminate the social aspects of science, and thereby most of the context within which a governance system must function. Yet this is exactly what we have done, from controlling military research in the world wars to current attempts to govern open biological research that has no military ties.
Governing knowledge
Although there are a few examples of states controlling scientific knowledge before the world wars, the current system for governing security concerns in science has two primary starting points: the Atomic Energy Act (AEA) of 1946 and President Reagan’s 1985 National Security Decision Directive 189 (NSDD-189). The first of these established the idea that limiting access to certain facts and findings through classification was an acceptable mechanism for controlling scientific information that had a national security concern. Unlike wartime-specific controls on science, mostly notably those around the Manhattan Project, the AEA was the first legislation to restrict the flow of scientific information with no real end date envisioned for the controls. Section 10 of the act states that knowledge about nuclear weapons, nuclear energy, and related production processes is automatically classified by the state regardless of where it was produced.
If the AEA established that classification was an acceptable mechanism to govern security concerns in science, NSDD-189 solidified the idea that classification was the only acceptable mechanism. Section III of NSDD-189 says, “It is the policy of this administration that, to the maximum extent possible, the products of fundamental research remain unrestricted. It is also the policy of this administration that, where the national security requires control, the mechanism for control of information generated during federally-funded fundamental research in science, technology, and engineering at colleges, universities, and laboratories is classification.”
Both of these documents have a common assumption about the shape of knowledge: it exists in discrete and recognizable chunks that can be allowed to flow or be withheld at a state’s discretion. This way of structuring knowledge leads to governance systems built around lists, such as the Select Agent List or export control lists. Assuming potentially dangerous knowledge comes in discrete chunks is acceptable if those involved in classifying the knowledge can clearly define which chunks are worrisome, can know from whom the knowledge should be kept, and can actually keep the knowledge from flowing to the malicious user. It is much easier to tell which chunks are worrisome if that knowledge is produced within a security environment such as a weapons lab. In biology, where much of the research is conducted in unclassified and decentralized settings, determining danger is much more difficult. Similarly, in an age of non-state-sponsored violence, differentiating friend from foe at the individual or even lab level takes substantially more resources and intelligence gathering than when conflict was mostly between nations. Such complexities require an appreciation of the factors within a research environment that would make a piece of knowledge dangerous.
The genesis of NSDD-189 also shows how the idea that dangerous knowledge comes in discrete chunks was combined with the assumption that fundamental science is autonomous to create the governance system we are stuck with today. In the 1970s, concern was growing among the defense community that, although export controls were used to slow the process of potentially dangerous technologies falling into nefarious hands, this governance mechanism had no ability to control the flow of ideas and knowledge, and amendments were made to add knowledge to export control lists. Yet the very idea of controlling the flow of knowledge conflicted with the belief, established in the 1950s and 1960s, that unfettered scientific research was the bedrock of progress. Indeed, in 1982, the National Academy of Sciences sought to counter the encroachment of government regulations on fundamental research when it issued the Corson report, Scientific Communication and National Security, which argued that the national security and economic well-being of the nation were actually supported, not undermined, by maintaining unfettered basic scientific research. Thus, the report argued that the vast majority of research should have “no restriction of any kind limiting access or communication,” while allowing that “government-supported research [that] demonstrably will lead to military products in a short time” could be subject to classification. For the gray areas between these two categories, it recommended only that foreign nationals not directly participate in the research and that the government have a right to see articles before publication, but not to modify them. NSDD-189 was, in part, a statement of political support for the Corson report and was a reaffirmation that science best serves society when it is allowed to go where it pleases.
Although this formal assertion of scientific autonomy helped quell the debate between scientists and the national security apparatus, it doesn’t mean that this vision of autonomous science matches up with reality. Although many universities do not conduct classified research, for instance, a substantial amount of funding has come from commercial and defense sources, sometimes with significant strings attached. The Department of Defense (DoD) provided an immense investment in scientific research during the Cold War on everything from transistors to environmental monitoring, and its goals have strongly influenced the direction and content of scientific research. In fact, political systems, institutional bureaucracies (or lack thereof), ethical persuasions, and guiding visions of the type of society we hope to live in are all ingrained in decisions about what scientific knowledge we produce. This is intimately understood by the scientific communities that have orchestrated top level policy attention to their work, such as the Human Genome Project, the National Nanotechnology Initiative, and the BRAIN Initiative.
Does DURC work?
Scientists, as a matter of principle, call foul at any attempt at intervention but in practice understand and shape the societal context within which their work can flourish. The latest iteration of our security governance system is the concept of “dual-use research of concern” (DURC), coined in 2007 by the National Science Advisory Board for Biosecurity (NSABB), a federal advisory committee managed by the National Institutes of Health. DURC takes as its starting point the claim that much knowledge in the life sciences could be maliciously applied, but argues that only a significantly smaller set of it is dangerous and warrants extra attention. DURC is now defined as federally funded “life sciences research that, based on current understanding, can be reasonably anticipated to provide knowledge, information, products, or technologies that could be directly misapplied to pose a significant threat with broad potential consequences to public health and safety, agricultural crops and other plants, animals, the environment, materiel, or national security.”
What should be done when an area of research is labelled as DURC? The H5N1 influenza case was the first major attempt to answer this question. Federal moratoriums were issued, first on H5N1 research for a year, and then on a wider swath of “gain-of-function” research, a policy that is still in place as of late 2016. A moratorium, like classification, is a very blunt tool for governing security concerns, and the scientific community accepted its use only because they understood that moratoriums would be limited in duration. The National Academies held several symposia, the NSABB produced a range of reports, and the government issued two policies on the oversight of DURC.
Yet because these policies are built on the beliefs that knowledge is made of discrete chunks and security must be balanced against academic freedom, they are of limited value in protecting security. DURC oversight covers only US federally funded research—neither philanthropic nor corporate research is covered—and only in relation to items on the Select Agents List, and even then only when one of seven types of experiments are conducted. The inclusion of these seven types of experiments was itself the result of another line-drawing attempt by the National Academies, the 2004 Fink report, Biotechnology Research in an Age of Terrorism, though this list was meant to be only suggestive, not definitive. In defining DURC this way, several biology research projects, such as the 1997 Penn State project to aerosolize non-select agents to bypass the natural defense of the lungs and the 2001 de novo synthesis of the polio virus, which had prompted the development of the DURC concept in the first place, were still not covered. Current research on gene drives, which could be designed to alter or even kill off entire wild populations of organisms, are also not covered as long as they do not use any select agents. Moreover, even if the list of select agents or experiments were to be modified as, for example, the pathogenicity of novel synthetic organisms becomes known, that knowledge may not be developed until well after the organism has been characterized extensively in the open literature, making post-hoc control of information virtually impossible.
DURC oversight is also limited because most journals and universities lack appropriate staff with access to information about possible ways the knowledge might be misused, or with the training to conduct a risk assessment if they did have that knowledge, so DURC research is likely to go unrecognized, let alone adequately governed. In large part, this is due to the narrow focus of any oversight committees a university might have and the lack within scientific training of discussion of how research might cause harm.
These limits and contradictions are an inevitable outgrowth of policy aspirations founded on a simplistic picture of how science operates, and they compromise the nation’s ability to understand and govern security threats that emerge from the growth of scientific knowledge.
Reducing the threat
What if, instead, the United States were to craft a security governance system based on what is actually known about how knowledge is produced and disseminated? Several insights would immediately become relevant. Scientists’ training and resources heavily influence what topics they research and how they conduct their work. By analyzing this training and the environment within which research is conducted, we can gain a much richer understanding of the context within which the research they conduct and publish might merit concern. An analysis of the context of research also will provide a better understanding of how a lab makes use of tacit knowledge that is not formally presented in publications but rather is passed on when scientists work together on experiments and idea development.
The potential value of such an approach is well illustrated by the H5N1 case, where initial concerns within the NSABB about the two papers were alleviated when the authors added discussions of the wider context of epidemiology research within which the studies occurred, the safety and security measures the researchers took to protect themselves and the public, and the goals and public health benefits of the research. The additional information allowed for a security assessment that satisfied the NSABB that the descriptions of the experiment did not constitute a threat. The solution wasn’t to communicate less, but to communicate more!
Knowledge, here, is a fluid entity, and is more about the connections among ideas, people, and the environment in which it is produced than it is a set of discrete facts produced by a single individual in an ivory tower. Of the infinite ways scientists might write a paper about a finding, which knowledge they make explicit and which they leave tacit depends on how they were trained and what rewards and punishments might come from saying—or not saying—certain things. What does this understanding of knowledge production suggest about how we might recognize and govern science-related security threats?
First, those involved with guiding policies must recognize that directions of knowledge production reflect choices made within political, ethical, and institutional contexts, and within such contexts we already limit in many ways the types of knowledge we find it acceptable to produce. Scientific publications are heavily structured by what the people producing and reading them think is acceptable to include. There is an infinite number of details that are not included in these documents because they are seen as extraneous or taboo within the research culture.
Scientists should be better rewarded for openly reflecting on the ethical choices and the safety and security environment of their research, in particular on how their vision of how their research might benefit society and the environment might be someone else’s vision of harm. A simple step toward this change in reward structure for the life sciences might be taken from computer science, where security professionals—“white hats”—specialize in testing computing systems to ensure their security, explicitly showing the limitations of particular configurations of code. A similar community should be built in the life sciences to work closely with those producing new knowledge.
It is not just the scientists who need to become more reflective about the contexts of their work. The security community has its own limitations on how it produces threat assessments based on the assumption of science as a discrete set of facts. As Kathleen Vogel of North Carolina State University said in her analysis of intelligence agencies’ initial conclusion that the H5N1 papers were a security risk, “with the proper training in science and ethnographic methods, one intelligence analyst or contractor working over a ten-day period could have gathered new, substantial information about the H5N1 experiments from site visits … [to laboratories that]would have yielded a wealth of new information about the experimental work that was not available merely by reading the manuscripts.”
The H5N1 case helps make clear that governing security concerns raised by science is not just a matter of controlling the transmission of facts but of understanding how the goals of states, companies, and citizens shape, and are shaped by, decisions about how to direct research and innovation. If scientists want to do something malicious with a piece of knowledge, they will need much more than the published article. Monitoring, therefore, needs to attend not to any particular piece of knowledge, but to the broad array of factors (training, resources, tacit knowledge, intent to do harm, and so on) that combine with things such as scientific publications to produce a credible threat.
Second, rather than building fences around narrow objects of concern, we should be building conversations across areas of relevant expertise. A promising example of such an effort is the Federal Bureau of Investigation’s Safeguarding Science Initiative within the Weapons of Mass Destruction Directorate’s Biological Countermeasures Unit. This unit focuses on building long-term relationships with the broad range of labs and researchers who are conducting, or might conduct, research with potential security concerns. Instead of creating an antagonistic relationship with the scientists, the initiative is focusing on becoming the place that sensible scientists would turn to when they have a question about the security aspects of their work. This approach recognizes that both scientists and security professionals have areas of expertise that need to be meshed together to understand what should count as research of security concern. It also places an emphasis on monitoring developments—in knowledge, but also in resources, intent, networks, and so on—in addition to creating static lists of objects of concern and particular points in the knowledge production and innovation cycles where assessments occur. The Safeguarding Science Initiative should be studied for its strengths, weaknesses, and applicability across subfields of life sciences that raise potential security concerns.
Third, security itself should not be considered in isolation from the broad range of values that motivate the quest for knowledge. Once we start to appreciate that it is impossible to separate the production of knowledge from the societal goals that guide and are supported by that knowledge, the debate can shift from whether a government should or should not intervene in science to a discussion about what types of societal goals we want to incorporate in the research we promote. From this perspective, security concerns may even prove complementary with a wider set of other concerns that a society may have. For example, within the world of export controls, countries work closely with companies that make military and dual-use technologies because the goals of intellectual property protection and national security often align when trying to control the flow of information that is sensitive for both economic and security reasons.
As the National Academies and the US government continue their efforts to govern the security concerns of biological research, they should move away from the limits of the DURC concept. The first step down this path is to stop using the polarizing discourse of security emergencies and academic autonomy. Knowledge is always produced within a social context, and security is only one of many goals a society is striving for. From that starting place, we can begin to build a contextual approach to governance that is appropriate for the complex practice of real-world science.
Middle Class Muddle
The fate of the US middle class has taken center stage in political and economic discussions. Donald Trump promises to bring back the well-paying jobs that he says were lost to foreign countries because of misguided federal regulations and trade policies. Hillary Clinton has joined Trump in expressing her doubts about the impact of trade agreements—“I will stop any trade deal that kills jobs or holds down wages, including the Trans-Pacific Partnership”—but she also acknowledges the need to provide the education and training necessary to qualify more Americans for the jobs of the future.
Speaking at the Center for American Progress on September 8, Vice President Biden quoted the Irish poet William Butler Yeats in describing the evolving labor market: “All is changed, changed utterly.” Biden added that one of the few things about which Democrats and Republicans agree is that twelve years of education is no longer sufficient preparation for the demands of the labor market. He added that workers need not only better workplace skills but also a better understanding of what employers expect, where the good jobs are, and how to apply for them.
Politicians not surprisingly look for political explanations for problems. Economists take a different view. Speaking on a panel following Biden’s speech, Princeton University economist Alan Blinder observed that the growing disparity in wages between the affluent and the middle class is a result of market forces, not government policy. He added, however, that the government could be doing more to offset the impact of the wage gap through tax policy and other measures. He added that government spending on infrastructure, education, and training could benefit the middle class in general by stimulating the economy and help individuals acquire the skills necessary to prosper in a changing labor market.
The prospects for the middle class are further dimmed by a decline in the rate of productivity growth. When productivity growth lags, the economic pie grows more slowly, and the competition for the slices of the pie becomes more intense. The day after Biden’s speech, the Brookings Institution hosted a conference on the “productivity puzzle” to discuss what is behind lagging productivity growth and how to revive it.
Martin Baily of Brookings presented an overview of trends in productivity and an analysis of the factors that contribute to growth. Analysis of the periods of rapid productivity growth (1948–1973 and 1995–2004) reveal that the most important contributing factor was multifactor productivity, which consists of improvements in technology, better organization of production, and higher-value products and services. Capital deepening was of somewhat smaller importance, and the labor composition (the education and experience of the workforce) made a relatively small contribution.
At first glance this would indicate that investments in worker skills would not have a significant effect on economic productivity, but Bailey argued that in this case the data might be misleading. He pointed out that a large gap exists between the performance of the most and least productive US firms and industries. He proposes that one explanation for this gap could be the lack of depth in the skills of workers and managers. This would explain why companies that can see how their industry leaders have boosted productivity are unable to implement the same techniques themselves. Advanced technology and managerial methods might require a higher level of skill throughout the workforce in order to be implemented effectively.
Emerita Berkeley professor Bronwyn Hall observed that one reason that labor composition has not made a major contribution to productivity growth is that we have not seen a large improvement in worker skills. She argues that until we make a serious effort to enhance skills across the workforce, we will not know whether it will have an appreciable effect on productivity growth.
Harvard’s Robert Barro mused about the anomalies of the feeble recovery that has occurred since the recession that began around 2008. Many economists worried that the recovery would produce little job growth because companies would implement productivity-enhancing measures rather than simply hire back workers. But there has been relatively low productivity growth and a healthy rate of hiring. Barro characterizes it as a “job-filled non-recovery.”
The experts at the Brookings event were judiciously reluctant to make predictions about the future rate of productivity growth. The loose consensus was that a return to the postwar boom years is unlikely but that the very gloomy outlook of Northwestern University’s Robert Gordon is probably too dire. So if we are heading into a period of middling productivity growth, that is not an encouraging prospect for the middle class workers who have seen their incomes stagnate. And if there will be no supercharged economy to come to their rescue, we need to look elsewhere for actions that will brighten their prospects.
A few days after the Brookings meeting, the Census Bureau released the encouraging news that US median household income increased by 5.2% in 2015, which was the first real increase since 2007. And whereas most of the financial gain in the early stages of the recovery was captured by the wealthy, the data show that households on all steps of the economic ladder had benefited. This is clearly welcome news, but it must be understood in context. The 2015 median of $56,500 is still 1.6% below the 2007 median and 2.4% below the 1999 median. Rising employment levels are the key to the 2015 gains, but this does not address the long-term need for productivity growth that will be essential for future gains.
In searching for answers to the plight of the middle class, many of the experts mentioned education and training. They observed that the nature of work is changing in virtually every sector of the economy and that the skills employers are seeking are also in flux. This presents a challenge for young people eager to acquire desired skills as well as for current workers who have well-rewarded skills that could easily become obsolete.
The United States is doing too little to address this challenge. It spends less than 0.05% of its gross domestic product (GDP) on vocational training, a far lower percentage than is found in most developed countries. Finland and Denmark spend about 0.5% of GDP, more than ten times the US rate, and France and Germany spend five times as much. The nation needs to devote more attention to developing the skills that will be required to earn an adequate middle-class living in a technologically advanced economy and to create the high-quality labor force that make a significant contribution to boosting economic productivity.
The first task is to identify the skills and the jobs that need attention, and the four articles that follow make an important start. They include an overview of the many parts of the economy where technical skills are becoming ever more necessary; a closer look at the ways that computing and information technology are transforming job requirements; a deep dive into the rapidly evolving health care industry; and a call for better information to help workers identify training, education, and job opportunities, and to enable policymakers identify the areas where government actions are needed.
To maintain the reality of the American dream, the United States needs to ensure that it provides the educational and training opportunities that its citizens can use to build rewarding careers. But the development of worker skills can do more than contribute to the economic well-being of the middle class. For reasons that we do not fully understand, advances in technology are not resulting in the same spur to productivity growth that they did in the past. It could be that worker skills, which were not a major factor in previous productivity spurts, are the missing ingredient that will complete the recipe for future productivity gains.
The Benefits of Technocracy in China
Since the Reform and Opening initiated by Deng Xiaoping in 1978, any casual observer of China’s leaders might note how many of them were educated as engineers. Indeed, at the highest level, former presidents Jiang Zemin (1993–2003) and Hu Jintao (2003–2013) as well as Xi Jinping (2013–present) all studied engineering, although Xi subsequently did academic work in management and law. And an engineering influence exists not only at the very top. A high proportion of government officials at city, provincial, and national levels have had some form of technical education. For example, of the 20 government ministries that form the State Council, more than half are headed by persons who have engineering degrees or engineering work experience. As a result, foreign analysts have suggested for some time that China functions as a kind of technocracy—a nation run by people who are in power because of their technical expertise—and have often criticized it as such. This assessment reflects a common Western view that technocratic governance is inherently anti-democratic and even dehumanizing.
But what does technocracy mean today, especially in China? Given China’s remarkable emergence in recent decades as a vibrant player on the world economic and political stage, might technocracy in the Chinese context have some positive characteristics?
To understand technocracy in China, one must first have a sense of historical context and above all an understanding of the cultural impact of a series of devastating military humiliations—the Opium Wars of the 1840s and 1860s, in which, in the name of free trade, China was forced to allow the importation of opium and the Summer Palace was sacked; an 1895 war in which Russia captured the Liaodong Peninsula and Japan took Taiwan, the Penghu Islands, and eventually Korea; and the 1899 Boxer Uprising against Christian missionaries, to which Great Britain, France, the United States, Japan, and Russia all responded by looting and raping in Tianjin, Beijing, and elsewhere. In reaction to these defeats, Chinese intellectuals turned the Qing Dynasty thinker Wei Yuan’s injunction “to learn from the West to defeat the West” into a social movement motto. Early Republic of China attempts to learn from the West actually involved the conscious importation of technocratic ideas by the Nanjing government. A number of Chinese who studied in the United States during the 1920s returned home influenced by American technocratic ideals of such figures as Thorsten Veblen and Howard Scott. One example is Luo Longji, who studied at Columbia University from 1922–1923 and returned to China to publish a number of articles arguing for what he called “expert politics,” his term for technocracy. Luo subsequently founded the China Democratic League, which remains one of the eight non-Communist political parties represented in the National People’s Congress.
China today is living through a heroic stage of engineering in its urbanization and infrastructure development—something that would not be possible without technical competence playing a major role in the exercise of political power.
Initially, however, all attempts to learn from the West had to struggle against internal political disorder (the fall of the Qing Dynasty in 1911 and a resulting long-term civil war) and renewed invasion by Japan (from 1931 to 1945, through which China endured the brunt of the World War II Pacific Theater). When Mao Zedong and the Communists won the civil war and on October 1, 1949, declared the People’s Republic, political consolidation and technical development vied with each other for priority.
For the next quarter century, until Mao’s death in 1976, the purity of redness often trumped technical engineering competence. The disaster of the Great Leap Forward (1958–1961) was caused by ignoring technological expertise, especially about agriculture, and the Cultural Revolution (1966-1976) closed many universities in the name of learning from the peasants. The Reform and Opening that began two years after Mao’s death naturally became an opportunity to rehabilitate expertise, both engineering and economic. In policies influenced by the successful development pathways pursued by technocratic regimes in Singapore, South Korea, and Taiwan, the new paramount leader, Deng, moved engineers into critical government positions. Hu Yaobang, as Party Chairman (1981–1982) and General Secretary of the Communist Party (1982–1987), further proposed that all leading government personnel be trained technical specialists. The technocratic practice of scientific management, which Vladimir Lenin had declared as exploitative under capitalism but beneficial under socialism, offered a bridge between engineering and economics.
The varieties of technocracy
Before discussing what technocracy has come to mean in China today, I want to first step back to briefly explore how the term has come to be understood in the Western intellectual tradition. In one of the few empirical studies of technocracy, political scientist Robert Putnam defines technocrats as persons “who exercise power by virtue of their technical knowledge” and describes the “technocratic mentality” in terms of five key characteristics:
Confidence that social problems can be solved by scientific or technological means.
Skepticism or hostility toward politicians and political institutions.
Little sympathy for the openness and equality of democracy.
A preference for pragmatic over ideological or moral assessments of policy alternatives.
Strong commitment to technological progress in the form of material productivity, without concern for questions of distributive or social justice.
Putnam’s 1977 study further distinguishes between two types of technocrats: those with engineering technical knowledge versus those with economic technical knowledge—noting that the two groups diverge with regard to characteristics three, four, and five. Economic technocrats were more likely than engineering technocrats to grant importance to politics and equality and to be more interested in issues of social justice.
In a recent revisiting of the comparison, Richard Olson’s Scientism and Technocracy in the Twentieth Century: The Legacy of Scientific Management (2016) suggests that subsequent decades have witnessed something of a reversal. Engineering education has called increasing attention to social contexts that take politics and social justice seriously, while economics has become more quantitative and less concerned with social issues.
Neither author notes, however, the significant roles played in all modern societies by what could be called limited or sectoral technocracies. Technical knowledge is a basis for power that democratic societies willingly grant: for example, by delegating authority to the military, physicians, and civil engineers. At the same time, such societies may bitterly contest technocratic authority with regard to evolutionary biologists, agricultural researchers, and climate scientists.
Such distinctions help make clear what is really at stake in concerns about technocracy. In short, governance by technical experts and governance employing such principles as those of scientific management are not the same. When exercising political power, technical elites such as engineers and economists may also use the authority of their expertise to advance positions or policies that are not simply technical. In doing so they can easily ride roughshod over the interests of those they are supposed to serve, and in the process use their expertise to preserve their own political interests.
In Western developed countries, technocracy has thus been subject to multiple criticisms. Marxists attack technocracy for helping capitalism control workers. Humanists claim technocracy turns humans into machines. Libertarians criticize technocracy as encroaching on individual freedom. Historicists and relativists criticize scientific principles and technological methods for not adapting to human society.
Yet advanced techno-scientific society depends crucially on some level of technocratic governance. City mayors cannot provide safe water systems without asking engineers to design them. Governors cannot promote regional disease prevention and healthcare without medical and public health professionals; they cannot reduce environmental pollution without technical experts to monitor air and water quality. Heads of government would not even know about the ozone hole and global climate change without scientific advisers. The progressive deployment of technocratic elites in the practices of governance, even when under the supervision of non-technocratic elites, is a critical feature of all social orders today.
Maybe the fact that some form of technocracy is one of the basic characteristics of contemporary politics is a reason it is so often criticized. There is certainly some sense in which contemporary politics is characterized by a kind of universal resentment against the unintended consequences of a techno-scientific world that, along with all of its benefits, seems to be depriving us of traditional solaces and stabilities.
Technocracy, Chinese-style
In The China Model: Political Meritocracy and the Limits of Democracy (2015), political theorist Daniel A. Bell provides a strongly positive interpretation of the current situation in China. As Bell sees it, the fact that Chinese leaders, such as President Xi, have spent years managing cities and provinces as well as serving time in national ministries develops a level of expertise in both engineering and economics that is often short circuited in Western (especially US) one-person, one-vote democracies. The further fact that independent surveys repeatedly show high levels of public satisfaction with the Chinese government (regularly higher than is the case in Western democracies) provides a sound argument for legitimacy.
Certainly, it is the case that China today is living through a heroic stage of engineering in its urbanization and infrastructure development—something that would not be possible without a significant level of technical competence playing a major role in the exercise of political power. For decades China has, in fact, been educating engineers to an extent that has raised competitive concern in US engineering circles. According to the US National Academies report, Rising Above the Gathering Storm: Energizing and Employing America for a Brighter Economic Future (2007), in China, 50% of all undergraduates receive degrees in engineering, whereas in the United States, it is only 15%. Although that number can be questioned, it probably remains the case that in China, a much greater percentage of university degrees are awarded in fields of engineering than in the United States. At the celebration of the 20th anniversary of the Chinese Academy of Engineering in 2014, President Xi not only gave an address to all attendees praising the contributions of engineers to current Chinese achievements but sat in the audience and took notes on other talks by European and American speakers. In doing so, he publicly declared himself to be occupying dual roles, both as political leader and as technical expert. It’s difficult to imagine a US president doing the same.
Yet Daniel Bell’s interpretation of China as a soft technocracy is not realistic in terms of the ways in which political elite selection and promotion take place in the People’s Republic. The process by which Chinese politicians rise to power is not fully determined by institutional processes but remains strongly influenced by individual, private relationships. Many experts come to power not because of competency or technical professional qualifications; loyalty to Communist Party of China ideology and politics and building strong relations with party leaders remain critical factors.
Thus, the situation in China with regard to technocracy is complex and ambiguous. Since 1978, more and more technical experts have become part of the government, creating a limited or soft technocracy. But the ideal of socialism has not been replaced by the ideal of technocracy. Indeed, the extent to which Chinese technical experts, especially those at high levels in the government, actually employ their engineering or economic knowledge once they gain access to political inner circles is far from clear.
Nonetheless, in China today, there exists a more favorable attitude toward technocracy than is found elsewhere. I see three reasons for this overall positive view. One is a heritage of scientism. From the second half of 19th century, Chinese anxieties about backwardness have promoted a faith in science. Since then, although conditions have changed, scientism has remained popular. Insofar as it is scientism applied to politics, the Chinese tend to have a positive attitude toward technocracy.
Technocracy also fits with the Chinese tradition of elite politics and the ideal, to reference a Confucian phrase, of “exalting the virtuous and the capable”—although the traditional tendency was to privilege virtue over capability. Although Chinese virtue politics emphasized knowledge of the Confucian classics instead of Western technical expertise, both assumed that knowledge was more important than the representation of the interests of those being governed.
Finally, there is the close relationship between socialism and technocracy. Socialism remains the dominant ideology in China. The founder of the ideal of technocracy, Henri de Saint Simon, was criticized by Marx and Engels as a utopian socialist, but his thought still exercised an influence in Marxist theory. Veblen, another important defender of technocracy, was also to some extent a Marxist. There are many similarities between technocracy and socialism: a common promotion of economic planning, the idea that capitalism will perish because of problems created by production, and a strong emphasis on the values of science and technology.
The positive attitude toward technology present in contemporary Chinese culture is an advantage for developing a kind of technocracy appropriate to China. Indeed, I would defend some form of technocracy as progressive, especially for China. I hold this view not because of any inherent virtues that one might ascribe to technocracy, but because any assessment of technocracy must consider the broader political context. Technocracy is a better and fairer use of power than any other hierarchical system. Against the background of the Chinese heritage of a long feudal culture, technocracy is a better way to confront social problems than authoritarian politics divorced from technical expertise.
Moreover, in a socialist system in which political ideology plays a prominent role, technocracy can improve the status of intellectuals. From 1949 to 1978, Chinese intellectuals were oppressed, and even now do not receive the kind of respect necessary for thriving in the knowledge economy. In China, irrational political activities and political decision making is all too common. Contemporary Chinese administrative activities need scientization and rationalization. Although scientization and rationalization can go too far and create their own problems, their absence in any nation will result in more and worse problems, all the more so in China where, as I have noted, pathways to political advancement are often personal and private.
From the beginning, technocracy has taken on radical and moderate forms. In the radical form, technocrats have sought to re-engineer the human condition and have given birth to the tragedies of centralized planning and large-scale social engineering. By contrast, moderate technocrats seek only to practice what Karl Popper called “piecemeal social engineering,” that is, to introduce appropriate, rational reforms into society and then to undertake evidence-based assessments. Along with Popper, John Dewey, and others, I think some form of soft technocracy is more progressive for China than other proposals promoted by the West that would emphasize only democratic institutions without acknowledging the political and historical context from which China’s governing institutions continue to evolve.
Liu Yongmou is professor of the philosophy of science and technology at Renmin University of China.
From the Hill – Fall 2016
Republican
2016 Party Platform
On July 18, the delegates to the Republican National Committee formally adopted the official 2016 Republican platform, which includes numerous policies and principles involving science policy issues. In regard to the environment, they promise to eliminate the current administration’s Clean Power Plan; prohibit the EPA from regulating carbon dioxide; finish the Keystone XL Pipeline; and promote transferring environmental regulatory power from federal to state jurisdiction. They consider climate change to be “far from this nation’s most pressing national security issue” and do not support international agreements such as the Kyoto Protocol or the Paris Agreement. The platform also argues that it is illegal to contribute to the UN’s Framework Convention for Climate Change and its Green Climate Fund due to Palestine’s status as a member state of the United Nations. The GOP supports developing all forms of marketable energy, including private sector development of prominent renewable energy sources; promotes lifting restrictions to allow for the development of nuclear energy; and supports protecting the national grid from an electromagnetic pulse.
The GOP platform also supports launching more scientific missions to space and policies aimed at guaranteeing that US space-related industries remain a source of scientific leadership and education. The platform also states that “Federal and private investment in basic and applied biomedical research holds enormous promise, especially with diseases and disorders like autism, Alzheimer’s, and Parkinson’s.” It recognizes that underserved demographic groups must be considered in advancing research in cancer and other diseases. They oppose embryonic stem cell research and human cloning for research or for reproduction, but do support research involving adult stem cells, umbilical cord blood, and cells reverted back into pluripotent stem cells. They promise to reform the Food and Drug Administration (FDA) and to address regulations that inhibit bringing new drugs and devices to market. They support the Right to Try legislation that would allow terminally ill patients to use investigational medicines not yet approved by FDA, and they endorse the Comprehensive Addiction and Recovery Act, which is aimed at overcoming the opioid epidemic.
Democratic
2016 Party Platform
On July 21, the delegates to the Democratic National Committee formally adopted the official 2016 Democratic platform, which includes a multitude of policies and principles related to science policy issues. It supports public and private investments in science, technology, research, and development. It advocates for allocating funding to develop diagnostic tests for the Zika virus, as well as for a vaccine and treatments. It states that the US Center for Disease Control and Prevention (CDCP) must have the resources required to study gun violence as a public health issue. To improve the nation’s cybersecurity, it calls for an expansion of the Obama administration’s Cybersecurity National Action Plan.
To combat climate change and protect the environment, Democrats state they will implement and expand pollution and efficiency standards, including the Clean Power Plan, and will meet the goals of the Paris Climate Agreement. They plan to eliminate certain tax breaks and subsidies for fossil fuel companies and to expand tax incentives for energy efficiency and clean energy companies. They plan to reauthorize Environmental Protection Agency regulation of hydraulic fracturing. Democrats propose implementing safeguards to protect local water supplies and to eradicate lead poisoning. They plan to expand clean energy research and development. They oppose the Keystone XL Pipeline, drilling in the Arctic and off the Atlantic coast, and attempts to decrease the effectiveness of the Endangered Species Act.
The Democrats plan to promote a number of policies to protect the health of US citizens, including fully funding the National Institutes of Health (NIH). They plan to fight the drug and alcohol addiction epidemic, especially the opioid crisis, through prevention and treatment efforts. And they propose setting a cap for the amount Americans
must pay out-of-pocket each month on prescription drugs.
The Democrats also oppose the proliferation of nuclear, chemical, and biological weapons and support decreasing spending on nuclear-weapons related programs. They support the National Aeronautics and Space Administration and promise to launch new missions to space. They also promise to ensure all students have the chance to learn computer science by the time they graduate from high school.
Congress continues work on FY 2017 budget
With the looming end of the fiscal year (September 30) and the upcoming election (November 8), Congress still has a long way to go to wrap up FY 2017 appropriations. None of the twelve annual spending bills have yet been signed into law, and few have been approved by either chamber. To avoid a government shutdown, Congress will have to pass a continuing resolution that will punt funding decisions at least until late fall so that it can continue to grapple with lingering floor fights over policy riders on everything from abortion to Zika.
In spite of these now-standard obstacles afflicting the process, forward movement has not been totally absent. Both the House and Senate Appropriations Committees wrapped up work on their twelve annual spending bills before hitting the annual summer recess in mid-July. Assuming Congress eventually agrees on an omnibus spending package, the outcomes of this work will shape that debate. With that said, here are some brief observations on where things stand for science in early September.
Overall R&D budget figures are predictably modest—with the exception of the National Institutes of Health (NIH). The spending caps reached in the FY 2016 budget deal were inevitably going to limit the upside for science funding this appropriations cycle. Under that deal, discretionary spending, which provides most science and technology funding, is essentially flat in FY 2017.
Overall budget tightness is reflected in most spending bills (See Table 1). Barring a significant change, the nondefense R&D budget, which includes the National Science Foundation (NSF), the National Aeronautics and Space Administration (NASA), and others, wouldn’t change much in FY 2017, with an aggregate 1.3% increase in the House and a 2.8% increase in the Senate, according to current AAAS estimates (compared to a rate of inflation of 1.8%). On the defense side, the data appear to show the National Nuclear Security Administration (NNSA) with a major boost in FY 2017, but this is partly due to a large, unexplained drop in R&D funding reported for FY 2016. That drop does not reflect what actually happened in the underlying appropriations accounts, which were increased by Congress last year, and thus may be an accounting oddity. The Department of Defense (DOD) would see little R&D change overall, though Senate appropriators were more generous than their House counterparts in supporting DOD science and technology. Heated debates over use of the Pentagon’s war funds seem to have had only limited impact on the R&D bottom line.
The significant outlier to all this, of course, is the NIH, which has received a billion-dollar increase from House appropriators and a $2-billion increase in the Senate. These sizable increases would seem to ensure that NIH will finally return to pre-sequestration budget levels and pull up the overall R&D budget numbers in the process.
Although Congress hasn’t been particularly generous, it has in fact protected research funding. Based on appropriations decisions so far, the federal research budget for FY 2017 will likely end up around $3 or $4 billion higher than the administration had requested. The president’s request had proposed billion-dollar cuts to the base budgets at NIH and NASA, and a 9% reduction in DOD basic research. This collectively would have meant a small reduction for applied research funding and a deeper cut for federal basic research overall. Appropriators have mostly rejected these proposals: beyond the aforementioned NIH boost, NASA appears set up for a small increase, and appropriators in the Senate (but not the House) turned away the proposed DOD cut.
When the administration made its request for cuts in science funding from the discretionary budget, it attempted to offset the cuts by requesting that there be more than $6 billion in R&D support that would be considered mandatory spending, in the same category as Social Security and Medicare.
Mandatory spending—also known as direct spending—refers to any spending written into and required by laws other than appropriations bills. Establishing a mandatory funding stream requires new legislation, and that legislation would have to come from the authorizing committees rather than the appropriations committees. One reason mandatory spending is an attractive alternative for the administration is that it is not subject to the discretionary spending caps. But it does come with some challenges. For one, appropriators don’t always favor mandatory spending, as it takes the power to allocate federal dollars out of their hands. In addition, new mandatory spending is subject to PAYGO rules, which means it must be deficit-neutral and offset by revenue increases or spending cuts elsewhere.
This extra funding may have made the numbers look better in the aggregate, but reaching for mandatory spending was a long shot, in the same way that earlier proposals to blow past the discretionary budget caps were also longshots. Congressional leaders have rejected this mandatory funding approach. Instead, they selectively increased discretionary funding for NIH, NASA, and DOD, but left R&D funding at other agencies essentially flat. It has also meant that some priorities tied to new mandatory spending in the president’s budget—perhaps most notably the Cancer Moonshot and the National Network for Manufacturing Innovation—have received virtually no funding.
Climate, environment, and energy funding conflicts remain in place. One can probably bookmark this paragraph and return to it every year: the partisan funding cleavages over climate science and energy technology remain particularly strong. The administration had once again proposed major increases for renewable energy and climate- and environment-related research across several agencies, while reducing net new funding for fossil energy R&D. Once again, Congress has rejected these proposals. House Republicans have shown opposition across the board. In some cases Senate Republicans (along with their Democratic colleagues) have sought middle ground between the two, though Senate appropriators also have clear preferences on, for instance, Environmental Protection Agency science and technology funding, nuclear power technology development (funded by the Department of Energy), and NASA’s Earth Science program. Budgeting is a negotiation, and clearly the administration hasn’t found the right offer to appeal to its congressional foils on its low-carbon technology plans.
Science and technology funding can at times be an innocent bystander during larger budget and policy fights, and this year is an example of that, as multiple spending bills with majority support have been hit with controversial policy riders. These have included language on Iran (the Energy & Water bill); gay rights (Energy & Water); gun control (Commerce, Justice, Science); and Planned Parenthood and confederate flags (Zika bill, itself attached to a transportation/veterans package), among other items. Debates over policy riders have slowed the budget process and are one factor contributing to the need for a continuing resolution. And the length of any continuing resolution will also be contentious, as members of Congress consider how the results of the upcoming election will affect the relative strengths of the parties.
Survey shows public wary of human enhancement
A recently released survey by the Pew Research Center revealed that the general public is more worried than enthused about the use of biotechnology to enhance human ability. The survey questioned them on the use of gene editing for reducing risk of disease in babies; utilizing brain chips for enhancing cognitive ability; and using synthetic blood for improving physical abilities. The results showed that survey participants “would be ‘very’ or ‘somewhat’ worried about gene editing (68%), brain chips (69%), and synthetic blood (63%).”
FDA approves field test of genetically engineered mosquitoes
The Food and Drug Administration gave the regulatory greenlight to a proposed experimental release of genetically engineered mosquitoes in Key Haven, Florida. The experiment will test the ability of genetically engineered male mosquitoes to suppress the local population of Aedes aegypti mosquitoes. The wild mosquitoes have been linked to the first cases of locally transmitted Zika infections in the continental United States. The agency declared that the experiment poses no significant impact on the environment. Still, the final regulatory action does not clear the way for the field test, as permission to move forward awaits the outcome of a referendum vote by the Key West residents on November 8.
Visualize Whirled Peas
Imagine the scene: you’re Everett Dolman, a faculty member at the US Air Force’s School of Advanced Air and Space Studies with significant security and military experience, and an eager publisher suggests the book title of Can Science End War? What do you do with such a naïve suggestion?
To his credit and without unnecessary prevarication, Dolman provides the answer on page six of the book: “The bottom line is that science cannot end war, for science is less an ideology than a tool. It serves those who use its methods.” At which point the reader observes that the book has barely begun, and can’t help but wonder what the rest of the pages are for.
But before exploring that question, consider the publisher’s choice of title for a moment. To begin with, “science” is not really the relevant domain if one wants to explore war, because science is, as Dolman points out, a “way of knowing”—as well as, occasionally, an ideology that raises applied rationality to theological levels. War, as writers from Sun Tzu and Machiavelli onward have pointed out, is not a process that can be explained or managed through the use of applied rationality: there is no “science of war.” At the height of the Enlightenment, theorists such as Carl von Clausewitz and practitioners such as Helmuth von Moltke emphasized the “fog of war” and the interplay among politics, personality, and armed forces. Even Antoine-Henri Jomini, the contemporary of Clausewitz considered by many to have made the most rigorous effort to capture war in a rational, rule-based theory, never pretended war was predictable; indeed, he explicitly noted that war was not a science, but an art.
Although warfighting strategies, not surprisingly, reflect the knowledge and zeitgeist of their times, there is no “scientific” theory of war, even in periods like today, when the scientific discourse dominates all others. Thus current thinkers such as John Boyd, who have been called “post-modern military strategists”—a great term, that—and who integrate a lot of modern science into their thinking, don’t make war out to be either “scientific” or “rational.” That doesn’t mean that a good general can’t fight a war more successfully than a bad one or that officers can’t be taught how to think about conflict productively, but it does mean that war is a complex adaptive system. Any internally coherent and rational perspective on war, useful as it may be, must therefore also be partial, arbitrary, and inadequate in the event. So, no science of war.
Further confusing the titular question, science isn’t deployed on the battlefield, technology is. There was certainly deep science behind the Manhattan Project, for example, but it was technology that was tested in the desert in New Mexico in July 1945 and it was technology that was subsequently dropped on the Japanese cities of Hiroshima and Nagasaki. Earlier, technological advances in metallurgy and cannon manufacture, along with gunpowder innovations that made it more stable and transportable, enabled French artillery in 1495 to breach the previously impregnable Italian fortress of Monte San Giovanni and march down the spine of Italy. Technology helped Europeans, faced with this stunning power of mobile cannon, to redesign their fortresses to be resistant to them in a matter of a few decades. Technologies, not science, are where the rubber meets the battlefield.
There is also the question of what “war” actually means today. Russia successfully invaded Crimea in 2014 using information techniques and technologies that never rose to a level of “war” sufficient to justify a kinetic US or NATO response. Some Chinese strategists espouse a doctrine of “unrestricted warfare,” which explicitly de-emphasizes violence in favor of long-term cultural, economic, and technological conflict. Probably the most important confrontation today is the cyber conflict between China and the United States. This conflict has very few of the traditional characteristics of war and is invisible to most of the public of both nations.
Harvard political scientist Joe Nye and others have suggested that much conflict today involves “soft power,” the ability to get what you want because people admire your culture, your laws, and the model you set for others, rather than because you have a large military. At the other end of the spectrum, a constant state of low-level violence that is not structured enough to be anything like traditional war characterizes parts of the Middle East and Sub-Saharan Africa. Some call this condition “neomedievalism”; foreign policy expert Sean McFate, in his book The Modern Mercenary, describes it as “durable disorder.” Violence, especially in those neomedieval environments where states are weak or failing, may be endemic, but many of today’s most difficult and intransigent conflicts are definitively not traditional military confrontations.
Finally, the title makes an obvious assumption that raises an important question: is war something that science, or we, should even try to end? In other words, is war bad? Clearly, war itself, especially for the civilians caught up in it, is a destructive and brutal process. But some thinkers, such as historian Ian Morris in his 2014 book War! What Is It Good For?, suggest that by creating strong states and international order, wars have overall made humanity safer and richer. This is a somewhat cheerier reflection of Thomas Hobbes’ Leviathan: large institutions such as states, even if they are autocratic and cruel, are preferable to the sort of random violence that parts of Sub-Saharan Africa and the Middle East suffer from today. One does not need to accept these arguments entirely to recognize that, like any complex human activity, the constellation of activities we call war does not fit easily into simplistic moral bins.
Given an incoherent titular question answered by page six, then, what does Dolman do for the rest of the book? In part, he expands on his page-six conclusion that science cannot end war in language that is clear and interesting. Because this is a short book—173 pages of content—he does not include a lot of detail, but he does provide a nice overview of the intersection of science (mainly technology) and war, emphasizing primarily Western examples.
Although the choice of topics to address reflects the author’s idiosyncratic experience and interests, it doesn’t result in a boring book. For instance, perhaps reflecting his area of interest, Dolman at one point suggests that science might help end war if space weapons and commercialization are appropriately developed and deployed. Even though this makes a good scenario, some might find the relatively short discussion unpersuasive given the seemingly inexhaustible human ability to convert new domains to old antagonisms.
Certainly cyber started out with similarly high hopes. Remember cyber libertarian John Perry Barlow’s “A Declaration of the Independence of Cyberspace,” written some 20 years ago? “Governments of the Industrial World, you weary giants of flesh and steel, I come from Cyberspace, the new home of Mind. On behalf of the future, I ask you of the past to leave us alone…. You have no sovereignty where we gather.” Alas for libertarian fantasies, cybercrime and cyberwar are defining fronts in geopolitical conflict today, and cyber realms are increasingly nationalized, criminalized, monitored, and militarized. Dolman does not make clear why, if space is to be commercialized and colonized and peaceful, it does not first have to face the struggle to determine which Leviathan will ensure the necessary order.
Another interesting tidbit is dropped when Dolman notes that “modern warfare is information warfare,” which was certainly borne out by Russia’s Crimea invasion. He concludes several pages later: “The singularity [Ray Kurzweil’s famous point at which technology becomes self-aware and self-replicating] has already happened, and it occurred in the recent past when the amount of data collected and stored became so large that new, unanticipated properties of human and computer interaction spontaneously emerged in the form of a new kind of intelligence.”
Especially given the rapid advances in deep learning artificial intelligence, and the critical role of cyber conflict in modern geopolitical maneuvering, this observation might be worth another essay in itself.
In short, this is a charming, worthwhile, and idiosyncratic extended essay that is well worth the modest investment of time and effort required to enjoy it. In return for an afternoon or two of pleasant reading, you get a little bit of history, a little bit of policy, a little bit of technocratic musing, and even a quick look at a future warrior, in the company of a knowledgeable companion.
Making Sense of the World
In 1831, Michael Faraday discovered magnetic induction, where a magnet moving in a coil of wire produces an electric current. Faraday’s insight eventually led to both electric power generators and motors. When viewed through the lens of our secular age, the relationship between electricity and magnetism seems devoid of metaphysical speculation and religious sentiment: scientific discovery proceeds through data and empiricism alone. Luckily for us, Michael Faraday didn’t view the world in such simplistic terms. His Christian faith was at the center of everything he did, including his science. Rather than impeding his science, a profound religious sentiment enhanced it.
Just as it did for William Harvey, who first described the circulation of blood. And Francis Bacon as he developed the modern scientific method. And Robert Boyle when he refined experimental methods. And countless scientists throughout history who were motivated to study nature because of—not despite—their faith.
Why do we see this sort of entangling of science and religion throughout human history and continue to see it today? The Penultimate Curiosity, by the artist Roger Wagner and Oxford scientist Andrew Briggs, aims to answer this question.
Humans, according to Wagner and Briggs, have always tended to “explorations and engagements with the natural world.” Even prehistoric hunter-gather tribes may have participated. Remains from an 11,000-year-old fishing village in Equatorial Africa suggest its inhabitants may have been tracking the lunar cycle. At the very least, the carefully imprinted grooves on a piece of bone imply an external memory system. “The penultimate curiosity” refers to this insatiable desire to study and understand the physical world. Modern science is the culmination of thousands of years of people following their penultimate curiosity.
But note that as important as science is, Wagner and Briggs deem it our penultimate—that is, second-most important—curiosity. Why does it not qualify as number one? Well, it turns out that many of our scientific investigations were ultimately motivated by a “strong religious impulse.” Referencing scholarship from anthropology and archeology, Wagner and Briggs conclude that “almost all human societies have organized themselves around stories and practices which in different ways focus attention on something beyond the horizon of the visible world.” This religious dimension influences almost everything that humans do. The curiosity that led to science thus overlaps with and is ultimately derived from the type of curiosity that led to religion.
Wagner and Briggs analogize this interaction to a slipstream, where an object can move more easily if it travels behind something else. Think of a small child following a parent on a windy day, fish swimming in a school, or cyclists traveling in a peloton: those behind the lead can move at the same speed while expending less energy.
So it is with science and religion. The earliest human societies devoted energy to what we would now call religion. Prehistoric art focused on ritual functions and early human writing addressed creation stories. These ultimate curiosities pulled exploration of the physical world into their slipstream: ancient paintings, though primarily devoted to ritual, also recorded close observations of animal anatomy. In places as diverse as China, India, South America, and the Middle East, we have evidence of people studying physical phenomena alongside and because of their ultimate curiosity. To “make sense of the world as a whole” required us to entangle our study of the natural world with our supernatural concerns. In many cases, science benefited most when it closely followed humans’ ultimate curiosity.
Consider the ancient Greek city of Ionia, which flourished around 500 BCE. Ionians strongly believed that a divine source ordered and steered the universe. This conviction led the philosopher Anaxagoras to study “the sun and the moon and the heavens.” When subsequent Greek astronomers proved that planetary motion could be predicted by mathematics, they confirmed the religious belief that the world was “formed on a rational design.” Plato himself insisted that religious understanding, ethics, and science should form an integrated intellectual enterprise. His dialogue, Timaeus, pictured the “maker and father of the universe” as a geometer and presented an argument that God’s existence is an eikoslogos—a likely account.
Fast-forward about 1,100 years and consider the Islamic empires. The Koran instructs Muslims on when they should pray and which direction to face when doing so. The injunction to point to Mecca required Muslim astronomers to solve difficult geometric problems and make accurate astronomical observations. Before the existence of clocks, the command of five daily prayers also resulted in advances in astronomy and mathematics. This idea that we should study science for the sake of God permeated the work of some of the greatest Islamic scientists. Ibn al-Haytham, whose study of optics helped establish the importance of systematic experiments in science, believed there was “no better way [to get close to God] than searching for knowledge and truth.”
Early Western scientists followed a similar script. Despite his image as a champion of secular reason, Galileo Galilei believed “divine grace” helped him “philosophize better,” and that the “love of the divine Artificer” was the “ultimate end of [his] labors.” Isaac Newton studied physics to “glorify God in his wonderful works to teach man to live well.” Roger Bacon, Nicholas Copernicus, Johannes Kepler, and James Clerk Maxwell also blended their science and faith to the benefit of us all.
Wagner and Briggs believe that the existence of such examples across cultures and throughout history proves that humans have a need to address both our spiritual and worldly concerns. This need forms a core part of the human experience. The yearning to “make sense of the world as a whole” implies that science and faith will always be entangled in some way. The penultimate curiosity will thus continue to swim in the slipstream of ultimate questions.
The authors have amassed a staggeringly diverse body of scholarship to show that almost all human societies have mixed the ultimate and penultimate curiosities. Unfortunately, the volume of information they present is often distracting and does not connect to their central thesis. In a mere five-page stretch, for example, Wagner and Briggs introduce the reader to Plato’s disciple Xenophon, the ancient Christian Justin Martyr, the mathematicians Archytas and Eudoxos, the philosopher Simplicius, and the writer Sosigenes. In addition to this eclectic cast, these same pages also discuss Socrates and The Republic.
Similarly, Wagner and Briggs spend too much ink on involved descriptions of specific scientific developments that do not always connect to their main topic. Though James Clerk Maxwell’s discoveries are fascinating, Wagner and Briggs did not have to detail the particular mathematical and experimental techniques he used.
The book would have been strengthened considerably with less content: The Penultimate Curiosity is filled with too many historical vignettes that could have been eliminated. If the authors themselves say that several chapters can be skipped, perhaps that’s a sign they should not have been included in the first place. Instead of a better understanding of the entanglements between science and religion, their approach can leave readers feeling overwhelmed by the breadth of knowledge and number of historical figures introduced.
Despite these shortcomings, Wagner and Briggs should be commended for the key observation that science and religion are entangled ultimately because human beings themselves are entangled. To reiterate their elegant phrasing, making “sense of the world as a whole” often requires people to mix their spiritual and earthly concerns. Although Wagner and Briggs are not the first to note how many scientists were motivated by faith, and the book is bogged down by many tangential ideas and facts, the sheer breadth of their evidence powerfully demonstrates how universal this sentiment is. It is a fundamental part of our humanity.
The Thrill of Discovery
During my first year of college, my organic chemistry professor assigned us Anda Brivin’s book Gun Down the Young, a slim fictional account of professional academic life at an unnamed university. I suspect that she did so because she knew that many of her students were envisioning careers at top-tier research universities and she hoped to cure us of some of our more romantic fantasies of life as academics. Although the book did, indeed, provide some much-needed levity in an otherwise grueling course, Hope Jahren’s Lab Girl might serve future students as a better introduction to the real stories of the ivory tower.
Early in Lab Girl, Jahren recounts late winter evening visits to her father’s laboratory at a community college in rural Minnesota, where she “transformed from a girl into a scientist, just like Peter Parker becoming Spider-Man, only kind of backward.” The rest of the book serves as a reflection on that transformation, an exploration of the forces that drove—and hindered—Jahren’s journey from frosty Minnesota to California, Georgia, Maryland, and Hawaii.
This journey is not often recounted. Scientists from every discipline will recognize Jahren’s lament about the necessity of “distilling ten years of work by five people into six published pages, written in a language that very few people can read and that no one ever speaks.” There is no doubt that Jahren is very, very good at this distillation: among her honors are three Fulbright awards; Young Scientist awards from both the American Geophysical Union and Geological Society of America; and recognition by Popular Science and Time as an influential scientist. But as she tells the reader, “there’s still no journal where I can tell the story of how my science is done with both the heart and the hands.” And so she has given readers Lab Girl, and we are all luckier for it.
Heart drives Jahren’s narrative, an unbounded love of and curiosity about the natural world. She interweaves her story of becoming a geobiologist with stories of how tiny seeds struggle to become (or, more frequently, fail to become) seedlings, then saplings, then towering trees. Jahren uses these passages to inspire a sense of wonder, to illustrate that discovery and mischief are two sides of the same science coin, and to spur readers to ask questions and become a scientist. And once we grow to love the plants that Jahren loves, she breaks our hearts, lamenting the reduction of plants to commodities and the rapid pace of deforestation (“One France after another, for decades, has been wiped from the globe”), and in the epilogue concluding that her “job is about making sure there will be some evidence that someone cared about the great tragedy that unfolded during our age.”
In this regard, Jahren is following in the footsteps of other scientists who have found popular success with their writing. Like biologist and author E. O. Wilson, she steps beyond the confines of journals and textbooks, drawing on her experience as a researcher and the work of colleagues to highlight the present environmental crisis. Jahren has a light touch when it comes to the hotly debated issue of where the lines between science, policy advice, and advocacy lie; whether and how scientists might cross those lines; and if by crossing those lines scientists risk their credibility. She focuses on what individuals might do, for example, to replace trees in their own communities, rather than suggesting broader policy change. By focusing on what each reader can do, she overcomes a common critique of scientific reports chronicling environmental problems: that after delivering gloomy results, they do nothing to suggest productive actions, especially responses at the household level.
More than an ode to the natural world, though, Lab Girl is a story of the heights and heartbreak of the practice of science, cataloging the workaday life of a scientist on the path from student to assistant professor to tenured faculty. Jahren’s story is full of reasons why she loves science: the satisfaction of attacking problems (“in science classes we did things instead of just sitting around talking about things”), the thrill of discovery (“the overwhelming sweetness of briefly holding a small secret the universe had earmarked just for me”), and the many ways in which her laboratory is her true home. Most of the chapters illustrate these reasons with anecdotes from Jahren’s research career—using exploding glassware, police visits to impromptu fieldwork campsites, lost and ruined samples, experiments that failed to bear fruit, and late-night breakthroughs in isotope chemistry—to fight back against the “disrespectful amnesia” that removes the practice of science from most research reports.
These are the sort of tales that scientists share over pints of beer or plates of food. But as Jahren points out, that sharing is often limited to specific audiences (generally scientists of the same generation, race, and gender), and so she has often “stood alone [at a conference or seminar] … apparently radiating cooties and so excluded from the back-slapping stories of building mass spectrometers during the good old days.” Such storytelling serves a greater purpose than catching up with old friends; it is a lifeline for young scientists who otherwise might fall victim to imposter syndrome, believing that a failed experiment validates their internal doubts about their abilities as a scientist. These stories provide a context for failure by acknowledging that, as Jahren put it, “if there had been a way to get to success without traveling through disaster someone would have already done it and thus rendered the experiments unnecessary.” By excluding graduate students, female scientists, and other minority groups from storytelling, the larger community of scientists does a disservice to the future of the scientific workforce. A growing number of fieldwork blogs, discussions about imposter syndrome and failure at scientific conferences, and books like Lab Girl are helping make those stories more accessible.
Perhaps the least visible (to the public) but most pressing task of an academic scientist is the pursuit of funding. According to Jahren, “I need to do about four wonderful and previously impossible things every year until I fall into the grave in order for the university to break even on me.” And that’s before the cost of lab supplies, paper, and staff. Chasing federal and private grants, and the stagnant or decreasing amounts available from these sources, is a task that Jahren discusses at length. She walks readers through the intricacies of university overhead rates, the budgets of the National Science Foundation and the Department of Homeland Security, and the overabundance of PhD scientists compared with available money. For academic scientists who are all too familiar with the current low success rate of their grant proposals, this discussion will result in either a lot of head nodding or cries of agony from something akin to post-traumatic stress. For non-scientist readers, the discussion will provide a window into what scientists do after the rest of the world has gone to bed. The readers who stand to gain the most from these sections, however, are those who aspire to join the ranks of academia. Like the tales of success and failure in the lab, these stories of 3:00 a.m. grant writing, pinching pennies until the next payment arrives, and not being able to pay staff enough are tales that need to be told.
Jahren’s lab manager, Bill Hagopian, is a central character in Lab Girl. Their scientific partnership began when Jahren was an assistant instructor for a field course in which Hagopian was a student. “I didn’t so much meet Bill. It was more like I identified him,” she says of that fateful day. Their working relationship and friendship is explored from many angles, with Jahren as the one to “cook up a pipe dream” and Hagopian as the one in charge of prototyping and mechanics; Jahren as the lumper and Hagopian as the splitter when it comes to soil classification; Hagopian as the patient teacher long after Jahren has grown frustrated with a student who is progressing slowly. In the end, Lab Girl stands as a testament to the fruitfulness of that collaboration. Yet Jahren notes that the hiring and funding structures at universities that have granted her tenure and provided at least several months of her salary have denied Hagopian the same long-term job security, something she feels guilty about because she is the one who brought him into the lab in the first place.
Lab Girl arose from Jahren’s need to tell the secrets of science to someone, not as advice or caution, but as “one scientist to another.” She does not aim to synthesize all that she knows on one topic or another, or find deeper thematic threads. Instead, she conveys the way in which she “will never stop being ravenously hungry for science” regardless of the obstacles and bureaucracy she finds along the way. In pulling back the curtain on what lies at the heart of science, she challenges readers to find their own passions and to pursue them relentlessly.
 This book was very difficult to review. In Ordinarily Well: The Case for Antidepressants, Peter Kramer, a psychiatrist and best-selling author, makes two arguments with which I agree. One is that clinical observation—the interaction by which a medical professional learns about a patient—counts for something. The other is that clinical trials, or evidence-based medicine more generally, are not a replacement for clinical wisdom. He values antidepressants, in particular the selective serotonin reuptake inhibitor (SSRI) class of drugs, and so do I, based on my own medical experience.
This book was very difficult to review. In Ordinarily Well: The Case for Antidepressants, Peter Kramer, a psychiatrist and best-selling author, makes two arguments with which I agree. One is that clinical observation—the interaction by which a medical professional learns about a patient—counts for something. The other is that clinical trials, or evidence-based medicine more generally, are not a replacement for clinical wisdom. He values antidepressants, in particular the selective serotonin reuptake inhibitor (SSRI) class of drugs, and so do I, based on my own medical experience. On the one hand, the world is obviously a much better place than it used to be.
On the one hand, the world is obviously a much better place than it used to be. Climate policy makers and political leaders love global targets. By adopting climate stabilization goals to limit temperature increases to a specified amount—usually two degrees Celsius
Climate policy makers and political leaders love global targets. By adopting climate stabilization goals to limit temperature increases to a specified amount—usually two degrees Celsius 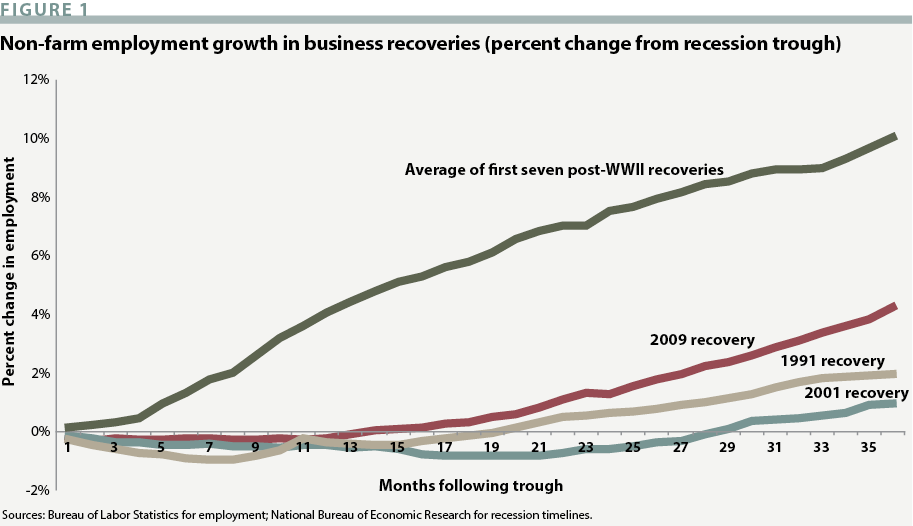
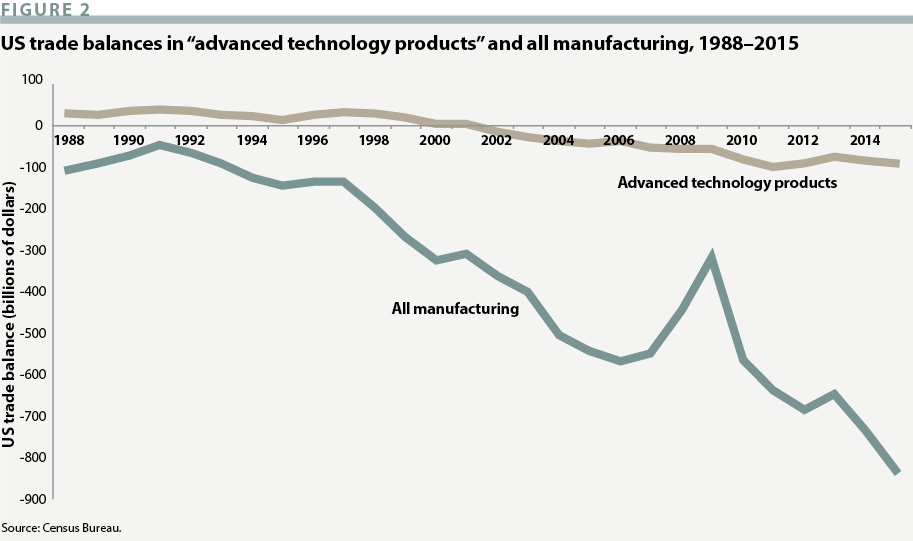
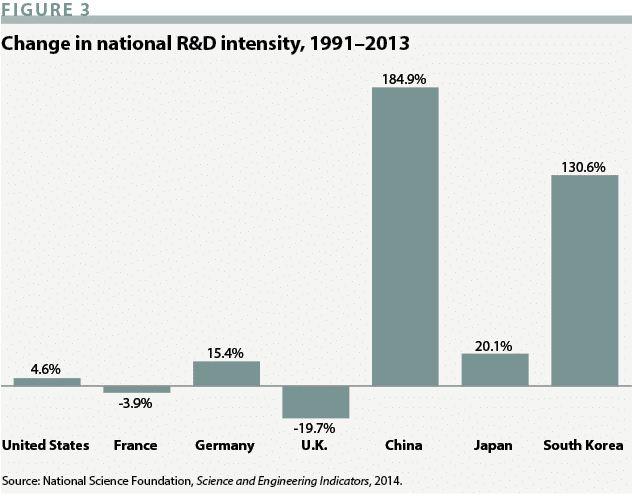
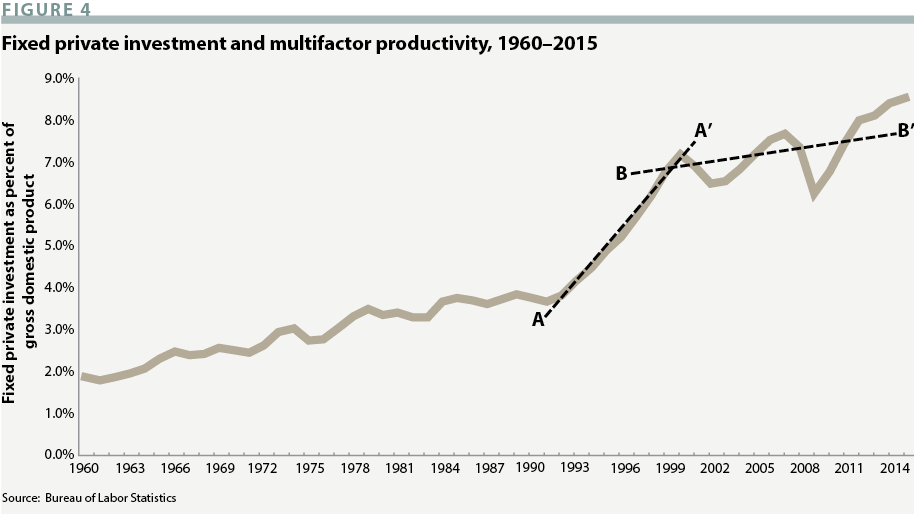
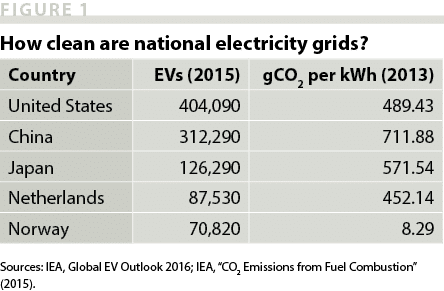

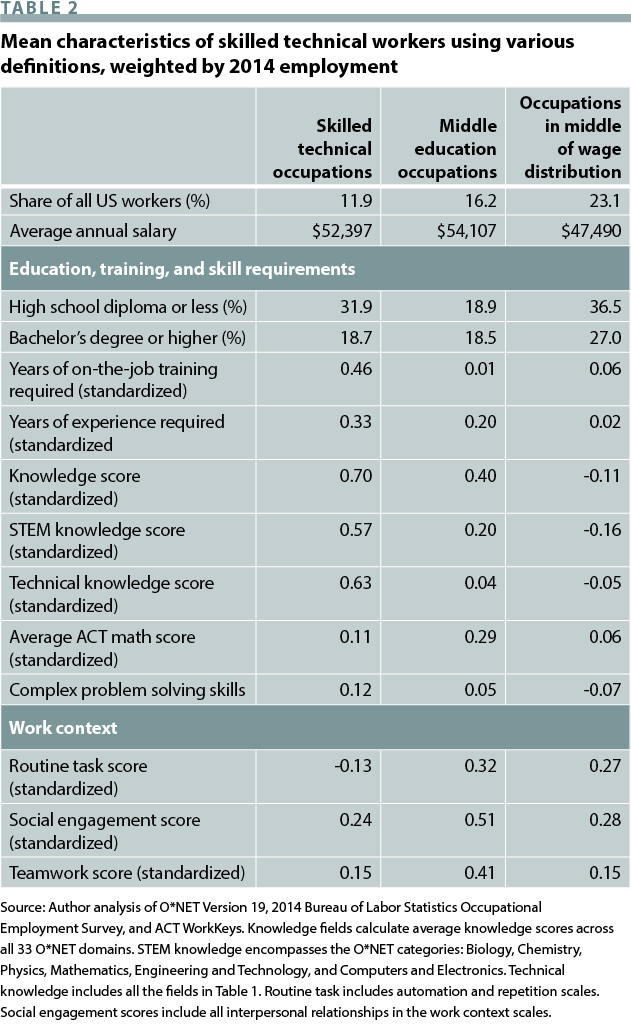
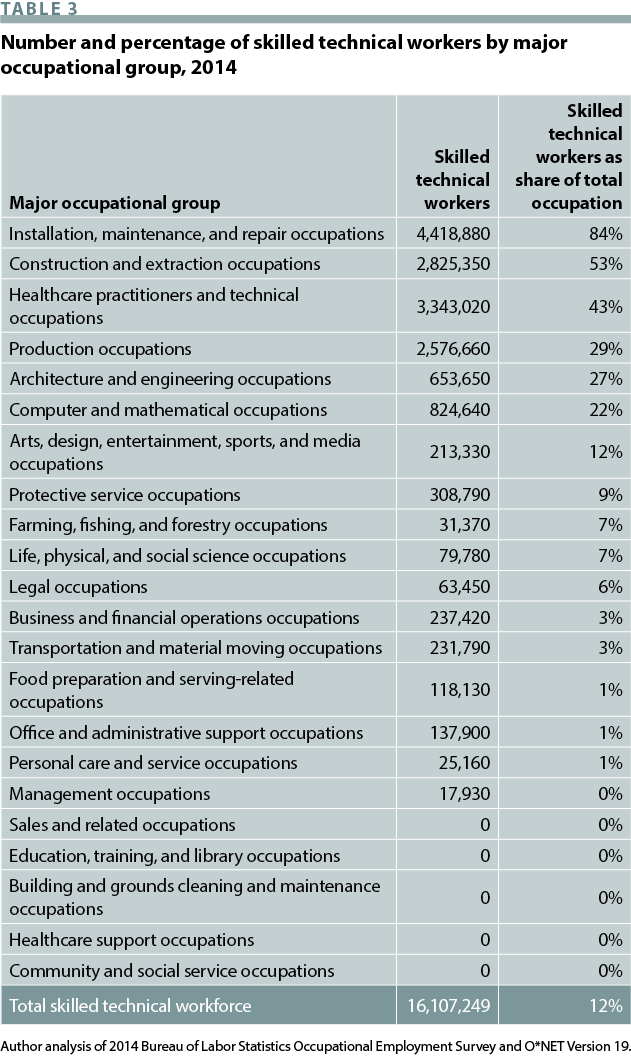
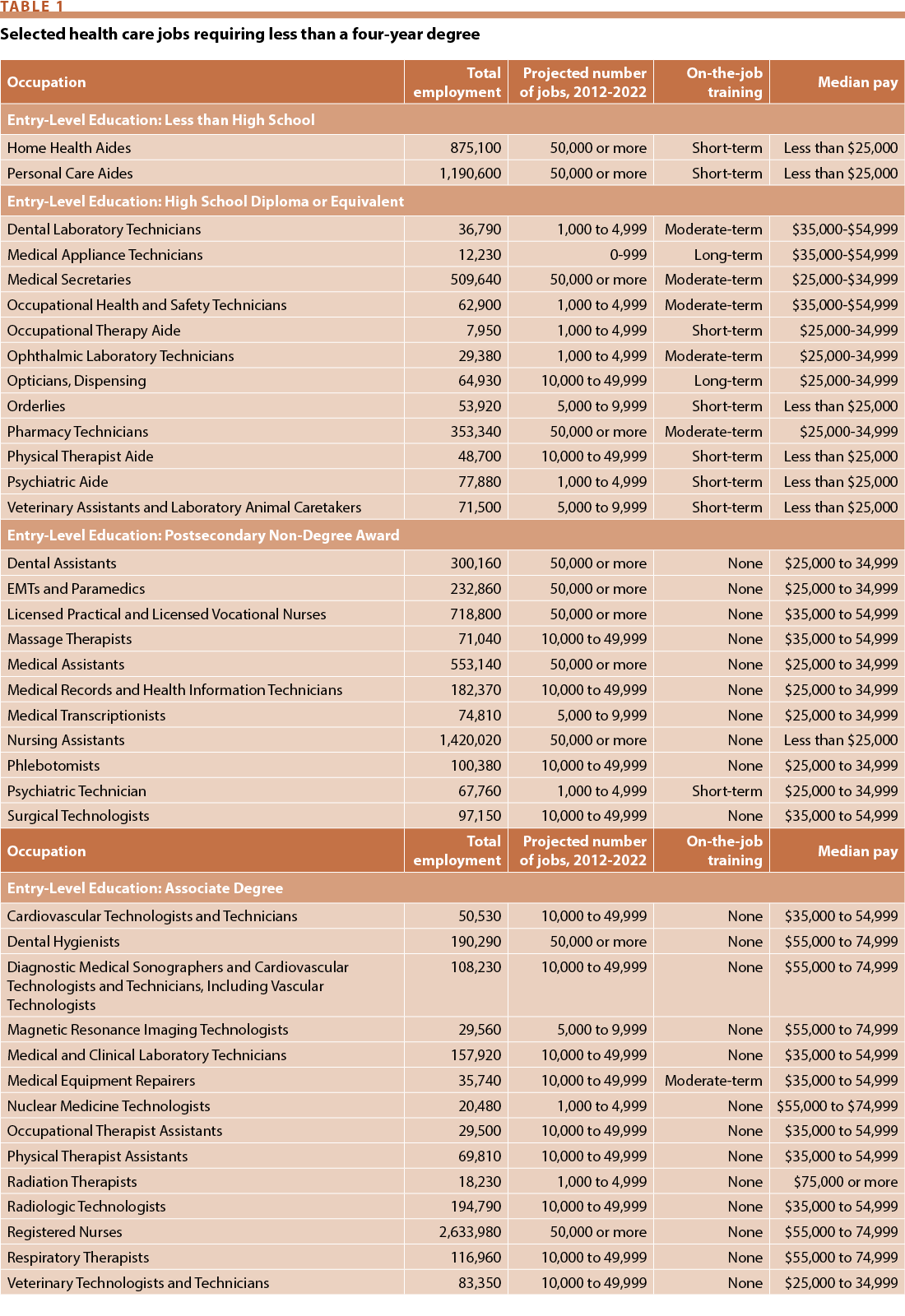
 Imagine the scene: you’re Everett Dolman, a faculty member at the US Air Force’s School of Advanced Air and Space Studies with significant security and military experience, and an eager publisher suggests the book title of Can Science End War? What do you do with such a naïve suggestion?
Imagine the scene: you’re Everett Dolman, a faculty member at the US Air Force’s School of Advanced Air and Space Studies with significant security and military experience, and an eager publisher suggests the book title of Can Science End War? What do you do with such a naïve suggestion?
